concepts阅读总结6——视图和索引
来源:互联网 发布:淘宝皮鲁sigma是真货么 编辑:程序博客网 时间:2024/04/29 20:21
1、视图:
视图不会要求分配空间,他只有一个查询语句即为他的定义,存储在数据字典中。当用户在sql语句中引用了视图时,oracle将进行入下工作:
1、将引用视图的语句与视图定义语句整合为一条sql语句。
2、在共享SQL区对这条语句进行解析。
3、执行解析好的语句。
下面看看oracle是如何整合查询一条语句的:
例如有以下视图:
CREATE VIEW employees_view AS用户提交了以下查询:
SELECT employee_id, last_name, salary, location_id
FROM employees JOIN departments USING (department_id)
WHERE departments.department_id = 10;
SELECT last_name用户提交的查询经 Oracle 整合(merge),转化(transform)后的最终结果为:
FROM employees_view
WHERE employee_id = 9876;
SELECT last_nameOracle 会尽可能地将用户查询及其中所引用视图的定义查询(可能还包括视图所引用的其他视图)进行整合。Oracle 将优化整合后的语句,就如同用户提交的语句中没有引用视图一样。因此,无论一列是被视图的定义引用,还是被用户提交的查询引用,Oracle 都可以使用建于基表列(base table column)上的索引。
FROM employees, departments
WHERE employees.department_id = departments.department_id AND
departments.department_id = 10 AND
employees.employee_id = 9876;
物化视图:
关于物化视图的详细介绍参照我的博客:http://blog.csdn.net/changyanmanman/article/details/8029422
物化视图(materialized view)是一种可以用于汇总(summarize),计算(compute),复制(replicate),及发布(distribute )数据的方案对象(schema object)。她适用于数据仓库(data warehouse),决策支持(decision support),分布式计算(distributed),及移动(mobile)计算等多种环境:
我理解的物化视图是一个基于查询结果的对象,他是远程数据库的本地副本,物化视图的存储基于远程表的数据。。。
通常情况下,物化视图被称为主表(在复制期间)或明细表(在数据仓库中)。
对于复制,物化视图允许你在本地维护远程的数据副本,这些副本都是只读的,如果你想复制本地副本,必须用高级复制功能,当你想从一个表或者一个视图中抽取数据的时候,你就可以从本地的物化视图中抽取。
对于数据仓库,创建的物化视图通常情况下是聚合视图,单一表聚合视图和连接视图。
- 在数据仓库中,物化视图常被用于计算和存储聚合数据(aggregated data),例如汇总(sum),平均(averages)等。在数据仓库环境中,物化视图也被称为概要(summaries),因为 其中通常存储的是汇总数据(summarized data)。用户也可以使用物化视图存储多个表连接后的结果集(compute join)。如果数据库的兼容性参数被设为 Oracle9i 或更高,物化视图的查询中可以包含过滤选择(filter selection)
优化器(optimizer)可以利用物化视图来提升查询性能。优化器能够自动地判断一个存储汇总数据的物化视图是否能满足用户的查询要求,以及使用此物化视图是否能提高查询性能。之后优化器能够重写(rewrite)用户提交的查询以便使用相应的物化视图,而这个重写过程对用户是透明的。此时查询直接使用物化视图,而非用户提交的 SQL 语句中指定的明细数据表或视图。 - 在分布式环境中,用户可以使用物化视图提供的功能在各个分布的节点(distributed site)间复制数据, 同步(synchronize)各个节点的数据修改,并在发生冲突时进行处理。利用物化视图的复制能力,用户可以将原本必须从远程节点(remote site)访问的数据移动到本地节点(local site),实现本地访问。
- 在移动计算环境中,移动客户端(mobile client)可以使用物化视图从中央服务器(central server)下载一个数据的子集(subset),还可以定期地从中央服务器取得最新数据,并将移动客户端的数据修改发送回中央服务器。
- 物化视图需要占用存储空间。
- 当其主表(master table)内的数据发生变化时,物化视图需要刷新
- 当查询重写(query rewrite)使用物化视图时,能够提升 SQL 语句的执行效率
- 物化视图对提交 SQL 的用户和应用程序是透明的
一个数据块(data block)内可用于存储索引数据的空间等于数据块容量减去数据块管理开销(overhead),索引条目管理开销(entry overhead),rowid,及记录每个索引值长度的 1 字节(byte)。
oracle创建索引时,oracle取得所有被索引的列的数据进行排序,排序后将索引列对应的rowid按照刚才牌号的顺序依次加到索引中,如下面一句话:
