并行博弈树搜索算法-第6篇 百花齐放:各种并行Alpha-Beta算法
来源:互联网 发布:lg照片打印机的软件 编辑:程序博客网 时间:2024/04/30 16:03
下面开始介绍一些在Alpha-Beta算法中引入并行化的方法和算法.
6.1 并行求值(Parallel Evaluation)
游戏的博弈程序经常要在搜索深度和叶结点的求值复杂度之间进行平衡.一些博弈程序,使用简化的估值函数,以获得更深的搜索深度.但是花费在对叶结点的求值中的时间仍然占搜索时间的很大一部分.一个在博弈树搜索中应用并行性的思想[6]就是将求职函数设计得较为复杂,并将它划分到多个处理器中并行计算,然后综合各部分结果,得到最终的估值.
6.2 并行吸出(Parallel Aspiration)
并行吸出(Parallel Aspiration)或者窗口分裂(Window Spittting)搜索[13]基于这样的思想:如果将搜索窗口设置为一个小的区间,如果最大最小值处于这个小的区间中,那么就可以在搜索较少的叶结点的情况下得到最大最小值.
在并行吸出搜索中,初始搜索窗口[-∞, +∞]被划分成p个不相交的区间.其中p为处理器的个数.每个处理器以分配给它们的区间作为搜索窗口,使用Alpha-Beta算法并行地搜索同一棵博弈树.由于这些搜索窗口覆盖了初始窗口[-∞, +∞],所以总有一个处理器可以搜索到正确的最大最小值.当这个正确的最大最小值被一个处理器搜索到之后,所有其他的处理器就立即停止搜索.
实验表明[6],在一些情况下,当处理器个数p较少时(例如,p为2或3),这种算法可以获得超过p倍的加速,但是,算法能获得的最大加速却非常有限,并且与处理器个数的多少无关.
6.3 Tree Splitting 算法
在Tree Splitting 算法中,处理器同过通信线(communicationline)以树形结构组织起来,形成一棵处理器树(processor tree).处理器树的结点对应一个处理器,结点之间的连线对应于通信线.处理器树中的每个内部处结点都有若干子结点,这些子结点均为父结点的子处理器(child processor).没有子结点的处理器称为叶处理器(leaf processor),否则称为主处理器(master).叶处理器执行串行的Alpha-Beta算法,也就是从算法(slavealgorithm),而主处理器均执行主算法(master algorithm).
在Tree Splitting 算法开始后,博弈树的根结点由给处理器树的根结点处理.该根处理器产生博弈树的根结点的所有移动,并将这些子结点交给它的子处理器处理.父处理器总是把自身负责的结点的子结点交给其子处理器处理,如此继续,直到一个结点的搜索被分配给处理器树中的叶结点.叶处理器执行串行Alpha-Beta算法,并将结果提交给其父处理器.内部结点接收其子处理器提交的博弈值,并判断是否能据此改变搜索窗口的alpha值,如果可以,它将中断所有子处理器的搜索,并强迫所有子孙处理器更新搜索窗口.当内部结点接收到所有子处理器提交的博弈值之后,就计算最佳的博弈值并提交给父处理器.最后,就可以在根处理器里得到博弈树的最大最小值.
一个Tree Splitting 算法的伪代码如下所示[6]:
TreeSplit(node, alpha, beta)1: if(I am a leaf processor) then2: return(AlphaBeta(node, alpha, beta))3: fori ← 1 to node.branch.length par-do4: while(a slave j is idle) do5: new_node ← Traverse(node,node.branch[i])6: value[i] ← -j.Treesplit(new_node,-beta, -alpha)7: critical begin8: if value[i] > alpha then9: alpha ← value[i]10: critical end11: if alpha ≥ beta then12: Terminate()13: return alpha14: returnalphaUpdate(depth, side, bound)1: if(side > 0) then2: alpha[depth] ← Max(alpha[depth],bound)3: else4: beta[depth] ← Min(beta[depth],bound)5: ifdepth > 0 then6: Update(depth-1, -side,-bound)上述伪代码中,Update()函数就是进行搜索窗口更新的函数.par-do指的是并行地执行for循环中的代码.j.Treesplit()指的是在传递参数给空闲处理器j,在j中执行Treesplit()函数,并将处理结果返回到当前处理器.
主处理器在等待其子处理器搜索完成时处于空闲状态,为了利用这段空闲时间,Tree Splitting 算法可以引入如下的改进:
1.在空闲时,主处理器执行从算法,搜索那些由于找不到空闲子处理器而没有被搜索的子树.
