找出第K大的数字
来源:互联网 发布:都市之数据化人生 编辑:程序博客网 时间:2024/05/01 17:17
建立一个K个数字的大顶堆,然后逐步插入数据和最后的哪个数字进行比较,如果大就插入堆中,否则就Pass;
===============
问题:
从一个数组里面,找出第K大的数。
题目很简单,要想把第K个数找出来,其实也挺容易的。
第一种方法:无非就是先排序,比如用Merge Sort算法,整个算法复杂度为 O(NlgN), 然后找到第K个即可。
第二种方法:如果k很小,比如第五个最大的数,而整个数组的长度非常的大,那么,还有一种方法就是,我做k遍找最大的数,每做一遍,就把最大的放在数组的最后面,然后减少数组扫描的范围,就可以把第k大的数找出来,这样做的复杂度就是O(K*N),在K很小的情况下,还是不错的。
第三种方法:我们可以借助quicksort的思想,把数组的值分成两部分,一部分比那个pivot大,一部分比pivot小,因为我们知道pivot在数组中的位置,所以比较k和pivot的位置就知道第k大的值在哪个范围,我们不断的进行recursion, 直到pivot就是第K大的值。时间复杂度,出乎意料,为O(N),但是这是平均复杂度。 为何它的平均复杂度比quicksort的复杂度低呢?重要原因是quicksort要对pivot两边的子数组还要排序,而我们其实只需要对其中一个进行处理,所以复杂度更低。具体怎么推导,请参考算法导论。
但是本文讲的是另一个算法,叫做SELECT 算法,它能在时间复杂度为O(N)的情况下找出第K大的数。先把算法贴出来,然后再讲。

第一步:把数组分成\lfloor n/5 \rfool 这么多子数组,每个子数组里包含5个数,因为会有无法整出的可能,所以最后一个子数组会小于5.
第二步:用insertion sorting 把这5个数排序,然后找出中位数,也就是第3个。
第三步:把获得的中位数又排序,找出中位数的中位数。如果中位数的个数是偶数,那么取排好序的第 m/2 个数,m指的是中位数的个数。
第四步:然后呢,把原来的数组分成两个部分,一部分比那个“中位数的中位数”大,一部分比那个“中位数的中位数”小。我们可以假设左边的数大,右边的数小。然后我们可以得到“中位数的中位数”的位置i.
第五步:如果i = k, 那么那个“中位数的中位数”就是第k大的数。如果 i < k, 不用说,第k大的在“中位数的中位数”的右边,否则就在左边。我们一直recursely 这么做,那么就一定能够找到第K大的值了。
其实,算法还是比较容易懂得,关键的关键,是复杂度的分析。如果能够知道复杂度如何求出来的,那么,对算法本身就了解得更清楚。
要讲复杂度,首先看一个图。
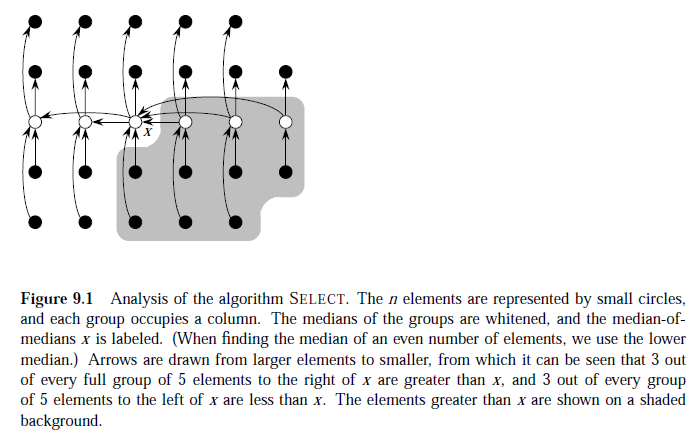
图中的X 就是“中位数的中位数”, 而且箭头的方向是从大数指到小数。所以,我们可以知道,至少灰色区域的都比X大,这是整个复杂度分析的关键,而,其它点能否说它比X大,我们不能保证。而灰色区域里最多有多少个数呢?因为X是中位数的中位数,所以,比X大的中位数最少有 [(\lfloor n/5 \rfool) * (1/2) - 2] 个(这个值也是关键), 这里减2是因为要去除X本身,第二呢,还要去除一个中位数---这个中位数所在的子数组个数小于5. 所以,最坏最坏的情况,第K大的值不在灰色区域里,那么我们就要对剩下部分进行不断的SELECT。剩余部分就是n - 3[(\lfloor n/5 \rfool) * (1/2) - 2] = O(7n/10) .
