网页爬虫、中文分词、全文搜索及自动定时调度
来源:互联网 发布:java数据库连接池代码 编辑:程序博客网 时间:2024/04/29 05:22
如题,实现网页爬虫,将制定URL下的网页内容进行爬查,去掉HTML代码后保存到本地,并对这些内容进行中文分词,建立索引,而后提供全文搜索服务。爬虫、分词并建立索引,可以单独执行,也可以整合在一起进行定时调度而无需人工干预。不需要安装任何数据库,部署简单。部署好之后就可以马上对自己的网站进行爬虫、建立索引后就可以提供全文搜索服务,还可以通过JS方式,跨域提供全文搜索。
全文搜索页面(之所以标题都是一样,那是因为这个网站所有网页的TITLE标签值都是这个):
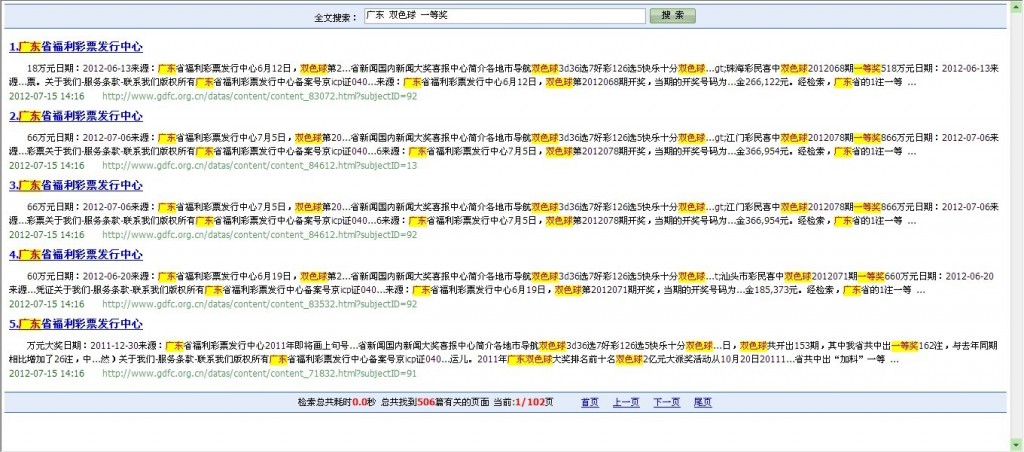
爬虫(搜索器)设置,可以设置多个互相独立的爬虫,只要相应的设置好相关参数即可:

搜索器顶层URL设置,也就是设置好需要向哪些网址进行爬查,每一个搜索器都可以设置多个顶层URL:
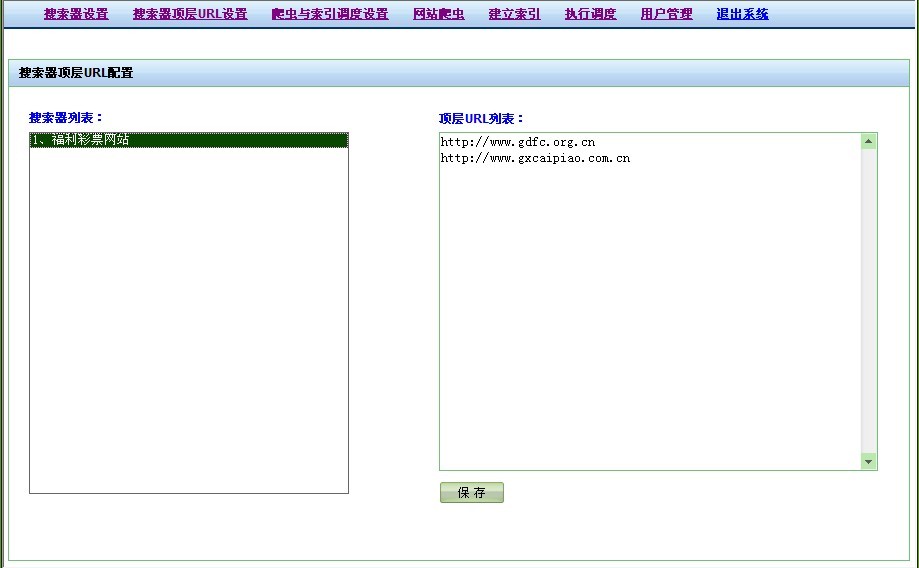
爬虫与索引调度设置,可以为每一个搜索器设置一个调度器,可以按分钟、小时、每天、每周、每月进行设置,设置好之并执行调度器,可以进行自动调度爬虫,爬虫执行完毕之后自动进行分词与建立索引:
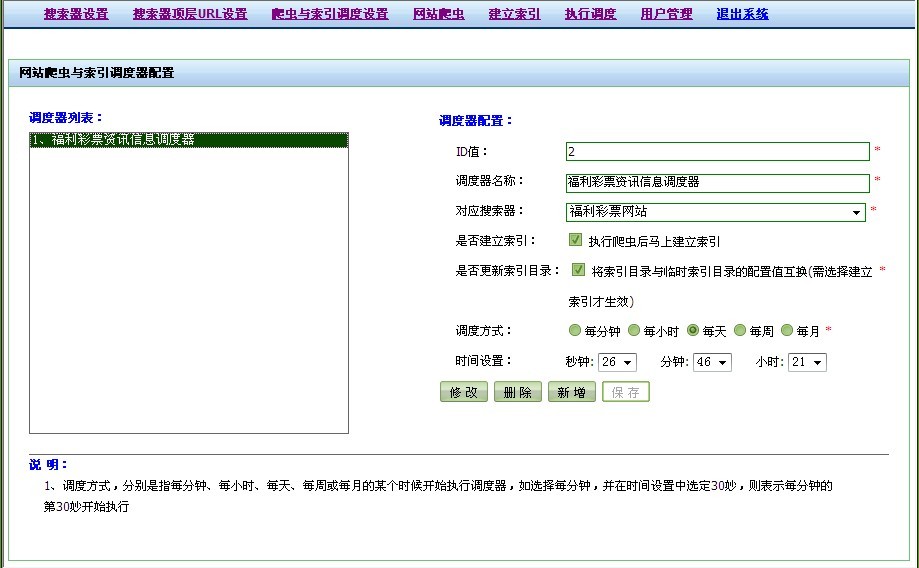