2.主处理负责博弈树中的多层结点,以减少空闲时间.
3.主处理可以将一个子结点的所有子结点都分配给一个子处理器,这不仅减少了子处理器的空闲时间,而且能使得alpha值和beta值的共享更方便.
在Tree Splitting算法中,只有离根结点的深度少于k的结点才能并行搜素.其中k为处理器树的深度.由于在一个最好或者较好的移动找到前,可能大量无用的搜索已经并行完成了,所以算法的搜索开销比较大.
6.4 PVSplit算法
主变量分裂(Principal Variation Splitting,简称PVSplit)算法是对Tree Splitting算法的一种改进.它的基本思想是,直到最左路径搜索完成之后,才进行博弈树树的分裂(tree decomposition),开始并行搜索.与TreeSplitting算法一样,PVSplit算法也使用处理器树的方式来管理处理器,分配对博弈树的搜索.
一个PVSplit算法的伪代码如下所示[6]:
PVSplit(node, alpha, beta)1: if(node.depth = 0) then2: return(TreeSplit(p,alpha, beta))3: new_node ← Traverse(node,node.branch[1])4: alpha ← -PVSplit(new_node,-beta, -alpha)5: ifalpha ≥ betathen6: returnalpha7: fori ← 2 to node.branch.length par-do8: while(a slave j is idle) do9: new_node ← Traverse(node,node.branch[i])10: value[i] ← -j.TreeSplit(new_node,-beta, -alpha)11: critical begin12: if (value[i] > alpha) then13: alpha ← value[i]14: critical end15: if (alpha ≥ beta) then16: Terminate()17: return alpha18: returnalpha
PVSplit算法对强有序的博弈树的搜索效率较高.试验表明,在搜索强有序博弈树时,PVSplit算法比Tree Splitting算法的性能优越,尤其是在处理器树较宽的时候.衡量处理器树宽度的指标是处理器树的扇出(fan-out),即每个处理器所拥有的子处理器的个数.
6.5 Mandatory Work First算法
Mandatory Work First算法[14],简称MWF算法,它基于这样一个基本思想:无论博弈树是否为良序,其最小树上各位置对应的结点均不可被修剪,所以这些结点可以独立地并行地完成搜索.所以MWF算法可分为两个阶段,第一个阶段并行地对最小树上各位置对应的结点进行搜索,第二个阶段使用被第一个阶段缩小的搜索窗口对其他结点进行搜索.
在MWF算法中,一个结点的的子结点可以分成两类,左子结点和左子结点.结点的第一个子结点是是该结点的左子结点(left son),对应的树是左子树,结点的所有其他的子结点是该结点的右子结点(right sons),对应的树是右子树(rightsubtrees).
在MWF算法的第一个阶段,从根结点开始,对结点递归地产生进程,搜索结点的子树.对一个结点的左子树,需要对该子树的所有子树产生进程,进行搜索.对结点的右子树,只需对该子树的左子树产生进程,进行搜索.当一个左子树搜索完成之后,处理该结点的进程将该子树的博弈值上交给父结点的进程.一个右子树的进程在接收到它的左子树的博弈值之后,将这个博弈值当做自己的暂时的博弈值,上交到它的父结点的进程.而一个左子树的进程不仅会接收到它的左子树的博弈值,而且能接收到右子树们的暂时博弈值,该进程会将它的左子树的博弈值和右子树们的博弈值对比(cutoffcheck),删除那些可以剪枝的右子树.剪枝完成后,算法进入第二个阶段.
在第二个阶段中,对于一个左子树的右子树们,如果不能在算法的第一个阶段内剪枝,该左子树的进程会发起另一个进程,顺次搜索这些分支,直到所有的右子树们被剪枝或者搜索完全(exhaustivelysearched)为止.
通过上述方法,只有博弈树中的那些必要的结点才会被率先搜索,而且会在产生进程搜索那些可能被剪枝的搜索之前,进行剪枝审查(cutoffcheck).这点保证了在第一个阶段,不会进行无必要的搜索.