整个过程中,第1,2,4步所需时间为O(n), 注意第2步的复杂度不为O(n^2),第3步的复杂度为 T(n/5),第五步的复杂度为 T(7n/10)。
所以,复杂度的递归公式为: T(n) =T(n/5) +T(7n/10) + O(n), 算出来以后T(n) =O(n).
详解维基解密:http://en.wikipedia.org/wiki/Selection_algorithm
####################################################################
百度面试题:写一段程序,找出数组中第k大小的数,输出数所在的位置。例如{2,4,3,4,7}中,第一大的数是7,位置在4。第二大、第三大的数都是4,位置在1、3随便输出哪一个均可。
答案:
先找到第k大的数字,然后再遍历一遍数组找到它的位置。所以题目的难点在于如何最高效的找到第k大的数。
我们可以通过快速排序,堆排序等高效的排序算法对数组进行排序,然后找到第k大的数字。这样总体复杂度为O(NlogN)。
我们还可以通过二分的思想,找到第k大的数字,而不必对整个数组排序。
从数组中随机选一个数t,通过让这个数和其它数比较,我们可以将整个数组分成了两部分并且满足,{x,xx,...,t}<{y,yy,...}。
在将数组分成两个数组的过程中,我们还可以记录每个子数组的大小。这样我们就可以确定第k大的数字在哪个子数组中。
然后我们继续对包含第k大数字的子数组进行同样的划分,直到找到第k大的数字为止。
平均来说,由于每次划分都会使子数组缩小到原来1/2,所以整个过程的复杂度为O(N)。
##############################################################################
问题:
从一组数中选出其中最大的K个数,当这组数的个数为几百、几百万、几百亿时分别适合采用哪些算法?
个数为几百时,使用顺序统计法(看算法导论第9章):
算法思想是对输入数组进行递归划分,一边的数据小于选定数,另一边的数据大于等于选定数。但和快速排序不同的是,快速排序会递归处理划分的两边,而顺序统计法只处理划分的一边。其随机化算法的期望时间为O(n)。
[cpp]
#include <iostream>
#include <cstdlib>
using namespace std;
#define MAXN 103
int A[MAXN];
void select(int u, int v, int k)
{
int s = rand()%(v-u+1)+u;
int a = A[s];
A[s] = A[u];
A[u] = a;
int i, j=u;
for (i=u; i<=v; i++)
if (A[i] > a)
{
int tmp = A[++j];
A[j] = A[i];
A[i] = tmp;
}
A[u] = A[j];
A[j] = a;
if (j == k) return;
else if (j < k)
select(j+1, v, k);
else
select(u, j-1, k);
}
int main()
{
int n, k, i, j;
cin >> n >> k;
for (i=0; i<n; i++)
cin >> A[i];
select(0, n-1, k-1);
for (i=0; i<k; i++)
cout << A[i] << " ";
cout << endl;
}
个数为几百万时,数据量较大不适合全装入内存中,能容忍多次访问,可使用二分中值法(用法有点奇怪,个人不太喜欢):
本质上是通过二分思想找出第K大的数的值。算法从[Min, Max]开始逐渐缩小第K大的数取值的范围,时间复杂度为O(N*log(Max-Min))。
[cpp]
#include <iostream>
#include <cstdlib>
using namespace std;
int binary(FILE *in, int v)
{
rewind(in);
int a, sum = 0;
while (fscanf(in, "%d", &a)!=EOF)
{
if (a >= v) sum++;
}
return sum;
}
void finded(FILE *in, int v)
{
rewind(in);
int a;
while (fscanf(in, "%d", &a)!=EOF)
{
if (a >= v)
cout << a << " ";
}
cout << endl;
}
int main()
{
int n, k;
cin >> n >> k;
FILE* in = fopen("dat.txt","r");
int min, max;
int a;
fscanf(in, "%d", &a);
min = max = a;
while (fscanf(in, "%d", &a)!=EOF)
