android优化实战(二)-BigInteger
来源:互联网 发布:jdk源码 视频教程 编辑:程序博客网 时间:2024/04/30 21:15
上一篇我们使用了迭代替换递归达到优化的目的,但仍存在一个严重的问题:它们不能返回正确的结果。问题归咎于返回的结果值被存储在一个长整形,是64-bit的。但最大的Fibonacci数字能匹配64-bit的值是 7,540,113,804,746,346,429。也就是说92的Fibonacci数。当计算93Fibonacci数时,因为已经溢出,返回的结果将是不正确的。而且发生这样的错误时,非常难以排查。
(友情提示:java特别的指定原始类型(除了boolean):long长整形是64位,int整形是32位,short是16位。)
java提供了一个合适的类去解决这个溢出问题:java.math.BigInteger.
一个BigInteger对象能够指定任意大小的integer性以及类还所有的数学基本运算。如下就是BigInteger版本的computIterativelyFaster。
public class Fibonacci {
public static BigInteger computeIterativelyFasterUsingBigInteger (int n)
{
if (n > 1) {
BigInteger a, b = BigInteger.ONE;
n--;
a = BigInteger.valueOf(n & 1);
n /= 2;
while (n-- > 0) {
a = a.add(b);
b = b.add(a);
}
return b;
}
return (n == 0) ? BigInteger.ZERO : BigInteger.ONE;
}
}
这个实现保证了溢出的情况不会再发生。又有新的问题产生了,如果调用computeIterativelyFasterUsingBigInteger(50000)耗费了差不多1.3秒完成,运行效果相当慢。造成这一原因有如下三点:
(1)BigInteger是不可变的。
因为BigInteger是不可变的,我们必须这样写“a=a.add(b)”而不是简单的“a.add(b)”。许多人经常误认为a.add(b)等于"a+=b".其实它是等于a+b。因此,我们必须这样写:a.add(b).然而,就是这一操作,又创建出一个新的对象。
(2)BigInteger是使用BigInt和本地代码实现的。
因为BigInteger的外部实现,另外的yigBigInt对象将被在每一次的BigInteger操作运算中创建。结果就是创建比预期多一倍的对象。例如:computeIterativelyFasterUsingBigInteger(50000)执行一次,将创建大约100,000个对象(虽然可以在最后被垃圾处理机制收集)。而且,BigInt是利用本地代码实现的(调用本地代码还需要JIT编译器一定的开销)。
(3)越大的数字,加起来的操作就更长。
非常大的数字不匹配单独的,长整形的64-bit值。例如,50,000Fibonacci数是34,7111-bit。
(友情提示:BitInteger这样的外部实现(BigInteger.java)将会在未来的Android发行版改变。实际上,外部实现的任何类都会改变。)
内存的分配十分重要,例如,当用到不可变的对象如BigInteger。下一步的优化应通过另一种算法减少内存的分配,基于Fibonacci Q矩阵,如下:
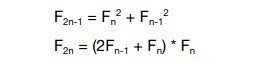
这两方程可以再次用BigInteger实现,如下:
public class Fibonacci {
public static BigInteger computeRecursivelyFasterUsingBigInteger (int n)
{
if (n > 1) {
int m = (n / 2) + (n & 1); // not obvious at first – wouldn’t it be great to
have a better comment here?
BigInteger fM = computeRecursivelyFasterUsingBigInteger(m);
BigInteger fM_1 = computeRecursivelyFasterUsingBigInteger(m - 1);
if ((n & 1) == 1) {
// F(m)^2 + F(m-1)^2
return fM.pow(2).add(fM_1.pow(2)); // three BigInteger objects created
} else {
// (2*F(m-1) + F(m)) * F(m)
return fM_1.shiftLeft(1).add(fM).multiply(fM); // three BigInteger
objects created
}
}
return (n == 0) ? BigInteger.ZERO : BigInteger.ONE; // no BigInteger object
created
}
public static long computeRecursivelyFasterUsingBigIntegerAllocations(int n)
{
long allocations = 0;
if (n > 1) {
int m = (n / 2) + (n & 1);
allocations += computeRecursivelyFasterUsingBigIntegerAllocations(m);
allocations += computeRecursivelyFasterUsingBigIntegerAllocations(m - 1);
// 3 more BigInteger objects allocated
allocations += 3;
}
return allocations; // approximate number of BigInteger objects allocated when
computeRecursivelyFasterUsingBigInteger(n) is called
}
}
一次调用computeRecursivelyFasterUsingBigInteger(50000)消耗大约1.6秒。这个实现比我们目前的迭代方法还要慢。这一次,被分配的数量为大约200,000个对象。