6.6 YBWC算法
为了分析Alpha-Beta算法的性能,[4]将一棵的最小树的结点划分成三种: PV结点(type 1),CUT结点(type 2)和ALL结点(type 3):
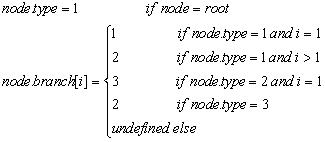
在YBWC(YoungBrothers Wait Concept)算法中[15]对一棵博弈树的结点进行如下的划分:
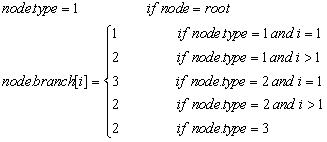
将这种划分中,type 1的节点称为Y-PV结点,type 2的节点称为Y-CUT结点,将type 3的节点又称为Y-ALL结点.可以注意到,Y-PV结点和PV结点很相像,Y-ALL结点和ALL结点很相像,但是Y-CUT结点和CUT结点有很大的不同.
YBWC算法的基本策略是:
1. 对于一个Y-PV类型的结点v,只有在v的第一个分支被搜索完全之后才能够并行地搜索v的其他子结点.
2. 对于一个Y-CUT类型的结点v,只有在v的前途有望(promising)的分支被搜索完全之后,才能并行地搜索v的其他子结点.前途有望的分支的确切定义是与具体应用有关的,也可以通过转移表,或者杀手启发等方法来获得可能较好的移动.YBWC的改进版本中引入了这个策略,这个策略使得在Y-CAT类型的结点时需要等待的更长的时间才能进行并行搜索.它虽然减少了潜在并行性,但是实际的应用表明它极大地减少了搜索开销,使得算法的性能比原来的版本有了进一步的提升.
3. 对于一个Y-ALL类型的结点v,任何时候都能够并行地搜索.
只有满足以上准则的结点,才能对它的子结点进行并行搜索.如果一个处理器占有的结点中有一些满足上面的条件,那么这个处理器就有工作做,否则它就是空闲的(idle).占有关系(ownership)是处理器和结点之间的一种关系.如果一个处理器占有一个结点,那么该处理器负责对该结点进行评估(evaluation),同时负责将评估的结果上交到它的父结点处.在这个处理器占有的结点中,满足以上准则的那个结点就会称为分裂点(split-point),如果有多个结点满足这个准则,那么在博弈树中位置最高的节点被选为分裂点.分裂点就是一个被选作并行搜索的结点.
在YBWC算法的开始后,根结点的占有权被分配给一个处理器,所有其他的处理器都处于空闲状态.如果处理器P1是空闲的,P1会随机地选择一个处理器P2,向P2请求工作.如果P2有工作做,那么P2和P1之间就建立起主从关系(master-slave relationship).一个主处理器可能有多个从处理器,它们共同承担对分裂点的搜索.每个处理器都处理分裂点的一个分支,直到分裂点搜索完成.和PVSplit算法一样,在YBWC算法中,如果一个处理器发现在分裂点的存在一个博弈值的改进,那么新的博弈值将会被发送到所有相关的处理器.处理器也可能发现在分裂点处可以进行剪枝.就这样,在搜索完成后,所有的从处理器回到空闲状态.如果分裂点处没有工作可做,从处理器可以回到空闲状态.但是,如果主处理器完成对分裂点的分支的搜索后,发现分裂点处没有工作可做,它不应该等待它的从处理器完成对其他分支的搜索,因为这样会增加同步开销.这种情况下,主处理器会像一个忙碌处理器的从处理器那样工作.这种思想被称为主处理器乐于助人(helpful master concept).
当P1向P2发送请求工作的消息时,P2也许没有工作要做,它会将这个消息转发到一个随机选择的处理器去.但是,如果这个消息之前已经传送了一定的次数,P2会丢弃这个消息,并且告知P1没有工作要做.P1闻知后,重新请求工作.
6.7 Jamboree算法
Jamboree算法[16]是一个基于串行PVS算法的并行算法,它的基本思想是:一般来说,相比于一个开放的搜索窗口的搜索时间,一个零窗口(宽度为1的搜索窗口)的搜索时间少得多,所以虽然用零窗口进行搜索可能得到无效的搜索结果,但是其搜索开销是可接受的,相比来说,如果用开放(full)的搜索窗口进行搜索,如果产生无必要的搜索,那么其搜索开销就比较大了.
与PVS一样,对每个结点, Jamboree算法首先使用完全的搜索窗口[α, β],搜索第一个子结点,然后根据该子树的博弈值V,设定一个最小搜索窗口[V, V + 1],用这个搜索窗口并行地搜索其他的所有子树.与PVS不同的是,对那些用最小搜索窗口搜索失败的子树,Jamboree算法并不立即使用开放窗口搜索.它由于期待前面的子树搜索完成之后,能够将搜索窗口进一步缩小,所以一直等待前面的子树搜索完成,才开始重新进行对子树的搜索.