CREATE INDEX employees_last_name ON employees(last_name);
racle 先将 employees 表按 last_name 列排序,再将排序后的 列及相应的 rowid 按从下到上的顺序加载到索引中。使用此索引时,Oracle 可以快速地搜索已排序的last_name 值,并使用相应的 rowid 去定位包含用户所查找的 last_name 值的数据行。
对于唯一索引(unique index),每个索引值对应着唯一的一个 rowid。对于非唯一索引(nonunique index),每个索引值对应着多个已排序的 rowid。因此在非唯一索引中,索引数据是按照索引键(index key)及 rowid 共同排序的。键值(key value)全部为NULL 的行不会被索引,只有簇索引(cluster index)例外。在数据表中,如果两个数据行的全部键值都为 NULL,也不会与唯一索引相冲突。
索引的键压缩:
一般来说,索引的一个键(key)通常由两个片段(piece)构成:分组片段(grouping piece)及唯一片段(unique piece)。如果定义索引的键中不存在唯一片段,Oracle 会以 ROWID 的形式在此键的分组片段后添加一个唯一片段。键压缩(key compression)就是将键的分组片段从键中拆分出来单独存储,供多个唯一片段使用。
键压缩(key compression)能够节约大量存储空间,因此用户可以在一个索引块(index block)内存储更多的索引键(index key),从而减少 I/O,提高性能。
键压缩(key compression)能够减少索引所需的存储空间,但索引扫描时需要重构(reconstruct)键值(key value),因此增加了 CPU 的负担。此外键压缩也会带来一些存储开销,每个前缀(prefix entry)需要 4 字节(byte)的管理开销。
使用键压缩:
键压缩(key compression)在多种情况下都能够发挥作用,例如:
- 对于非唯一索引(nonunique index),Oracle 会在每个重复的索引键(index key)之后添加 rowid 以便区分。如果使用了键压缩,在一个索引块(index block)内,Oracle 只需将重复的索引键作为前缀((prefix entry))存储一次,并用各行的 rowid 作为后缀(suffix entry)。
- 唯一索引(nonunique index)中也存在相同的情况。例如唯一索引(stock_ticker,transaction_time)的含义是(项目,时间戳),通常数千条记录中 stock_ticker 的值是相同的,但她们对应的 transaction_time 值各不相同。使用了键压缩后,一个索引块中每个 stock_ticker 值作为前缀只需存储一次,而各个 transaction_time 值则作为后缀存储,并引用一个共享的 stock_ticker 前缀。
- 在一个包含 VARRAY 或 NESTED TABLE 数据类型(datatype)的索引表(index-organized table)中,这些collection 类型中各个元素(element)的对象标识符(object identifier)是重复的。用户可以使用键压缩以避免重复存储这些对象标识符。
位图索引:
在位图索引中,只需存储每个键值的位图,而非一组ROWID。 在位图中,每一位(bit)对应一个可能的rowid,如果某一位被 置位(set),那就说明这位对应的ROWID所指向的行中,包含此位所代表的键值。oracle通过一个映射函数将位图信息转化为实际的rowid。
因此虽然位图索引(bitmap index)内部的存储结构与常规索引不同,但她同样能实现常规索引的功能。当不同值的索引键的数量较少时,位图索引的存储效率相当高。
如果在 WHERE 子句内引用的多个列上都建有位图索引(bitmap index),那么进行位图索引扫描时(bitmap indexing)可以将各个位图索引融合在一起。不满足全部条件的行可以被预先过滤掉。因此使用位图索引能够极大地提高查询的响应时间。
数据仓库应用中位图索引的优势
数据仓库应用(data warehousing application)的特点是数据量巨大,执行的多为自定义查询(ad hoc query),且并发事务较少。这种环境下使用位图索引(bitmap index)具备如下优势:- 能够减少大数据量自定义查询的响应时间
- 与其他索引技术相比能够节省大量存储空间
- 即使硬件配置较低也能显著提高性能
- 有利于并行 DML 和并行加载
位图索引(bitmap index)不适用于 OLTP 系统,因为这样的系统中存在大量对数据进行修改的并发事务。位图索引主要用于数据仓库系统中(data warehousing)的决策支持功能,在这种环境下用户对数据的操作主要是查询而非修改。
主要进行大于(greater than)或小于(less than)比较的列,不适宜使用位图索引(bitmap index)。例如,WHERE 子句中常会将 salary 列和一个值进行比较,此时更适合使用平衡树索引(B-tree index)。位图索引适用于等值查询,尤其是存在 AND,OR,和 NOT 等逻辑操作符的组合时。