调度正在执行之时,可以进行软停止,或者硬停止;软停止是当调度器正在进行爬查或者建立索引时,先等待它们完成之后再停止,而硬停止则是无论目前调度器正在做什么,都必须马上停止。

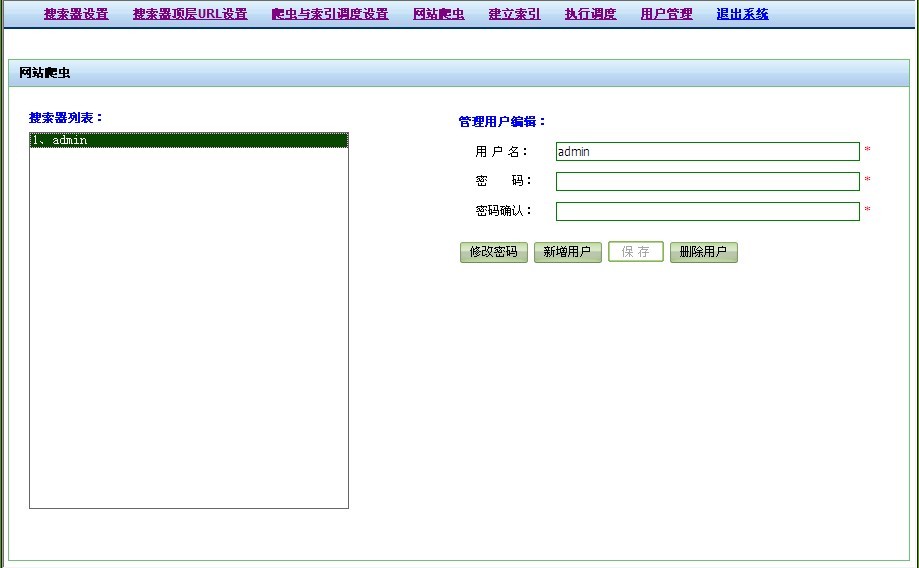
网站爬虫,也就是可以单独执行某个爬虫:
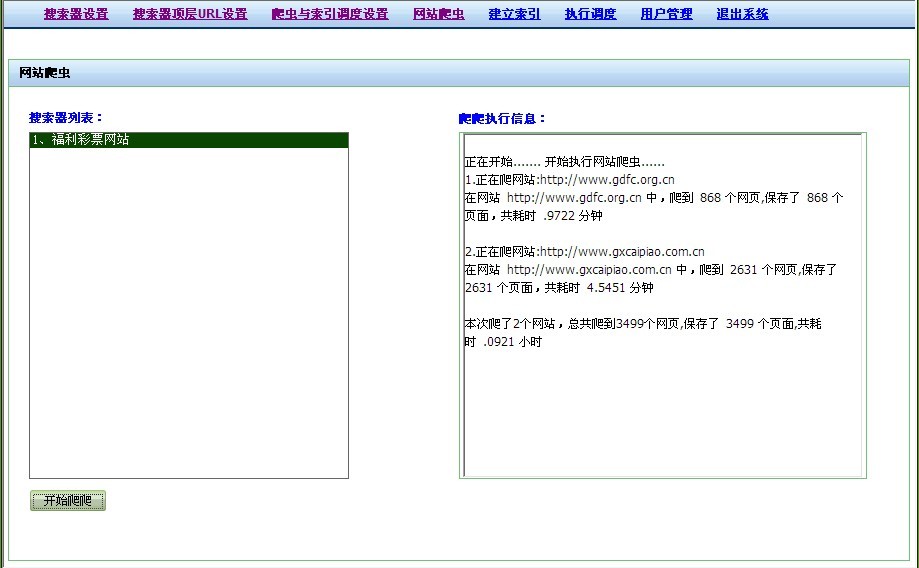
建立索引,就是可以单独对某个爬虫爬查的结果进行建立索引,这里有一个复选框,勾选后,就会当在临时索引目录建立了最新的索引之后,通过这个设置,就可以马上利用最新的索引文件提供全文搜索服务了。

用户管理,提供这个软件的用户管理:
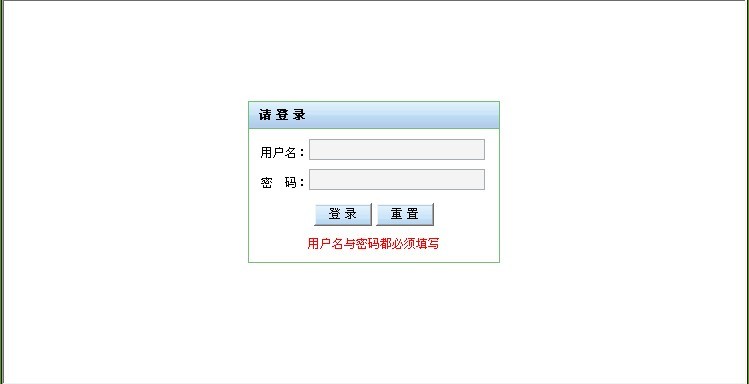
登陆界面:
- 网页爬虫、中文分词、全文搜索及自动定时调度
- Sphinx+Mysql+中文分词安装-实现中文全文搜索
- Sphinx+Mysql+中文分词安装-实现中文全文搜索
- PHP 中文分词及全文检索的实现
- java之全文索引搜索lucene之增删改查文档与中文分词搜索
- 全文检索之中文分词
- 【中文分词-全文搜索】Ubuntu 16.04 Mysql和PHP 配置 Sphinx-for-chinese 及Sphinx的排序筛选分页基本操作
- MySQL 中文全文搜索
- mysql中文全文搜索
- ORACLE全文搜索中文
- 使用paoding lucene分词和网页爬虫实现的简易网页搜索
- 二、ubuntu10.0.4下mysql配合sphinx和中文分词的全文搜索
- php+中文分词scws+sphinx+mysql打造千万级数据全文搜索
- php+中文分词scws+sphinx+mysql打造千万级数据全文搜索
- php+中文分词scws+sphinx+mysql打造千万级数据全文搜索
- php+中文分词scws+sphinx+mysql打造千万级数据全文搜索
- 【python 编程】网页中文过滤分词及词频统计
- 你不知道的全文检索---solr安装中文分词器及配置业务字段
- 父类子类的静态初始化块,初始化块,构造器执行顺序
- 委托加载DLL
- HashMap 和 Hashtable 的区别
- OpenSessionInViewFilter的一些原理
- ucosII 内存管理 解析
- 网页爬虫、中文分词、全文搜索及自动定时调度
- [刷题笔记] FZU 1015 土地划分
- live555峰哥的私房菜(三)-----RTSP会话的建立
- 暑假的第二周
- Drupal Poll
- 通过OpenOffice转换PDF
- SNS好友的redis结构设计
- 【菜鸟C++学习笔记】14.for语句
- OpenSSL相关命令(for Linux)