Jamboree算法的伪代码如下所示[16]:
Jamboree(node, alpha, beta)1:if node.depth = 0 then2:return EvaluateNegaMax(node)3:new_node ← Traverse(node, node.branch[1])4:b ← -Jamboree(new_node, -beta, -alpha)5:if b ≥beta then6:return value7:if b > alpha then8:alpha ← value9:for i ← 2 to node.branch.length par-do10:new_node ← Traverse(node, node.branch[i])11:s ← -Jamboree(new_node, -alpha - 1, -alpha)12:if s > b then 13:b ← s14:if s ≥ beta then15:abort-and-return s16:if s > alpha17:Wait for the completion of all previous iterations of the parallel loop18:s ← -Jamboree(new_node, -beta, -alpha)19:if s ≥ beta then20:abort-and-return s21:if s > alpha then22:alpha ← s23:if s > b then24:b ← s25:Note the completion of the i-th iteration of the parallel loop26:return b算法中abort-and-return语句的意义是将所有仍在运行的子进程终止,让后将返回值返回.
6.8 UIDPABS 算法
UIDPABS(Unsynchronized Iteratively DeepeningParallel Alpha-Beta Search)算法[16]使用迭代深化的方法,但处理器不需要等待其他的处理器完成上一次迭代的搜索.它的方法如下:
1. 在算法的前两次迭代中,所有的处理器执行相同的搜索,为以后的迭代作准备.由于所有的处理器对移动的排序使用同样的标准(criteria),所以这两次迭代后,所有的处理器得到相同的移动的排序.通过这两次迭代,同时得到了对博弈值的估计RS.以RS为中心,可以为以后的迭代估计一个搜索窗口.如果第一次和第二次迭代的博弈值之差小于2P,那么就将搜索窗口设置为[RS- P + 1, RS + P - 1],否则,将搜索窗口设置为[RS -2P + 1, RS + 2P - 1].对于一个国际象棋程序,P就是的估值函数对小卒(pawn)的估值.
2. 假设博弈的初始时有M个合法移动,也就是博弈树的根结点有M个子树,如果有K个处理器,按照如下方法将移动的搜索分配给各处理器,每个处理器负责不多于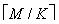 个子树的搜索.第k个处理器负责的移动为:第k个,第k+K个,第k+2K个,...,第
个子树的搜索.第k个处理器负责的移动为:第k个,第k+K个,第k+2K个,...,第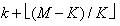 个移动.使用这种分法的目的在于将前两次迭代中找到的好的移动平均分配到各处理器中,有负载平衡的作用.
个移动.使用这种分法的目的在于将前两次迭代中找到的好的移动平均分配到各处理器中,有负载平衡的作用.
3. 各处理器分别对所分配的移动做迭代深化搜索.如果一个处理器的某次迭代结束后,出现了搜索得到的博弈值比搜索窗口的下限小(fail low),那么就将搜索窗口向下平移P,并开始下次迭代.如果这个现象在以后的迭代中再次出现,那么窗口将不被改变.使用这种策略虽然有可能导致整个搜索终止后,该处理器得到的博弈值仍比搜索窗口小.但是由于小的窗口能使得搜索更快,并且在整个搜索终止之后,所有处理器得到的博弈值比其搜索窗口的下限小(即所有处理器都faillow)的现象不大可能发生.然而相反的,如果处理器的在进行某次迭代时,发现得到的值比搜索窗口[x,y]的上限y大(fail high),那么处理器立即终止迭代,修改搜索窗口位[y, +∞],并重新开始该次迭代.
5. 当搜索时间超过某个预定的时间限制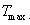 时,搜索终止.这时,所有的处理器向主处理器提交它得到的主变量和博弈值.主处理器从中确定最优的结果,并将之通知给所有其他处理器.如果在搜索终止时,一个处理器仍在搜索子树,而还没有得到本次迭代的结果,那么该处理器应将上次迭代中找到的主要变量和博弈值上交给主机.如果主机最后得到的博弈值处在对应搜索窗口之内(即上交最佳博弈值的处理器最后不是fail low),那么整个搜索成功完成.如果所有的处理器所计算的博弈值都小于各自窗口的下限,那么必须用更宽的搜索窗口重新启动整个搜索.