{
if (a < min) min = a;
if (a > max) max = a;
}
while (max > min)
{
int mid = (min+max)/2;
int ns = binary(in, mid);
if (ns == k)
{
finded(in, (min+max)/2);
break;
}
else if (ns < k) max = mid;
else min = mid;
}
}
个数为几万亿时,数据量较大不适合全装入内存中,且无法容忍多次访问,所有数据只能访问一次,推荐使用最小堆法(上面那种情况也推荐使用这个方法),但要求K较小,否则无法在内存存下整个最小堆。
用容量为K的最小堆来存储最大的K个数,最小堆的堆顶元素就是最大K个数中最小的一个。每次考虑一个新的元素时,将其与堆顶的元素进行比较,只有当它大于堆顶元素时,才用其替换堆顶元素,并更新最小堆。时间复杂度为O(N*logK)。
[cpp] www.2cto.com
#include <iostream>
using namespace std;
#define MAXN 103
int H[MAXN];
void upshift(int s)
{
int tmp = H[s];
while (s>1 && H[s>>1] > tmp)
{
H[s] = H[s>>1];
s >>= 1;
}
H[s] = tmp;
}
void downshift(int n)
{
int tmp = H[1];
int i=1, j=i<<1;
while (j <= n)
{
if (j+1 <= n && H[j+1] < H[j]) j++;
if (H[j] < tmp) H[i] = H[j];
else break;
i = j;
j = j<<1;
}
H[i] = tmp;
}
int main()
{
int n, k, i, A;
cin >> n >> k;
for (i=1; i<=k; i++)
{
cin >> H[i];
upshift(i);
}
for (; i<=n; i++)
{
cin >> A;
if (A > H[1])
{
H[1] = A;
downshift(k);
}
}
for (i=1; i<=k; i++)
cout << H[i] << " ";
cout << endl;
}
作者:linyunzju
####################################################################
#include <iostream.h>
using namespace std;
####################################################################
####################################################################
####################################################################
####################################################################
####################################################################
####################################################################
- 找出第K大的数字
- 找出第k大的数字
- 找出第K大的数
- 找出第k大的数
- 找出第k大的数
- 找出第K大的数<数组>
- 找出第k大的数
- 算法之每日一题:找出无序数组中第k大的数字
- 【数据结构与算法分析】1.1 找出N个数字中第K大的数
- 寻找第K大的数字
- 寻找第K大的数字
- 寻找第K大的数字
- 无序数组找出其中的第K大的数
- 快速找出第K大的元素 (快速排序)
- 数组中找出第k大的值
- 找出第k大的数[No. 64]
- 找出数组中第K大的数值
- 数组中找出第k大的值
- gcc生成静态库和动态库
- 如何更有效地修改Android程序的开发包名
- vim 配置目录说明
- 索引列上计算引起的索引失效及优化措施以及注意事项
- 论文如何被EI收录
- 找出第K大的数字
- 【转载】关于C/C++ 表达式求值顺序
- history 命令显示时间记录
- 函数指针和指针函数的学习小结
- 如何将DIV层放在flash上面
- Android核心分析之(16)-- Android电话系统之概述篇
- 有关多线程问题
- 根据浏览者的IP切换成不同语言,新浪网易IP地区信息查询API接口调用方法
- 情人节必备工具——手机蓝牙灯