位图索引(bitmap index)是集成在 Oracle 的优化器(optimizer)和执行引擎(execution engine)之中的。位图索引也能够和 Oracle 中的其他执行方法(execution method)无缝地组合。例如,优化器可以在利用一个表的位图索引和另一个表的平衡树索引(B-tree index)对这两张表进行哈希连接(hash join)。优化器能够在位图索引及其他可用的访问方法(例如常规的平衡树索引,或全表扫描(full table scan))中选择效率最高的方式,同时考虑是否适合使用并行执行。
位图索引(bitmap index)如同常规索引一样,可以结合并行查询(parallel query)和并行 DML(parallel DML)一起工作。建立于分区表(partitioned table)的位图索引必须为本地索引(local index)。Oracle 还支持并行地创建位图索引,以及创建复合位图索引。
基数(某一列中值不重复的个数)
我的理解:对于位图来说,基数越小越好,(就是说希望重复值很多,越多越好啊)所谓某列的基数小(low cardinality)是指此列中所有不相同的值的个数要小于总行数。如果某列中所有不相同的值的个数占总行数的比例小于 1%,或某列中值的重复数量在 100 个以上,那么就可以考虑在此列上建立位图索引。即便某列的基数较上述标准稍大,或值的重复数量较上述标准稍小,如果在一个查询的 WHERE 子句中需要引用此列定义复杂的条件,也可以考虑在此列上建立位图索引。
例如,一个表包含一百万行数据,其中的一列包含一万个不相同的值,就可以考虑在此列上创建位图索引(bitmap index)。此列上位图索引的查询性能将超过平衡树索引(B-tree index),当此列与其他列作为组合条件时效果尤为明显。
来,看下面这个位图索引的例子:
一个公司部分的客户数据:

婚姻状况,地区,性别,和收入水平都是小基数(low-cardinality)的列。婚姻状况及地区有 3 种可能值,性别有两种,收入水平有 4 种。因此这 4 列上均适合创建位图索引(bitmap index)。而客户编号列上不应创建位图索引,因为此列基数很大。在此列上创建平衡树索引(B-tree index)的存储和查询效率会较高。
在上表的地区列上建立的位图索引(bitmap index)。此索引由 3 个独立的位图组成,每个位图代表一个地区。
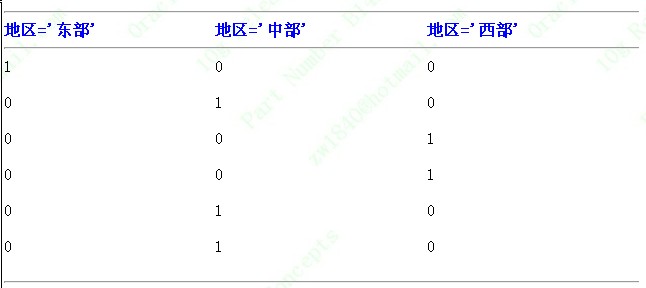
位图(bitmap)中的每一位(bit)都对应 CUSTOMER 表中的一行。每一位的值由每行中对应字段的值决定。例如,位图 地区='东部' 的第一位为 1,这是因为 CUSTOMER 表中第一行的地区字段的值为东部。此位图其他位均为 0,因为此表其他行的地区字段的值都不为东部。
一个业务分析员在统计公司客户的地区分布趋势时,需要知道“住在中部或西部地区的已婚客户有多少?”。这个问题对应以下 SQL 语句:
SELECT COUNT(*) FROM CUSTOMER使用位图索引(bitmap index)处理此查询时,通过布尔运算(Boolean operation)很容易得到一个位图结果集(resulting bitmap),如 图5-8 所示。利用此结果集访问表,就可以得到满足查询条件的客户信息。
WHERE MARITAL_STATUS = 'married' AND REGION IN ('central','west');
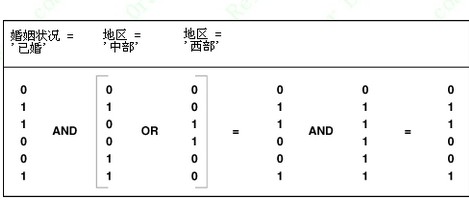
图5-8 显示了三个位图。这三个位图之间的布尔运算如下:婚姻状况='已婚' AND (地区='中部' OR 地区='西部')。
与其他大多数索引不同,位图索引(bitmap index)可以包含键值(key value)为 NULL的行。将键值为空的行进行索引对有些 SQL 语句是有用处的,例如包含 COUNT 聚合函数的查询。
索引组织表的二次索引:
http://blog.csdn.net/changyanmanman/article/details/7326505
- concepts阅读总结6——视图和索引
- concepts 阅读总结1——体系结构
- concepts 阅读总结2——存储
- concepts阅读总结3——文件
- concepts阅读总结4——事务
- concepts阅读总结9——数据仓库
- concepts阅读总结10——分区
- concepts阅读总结4——事务
- concepts阅读总结5——堆表
- concepts阅读总结7——数据字典
- concepts阅读总结8——内存结构补充+oracle工具+个别进程
- concepts阅读总结11 ——数据库安全与数据完整性
- sqlite 视图、触发器、索引和事务总结
- sqlite 视图、触发器、索引和事务总结
- 视图索引总结
- Sql Hacks 阅读感悟——连接、联合和视图
- 视图性能优化——索引视图
- 索引、视图、游标、存储过程和触发器理解总结
- PHP模板Smarty 初级学习 重点是:配置项的说明
- android 动画2
- Eclipse(Windowns XP)下搭建Android开发环境——简介
- ubuntu下安装飞信
- ADO.NET Entity Framework 之“无法加载指定的元数据资源。”
- concepts阅读总结6——视图和索引
- [我的Linux技术支持生涯] 网卡无法激活问题的排查
- C#调用Oracle存储过程的方法
- 第二章 指针操作
- 类型和类的区别
- JSON与JAVA的数据转换
- AWS使用小记之EC2(Elastic Compute Cloud)
- 检测括号是否配对
- 在VC下执行DOS命令并得到输出(转)