时,搜索终止.这时,所有的处理器向主处理器提交它得到的主变量和博弈值.主处理器从中确定最优的结果,并将之通知给所有其他处理器.如果在搜索终止时,一个处理器仍在搜索子树,而还没有得到本次迭代的结果,那么该处理器应将上次迭代中找到的主要变量和博弈值上交给主机.如果主机最后得到的博弈值处在对应搜索窗口之内(即上交最佳博弈值的处理器最后不是fail low),那么整个搜索成功完成.如果所有的处理器所计算的博弈值都小于各自窗口的下限,那么必须用更宽的搜索窗口重新启动整个搜索.
UIDPABS算法控制简单,调试容易,由于算法是异步的,所以不存在同步开销,在搜索的过程中,也没有消息的传递,所以通信开销被消除了,但是由于剪枝的减少,使得冗余搜索增多,搜索开销很大.
6.9 ABDADA算法
ABDADA(法文Alpha-Bêta Distribué Avec Droitd'Aînesse,翻译成英文是DistributedAlpha-Beta Search with Eldest Son Right)算法[17]是一个不同步的并行算法.ABDADA算法借鉴了YBWC算法的基本思想:一个结点的子结点只有在第一个结点已经搜索完全之后才允许并行地进行搜索.ABDADA算法通过对扩展的转移表,来实现对并行搜索的控制.
ABDADA算法可以描述为:
1. 在标准的转移表的基础上,对转移表的每个表项(entry),维护一个新的变量nproc.nproc指的是当前正在对表项对应结点进行搜索的处理器个数(number of processors).
2. 所有的处理器在博弈的根结点就开始并行地搜素.
3.当一个处理器开始对一个位置进行搜索时,算法将该位置对应的表项的变量nproc加1.
4. 当处理器结束对一个位置的搜索时,算法将该位置对应得表项的变量nproc减1.
5. 如果处理器要对一个结点的子结点们进行搜索,它遵循的策略如下:
a. 首先搜索该结点的第一个子结点,如果转移表中有关于该结点对应的有用表项,处理器会利用该表项信息搜小搜索窗口.
b. 在第一个子结点搜索完成后,处理器开始独占地(exclusively)搜索其他子结点.如果其他的子结点没有被其他处理器搜索,即对应转移表的表项nproc不大于0(或者子结点在转移表中没有对应表项,entry = NULL),那么该处理器就可以独占地对该子结点进行搜索了.处理器顺序地查询所有的子结点,对所有满足条件的子结点进行独占搜索.
c. 由于在第二阶段时,一个子结点有可能正在被另一个处理器进行深度较小的独占搜索,所以有可能第二阶段结束后,某些子结点的在转移表中对应表项的深度并没有达到搜索深度的要求.故此,在本阶段,处理器搜索遍历所有的子结点,只要发现存在这样的子结点,就对它重新进行搜索.当然,也有可能不存在这样的子结点,这时就不必进行第三阶段的搜索了.
基于上面的思想,ABDADA算法的伪代码如下所示[18]:
Abdada(node, alpha, beta, exclusiveP)1:if(node.depth = 0) then2:return EvaluateNegaMax(node)3:best ← -INF4:RetrieveAsk(node, alpha, beta, exclusiveP)5:node.branch ← GenMove(node)6:(alpha, beta, best) ← RetrieveAnswer()7:if (alpha ≥ beta) || (best = ON_EVALUATION) then8:return best9:alldone ← false10:for iteration ← 1 to 211:if alldone = true12:break13:alldone ← true14:for i ← 1 to node.branch.length15:exclusive ← (iteration = 1 && i ≠ 1)16:new_node ← Traverse(node, node.branch[i])17:value ← -Abdada(new_node, -beta, -Max(alpha, best), exclusive)18:if value = -ON_EVALUATION then19:alldone ← false20:elsif value > best then21:best ← value22:if(best > beta) then23:goto done24:done:25:StoreHash(node, alpha, beta, best)26:return bestRetrieveAsk(node, alpha, beta, exclusiveP)1:entry ← GetEntry(node)2:answer.alpha ← alpha3:answer.beta ← beta4:answer.score ← -∞5:if entry = NULL then6:goto endprobe7:if entry.depth = node.depth && exclusiveP && entry.nproc > 0 then8:answer.score ← ON_EVALUATION9:goto endprobe10:if entry.depth ≥ node.depth then11:if entry.flag = VALID then12:answer.score ← entry.score13:answer.alpha ← entry.score14:answer.beta ← entry.score15:elseif entry.flag = UBOUND && entry.score < beta then16:answer.score ← entry.score17:answer.beta ← entry.beta;18:elseif entry.flag = LBOUND && entry.score > alpha then19:answer.score ← entry.score20:answer.alpha ← entry.alpha;21:if entry.depth = node.depth && answer.alpha < answer.beta then22:entry.nproc ← entry.nproc + 1;23:else24:entry.depth ← node.depth25:entry.flag ← UNSET26:entry.nproc ← 127:endprobe:28:send (answer.alpha, answer.beta, answer.score)StoreHash(node, alpha, beta, score)1:entry ← GetEntry(node)2:if entry = NULL || entry.depth > node.depth then3:return4:if entry.depth = node.depth then5:entry.nproc ← entry.nproc - 16:else7:entry.nproc ← 08:if score ≥ beta then9:entry.flag ← LBOUND10:elseif score ≤ alpha then11:entry.flag ← UBOUND12:else13:entry.flag ← VALID14:entry.score ← score15:entry.depth ← node.depth
在上诉伪代码中,Abdada()函数的参数exclusiveP表明结点node的搜索是不是应当被独占地搜索.当对结点进行独占搜索时,如果有另一个处理器正在进行搜索,那么转移表的查询函数RetrieveAsk()会返回ON_EVALUATION值.由于转移表查询表项和消息传递(send操作)的持续时间较长,可以在发送请求(调用RetrieveAsk()函数)到取到消息(调用RetrieveAnswer()函数)之间生成子结点移动(调用GenMove()函数).
由于ABDADA算法不进行同步,所以该算法不存在同步开销.
6.10 APHID算法
APHID(Asynchronous Parallel HierarchicalIterative Deepening)博弈树搜索算法[18]将处理器分成两种,其中一个为主处理器(master),其他为从处理器(salve).
算法采用迭代深入的搜索方法.在深度为d的搜索中,主处理器负责搜索博弈树的深度小于d'的结点,而深度为d'的结点的所有子结点都由从处理器并行搜索.称这些子结点为d'深度树(d' ply tree)的叶子,或者主树(master's tree)的叶子.其中d'为一个固定的边界(frontier).当主处理器搜索到d'深度树的叶子时,如果这个结点已经由一个从处理器完成了d - d'深度的搜索,则称这个叶子是确定的,否则,该叶子是不确定的.处理器统计所有主树的叶子是否为确定的,如果均为确定的,则本次迭代结束,否则,只要有一个叶子是不确定的,那么主处理器再次遍历(passover)d'深度树.
算法维护一个所有处理器共享的存储表(APHID Table).存储表的每个表项都分为两部分,一部分只能由主处理器写入,另一部分只能由负责该表项对应工作的从处理器写入.任何一个写入都会引发一个消息,告知主处理器或者对应的从处理器更新信息.主处理器和对应的从处理都只读入本地的信息复本,在主处理器和对应的从处理器之间,不会收发要求信息的消息.
在存储表的表项中,由主处理器维护的信息包括:从博弈树根结点到主树的叶子所经历的移动序列,叶子在树中的大致位置(这个信息用来给从处理器优化移动的择序),该叶子是否在主处理的最近一次遍历中是否被触及(touch),叶子被分配到哪个从处理器处理.其中,当前没有被触及的叶子,在之前的遍历时曾经被从处理器搜索过,但在最近一次遍历是没有被触及,由于那些由从处理器取得的信息可能在以后的遍历中有用,所以该表项没有被主处理器删除.
在存储表的表项中,由从处理器维护的信息包括:叶子被搜索的深度及其结果.搜索所得的结果不一定是一个准确的博弈值,有可能是博弈值的上限或者下限.如果上限和下限相等,那么就得到了准确的博弈值.
和UIDPABS算法一样,该算法通过轮询(round-robin)的方式将主树的叶子均分给各从处理器,使得它们的负载近似均衡.从处理器执行如下的操作直到主处理器告知搜索完成为止:从处理器查看属于它的那部分存储表的本地复本,找到优先级最高的结点,搜索这个结点,然后将搜索结果上交到主处理器(即更新存储表).
结点优先级的判定准则包括:主要标准(primarycriterion),即结点已经由该从处理器搜索的深度,如果主要标准一样,那么将结点在主树中所处的位置作为辅助标准(secondary criterion).辅助标准是必要的,因为通常为主处理器从左到右地返回搜索结果是有益的.对于一个当前没有被触及的叶子,它的优先级为0,将不会被搜索.