(友情提醒:实际被创建的对象没那么多,因为BigInteger‘的实现使用预分配对象,例如 BigInteger.ZERO , BigInteger.ONE, or BigInteger.TEN,有些运算没必要分配新的对象,你可以查看android帮助文档了解具体的实现细节:http://developer.android.com/reference/java/math/BigInteger.html)
结下做进一步优化,虽然用BigInteger能保证正确性,但也没必要对于每一个n值使用BigInteger。我们知道原始类似的长整形最多能达到92,我们可以做点小小的改动,把Biginteger和原始类型混合使用,如下所示:
public class Fibonacci {
public static BigInteger computeRecursivelyFasterUsingBigIntegerAndPrimitive(int n)
{
if (n > 92) {
int m = (n / 2) + (n & 1);
BigInteger fM = computeRecursivelyFasterUsingBigIntegerAndPrimitive(m);
BigInteger fM_1 = computeRecursivelyFasterUsingBigIntegerAndPrimitive(m -
1);
if ((n & 1) == 1) {
return fM.pow(2).add(fM_1.pow(2));
} else {
return fM_1.shiftLeft(1).add(fM).multiply(fM); // shiftLeft(1) to
multiply by 2
}
}
return BigInteger.valueOf(computeIterativelyFaster(n));
}
private static long computeIterativelyFaster(int n)
{
// see Listing 1–5 for implementation
}
}
调用 computeRecursivelyFasterUsingBigIntegerAndPrimitive(50000)耗费73毫秒,被分配大约11,000个对象。显而易见,相对于上一个,这次小小的改动比上一个快了20倍,而且比上一个少分配了20倍的对象空间。很惊奇是吧!其实,我们还可以通过减少分配空间的数量做进一步优化,当Fibonacci类第一次被载入,预先计算的结果能很快产生,这一结果能再下一次被立即使用,如下所示:
public class Fibonacci {
static final int PRECOMPUTED_SIZE= 512;
static BigInteger PRECOMPUTED[] = new BigInteger[PRECOMPUTED_SIZE];
static {
PRECOMPUTED[0] = BigInteger.ZERO;
PRECOMPUTED[1] = BigInteger.ONE;
for (int i = 2; i < PRECOMPUTED_SIZE; i++) {
PRECOMPUTED[i] = PRECOMPUTED[i-1].add(PRECOMPUTED[i-2]);
}
}
public static BigInteger computeRecursivelyFasterUsingBigIntegerAndTable(int n)
{
if (n > PRECOMPUTED_SIZE - 1) {
int m = (n / 2) + (n & 1);
BigInteger fM = computeRecursivelyFasterUsingBigIntegerAndTable (m);
BigInteger fM_1 = computeRecursivelyFasterUsingBigIntegerAndTable (m - 1);
if ((n & 1) == 1) {
return fM.pow(2).add(fM_1.pow(2));
} else {
return fM_1.shiftLeft(1).add(fM).multiply(fM);
}
}
return PRECOMPUTED[n];
}
}
这一程序的运行需要PRECOMPUTED_SIZE(预处理数量):预计算数量设定越大,速度越快。然而,因为许多BigInteger 对象江北创建以及和直到Fibonacci类被加载保留在内存中,内存的利用又成了一个新的问题。我就合并上两个的算法,结合它们的优势使用。0~92可以使用 computeIterativelyFaster,93~127使用预处理结果,其他的就使用递归,而且,作为开发者,你要善于选择最好的实现,虽然不一定速度最快,我们还要基于以下考虑:
(1)你android应用目标适用的版本
(2)你的人力物力资源
我们注意到,优化可能使你的代码的可读性越来越差,所以,你应该想清楚是否有优化的必要以及它们会怎样影响你应用的发展。
- android优化实战(二)-BigInteger
- Android性能优化实战(二)----界面布局优化
- SQL Server数据库优化实战(二)
- Android OkHttp(二)实战
- 再谈 BigInteger - 优化
- Android内存优化(二)--布局优化
- Android绘制优化(二)布局优化
- Android性能优化(二)布局优化
- Android内部优化(二)
- Android内部优化(二)
- Android内存优化(二)
- android电量优化(二)
- Android优化UI(二)
- Android性能优化(四)之内存优化实战
- Android性能优化实战(一)----App启动时间优化
- MySQL实战(二)利用索引优化order by 排序
- C++实战之OpenCL矩阵相乘优化(二)
- Android 神器ViewDragHelper(实战二)
- x86系统引导(2)
- 苹果公司联系邮箱大全
- 第十二章
- gfgffdsafasdfffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffff反复反复反复反复反复反复反复反复反复反复反复反
- 2012年 上半年 第十三周 C++程序设计 (三十七)
- android优化实战(二)-BigInteger
- 编译器自动优化
- 【开发早会】快速切换,进入状态
- View的setOnClickListener的添加方法
- ubuntu useradd: unable to lock password file
- C++虚继承的作用
- git format-patch 常用方法 .
- 排序口诀
- C++虚继承的作用


