浏览器了解(二)HTML解析过程
来源:互联网 发布:房子设计软件 编辑:程序博客网 时间:2024/04/30 07:35
v\:* {behavior:url(#default#VML);} o\:* {behavior:url(#default#VML);} w\:* {behavior:url(#default#VML);} .shape {behavior:url(#default#VML);}
HTML解析过程
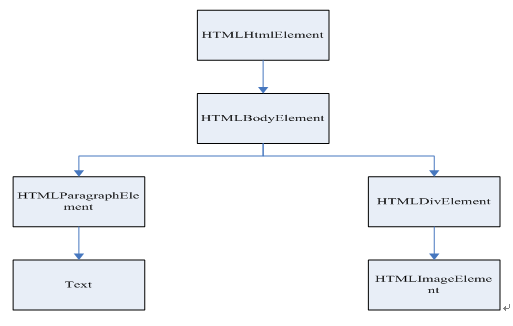
假设有这样一段HTML文本:
- <html>
- <body>
- <p>
- Hello World
- </p>
- <div> <img src="example.png"/></div>
- </body>
- </html>
解析后的结果应该如下图所示
WebKit的解析的过程为:
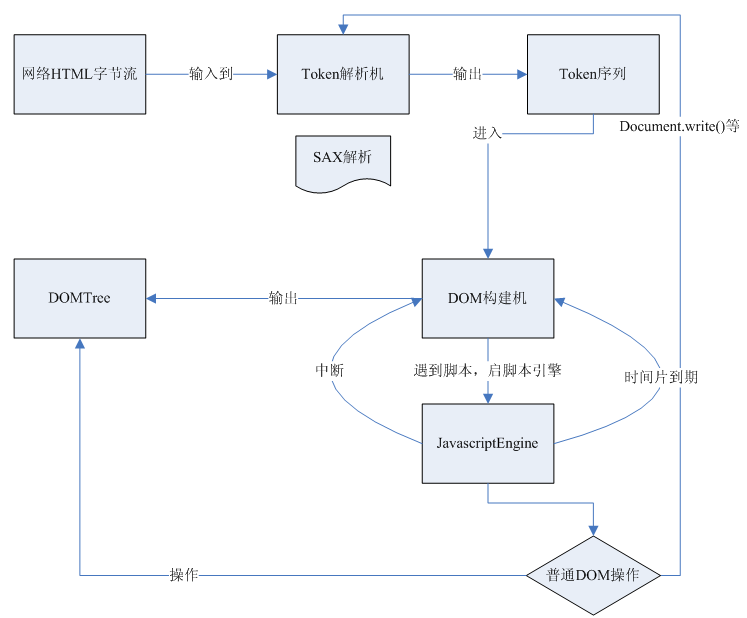
Html的解析主要包括两个部分
1. Tokeniser阶段
这是一个基于事件的HTML文本解析过程,最后会生成一个Token序列输出,当然此过程中来自网络的HTML不一定是整个文档,网络端接收到一部分HTML字节流时就会通知解析机解析该部分的内容。
2. TreeConstruction阶段
Tokeniser阶段的Token序列产生后,就会把序列一个一个地输入到TreeConstruction中,最后输出DOMTree。
本文出自 “雨轩印象” 博客,请务必保留此出处http://zilla.blog.51cto.com/3095640/832521
- 浏览器了解(二)HTML解析过程
- 浏览器解析HTML过程
- 浏览器解析HTML,CSS过程
- 通过chrome调试器测试了解浏览器解析和渲染HTML的过程
- 浏览器加载渲染网页过程解析(二)
- 浏览器了解(三)CSS解析
- 浏览器了解(四)javascript解析
- HTML简单了解-Web笔记(二)
- 浏览器是怎样工作的:渲染引擎,HTML解析(连载二)
- 浏览器是怎样工作的:渲染引擎,HTML解析(连载二)
- 浏览器是怎样工作的:渲染引擎,HTML解析(连载二)
- 浏览器是怎样工作的二:渲染引擎 HTML解析
- Jsoup解析Html(二)
- HTML解析篇-浏览器
- 浏览器解析过程
- 浏览器DNS解析过程
- 浏览器工作原理(四):HTML解析器 HTML Parser
- 跨浏览器解析XML文件(二)
- Maxima 矩阵及矢量运算 1
- 二叉树的创建和各种遍历方法
- Redhat5下安装ORACLE10.2.0.1时,图形界面出不来,报错:
- strust中Action类和ActionForm类的基本用法
- ArcSDE空间数据库连接方式
- 浏览器了解(二)HTML解析过程
- c++基础知识之一:变量和基本类型
- 浏览器了解(三)CSS解析
- 浏览器了解(四)javascript解析
- 浏览器了解(一)浏览器大概流程
- USB2.0走线要点
- qwtplot3d 学习笔记 1
- 多靠点谱,少靠点言
- 浏览器了解(五)资源加载顺序