在搜索进行之前,从处理器需要设置搜索窗口.主处理器持续将估计的博弈值告知从处理器.虽然搜索窗口的宽度是应用相关的(application-dependent),但是一般围绕估计的博弈值设定搜索窗口,并根据估值的不确定性,加上或减去一个因子.
有时,从处理器返回的搜索信息也许对主处理器毫无用处.例如一个处理器可能告知主处理器叶子的博弈值处于30以下,而主处理器想知道该博弈值是否位于[-5, 5]的区间内.这时,一个搜索(bad boundsearch)就被主处理器发起了:主处理器向从处理器发送“bad bound”消息,从处理器接收主处理器发送的搜索窗口的上下限,然后搜索该子树到需要的深度.
除了“bad bound”的消息,从处理器需要从主处理器接收的消息还包括:某个叶子的搜索出现,一个新叶子被加入该处理器的存储表的消息.
为了提高性能,需要使得从处理器不停歇地工作.一个从处理器将所有负责的叶子搜索到要求的深度d - d'时,它不会停下来处于空闲状态,而是以深度d - d' +1重新搜索它负责的结点,用来预测下一次迭代.此时,从处理器将照常查收来自主处理器的消息.如果从处理器接收到一个深度等于或小于d - d'的搜索任务,当前进行的搜索将立即放弃,而开始进行当前任务.
6.11 更多...
本章介绍了一些典型的并行Alpha-Beta算法.除了介绍过的算法外,还有一些其他的并行Alpha-Beta算法,这里不一一介绍.
本文章欢迎转载,请保留原始博客链接http://blog.csdn.net/fsdev/article
--------------------
[1] Valavan Manohararajah(2001). Parallel Alpha-Beta Search on SharedMemory Multiprocessors. Master’s thesis, Graduate Department of Electrical andComputer Engineering, University of Toronto, Canada.
[2] A. Newell and H.A. Simon (1972). Human Problem Solving.Prentice-Hall, 1972.
[3] Stuart Russell and Prter Norvig (1995). Artificial Intelligence, AModern Approach. Prentice-Hall, Egnlewood Cliffs, 1995.
[4] Knuth, D.E. and Moore, R.W. (1975). An Analysis of Alpha-Beta Pruning.Artificial Intelligence, 6:293–326.
[5] Hopp, Holger and Sanders, Peter (1995). Parallel Game Tree Search onSIMD Machines. IRREGULAR '95: Proceedings of the Second International Workshopon Parallel Algorithms for Irregularly Structured Problems. 349-361.
[6] Marsland, T.A. and Campbell, M.S. (1982). Parallel Search ofStrongly Ordered Game Trees. ACM Computing Surveys, Vol. 14, No. 4, pp.533-551. ISSN 0360-0300.
[7] Schaeffer J.(1989). The History Heuristic and Alpha-Beta SearchEnhancements in Practice. IEEE Transactions on Pattern Analysis and MachineIntelligence. Vol. PAMI-11, No.11, pp. 1203-1212.
[8] Marsland, T.A. (1986). A Review of Game-Tree Pruning. ICCA Journal,Vol. 9, No. 1, pp. 3-19. ISSN 0920-234X.
[9] Korf , R.E. (1985). Depth-first Iterative-deepening Search: AnOptimal Admissible Tree Search. Artificial Intelligence, 27(1), 97-109.
[10] Aske Plaat, Jonathan Schaeffer,Wim Pijls, and Arie de Bruin(1995). Best-First and Depth-First Minimax Searchin Practice. In Proceedings of Computing Science in the Netherlands 1995,Utrecht, the Netherlands, November 27-28, 1995, pages 182-193.
[11] Brockington, M. G. andSchaeffer, J. (1996). APHID Game-Tree Search. Presented at Advances in ComputerChess 8, Maastricht.
[12] Brockington, M.G. (1996). ATaxonomy of Parallel Game-Tree Searching Algorithms. ICCA Journal, Vol. 19, No.3, pp. 162-174.
[13] Baudet G. M.(1978). The Designand Analysis of Algorithms for Asynchronous Multiprocessors. Carnegie MellonUniversity, Pittsburgh, PA, Available as Tech. Rep. CMU-CS-78-116.
[14] Akl, S.G., Barnard, D.T. andDoran, R.J.(1982). Design Analysis and Implementation of a Parallel Tree SearchAlgorithm. IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol.PAMI-4, No.2, pp. 192-203.
[15] Feldmann, R., Mysliwietz, P.and Monien. B (1993). Game Tree Search on a Massively Parallel System. InAdvances in Computer Chess 7, 1993. (The conference was held in June1993, butthe proceedings have not published as of August 1993.)
[16] Kuszmaul, B.C. (1994).Synchronized MIMD Computing. Ph.D thesis, Massachusetts Institute ofTechnology, Cambridge MA.
[17] NewBorn M.(1988). UnsynchronizedIteratively Deepening Parallel Alpha-Beta Search. IEEE Transactions on PatternAnalysis and Machine Intelligence, Vol. PAMI-10, No.5, pp. 687-694.
[18] Weill, J-C. (1996). The ABDADADistributed Minimax-Search Algorithm. ICCA Journal, Vol.19, No.1, pp. 3-16.
[19] Mark Brockington and JonathanSchaeffer(1996). The APHID Parallel Alpha-Beta Search Algorithm , Eighth IEEESymposium on Parallel and Distributed Processing, pp. 432-436.
[20] Stockman, G. C. (1979). AMinimax Algorithm Better than Alpha-Beta? Artifcial Intelligence, Vol. 12, pp.179-196.
[21] Aske Plaat, Jonathan Schaeffer,Wim Pijls, and Arie de Bruin (1994). SSS* = Alpha-Beta + TT. Technical Report94-17, Department of Computing Science, University of Alberta, December 1994.
[22] Leifker, D. B. and Kanal, L.N.(1985). A Hybrid SSS*/Alpha-Beta Algorithm for Parallel Search of Game Trees.In Proceedings of IJCAI-85, pp. 1044-1046.
[23] Subir Bhattacharya and A.Bagchi (1989).Searching game trees in parallel using SSS*. Proc IJCAI-89,International Joint Conf on Artificial Intelligence, Detroit, USA, Aug 1989, pp42-47.
[24] Steinberg, I. R. and Solomon,M. (1990). Searching Game Trees in Parallel. In Proccedings of the 1990International Conference on Parallel Processing (vol.3), pp. 9-17, UniversityPark, PA. Penn. State University Press.
[25] Jaleh Rezaie and RaphaelFinkel(1992). A comparison of some parallel game-tree search algorithms.Technical report, University of Kentucky, Department of Computer Science,Lexington, USA.
[26] Karp, R. M. and Zhang, Yanjun.(1989). On Parallel Evaluation of Game Trees. In Proceedings of SPAA '89, pp.409-420, New York, NY. ACM Press.
[27] Richard M. Karp , Yangun Zhang(1998). On parallel evaluation of game trees, Journal of the ACM (JACM), v.45n.6, p.1050-1075, Nov.
[28] PKU JudgeOnline, Problem 1085,Triangle War. http://acm.pku.edu.cn/JudgeOnline/problem?id=1085.
- 并行博弈树搜索算法-第6篇 百花齐放:各种并行Alpha-Beta算法
- 并行博弈树搜索算法-第5篇 人多力量大(?):并行Alpha-Beta算法
- 并行博弈树搜索算法-第3篇 优秀的园丁:Alpha-Beta算法
- 并行博弈树搜索算法-第4篇 更上一层楼:Alpha-Beta算法的改进
- 并行博弈树搜索算法-第1篇 什么是博弈树搜索算法
- 并行博弈树搜索算法-第1篇 什么是博弈树搜索算法
- 并行博弈树搜索算法-第7篇 另辟蹊径:其他的博弈树并行搜索算法
- 并行博弈树搜索算法-第8篇 写在最后的话:有趣的的博弈算法
- 并行博弈树搜索算法-第2篇 博弈过程的抽象:MinMax方法
- 并行算法
- 博弈树搜索算法
- 重读Alpha-Beta算法
- Alpha-Beta 剪枝算法
- 详解alpha-beta算法
- [算法] Alpha-Beta搜索
- Alpha-beta 算法
- alpha beta 剪枝算法
- Alpha-Beta剪枝算法
- jQuery.validate.js插件使用(struts2的整合)
- spring与jdbc的结合使用
- 整合struts2 jQuery validate 插件的远程Ajax验证
- js常用对象与面向对象
- 在Linux下编译latex中文(使用CJK)的一点注记
- 并行博弈树搜索算法-第6篇 百花齐放:各种并行Alpha-Beta算法
- 用Ubuntu 11.10+Apache SSL,Subversion ,trac快速搭建一个项目管理系统
- Java程序员面试题及解答
- ubuntu rpm
- Objective-C及Xcode 4入门视频
- dom4j读写xml文件
- 动态联编
- 新的动力。
- java中Comparator 和 Comparable 的区别


