(一)solr4.0 solr4.0,solr4.2,solr4.3, replica collection core shard slice 概念阐述
来源:互联网 发布:浙大gpa算法 编辑:程序博客网 时间:2024/04/30 22:49
来源:http://www.tnove.com/?p=33
本文适用于solr4.0,solr4.2,solr4.3,
solr4.0 正式发布有一段时间了,目前是BETA版,从ALpha版到beta新增加了collection的概念,本文就Solr4.0中的多个索引相关概念再做详细的说明。本文以beta版为基础
solr4.0 的所以继承Lucene的分段索引方式,采用了多shard的方式以提高在分布式云环境下的高性能要求的瓶颈。对于一个完整的文档集,将被分布到多个shard中进行索引存储,每个shard相对独立,有自己独立的indexwriter和searcher。shard是对完整文档集索引 分片(块)处理的体现,在solr的代码里每个shard都有一个solrCore对其维护管理。所以core是从solr代码的层面上讲的,而shard是从索引数据的分割角度来讲的。目前solr只允许一个core管理维护一个shard。
core 作为一个实例负责管理一个整个索引中的一个shard,对该shard进行索引的增删查改(update)。core是solr对索引单元管理的最小单位。而一个shard也拥有完整的lucene索引文件结构。几个shard的索引加在一起组成文档集的所有索引。
slice 是一组具有相同数据的shard构成的集合。通常建议3个shard作为一个slice,其中3个shard数据完全相同,但分布在不同的服务器上,以起到互相备份的作用,最终实现容灾和高可靠性的要求。如下图,一个两个服务器组成的solr 集群。该集群中只有一个collection(collection one),该collection中有两个slice,每个slice由2个shard构成。slice的两个shard分布在不同的服务器上以到达容灾目的。
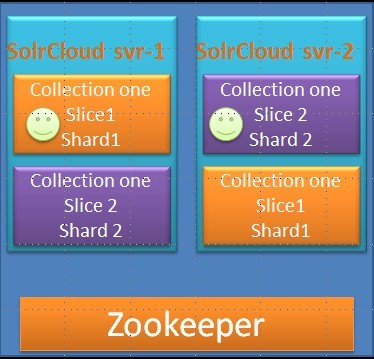
collection是一个逻辑的概念,用来组织多个slice。一个collection包含整个文档集的索引数据(完整)。collection的作用是为了实现多租户的功能。即多个用户(公司)要在一个solr集群上索引各自的数据。这样,各客户间的数据不能交叉,因为A客户的数据可能不希望让B客户访问。为了逻辑上和物理上隔离客户间的数据,产生了collection。一个collection索引并存放一个客户的数据。在一个collection里面又有多个silce。多slice保证吞吐量的要求(每个slice都可以处理索引请求并提供search服务)。
replica是shard的备份,目前1个shard就是一个replica。所以我们可以说每个slice有多个shard构成或者说多个replica构成。其中slice中的replica又有不同的职责,其中有且仅有一个作为主要的服务者,我们称其为leader replica 其他的备份的作为普通的replica。普通replica以 leader replica马首是瞻,保持与leader replica的同步。即普通replica索引的数据不能多于leader replica的索引。leader replica索引的增减直接影响普通replica的索引增减,普通 replica 向leader replica看齐,保持一致。如果当前某个leader replica死掉,将引发新的选举,产生新的leader replica,之后其他普通replica将向新的leader replica保持一致。
下面以一个具体部署的实例的admin工具看到的graph为例说明:

该集群由3台server组成。 只配置了1个collection(collection1),该collection 由 10 个slice组成。图中 的shard1~10实际上应该称作slice1~10 (该admin工具赋予的名称容易误导开发者)。而每个slice下面的每个圆圈表示一个replica,实心圆圈表示leader replica,空心为普通replica,灰色的圆圈表示死掉的replica(如服务器down掉)。 目前从图上可以看出,每个slice由3个replica 构成。(同个slice中的3个replica的数据相同,保存在不同的服务器上,起到备份作用)。
从shard的角度讲,1个replica里保存一份shard。1个slice中有一份唯一的shard(unique shard),但该shard有两个备份,同 unique shard 内容相同。
从core的角度讲,每个replica又一个core维护管理。core负责处理索引请求和搜索请求,以及该replica的索引文件管理,如merge等。所以该例子中总共有30个core,30个replica(其中10个leader replica),10个slice。30个core平均分布在3太server上,每个server10个core。每个server为每个slice保存了一份replica。 每个slice都有3份replica分别在不同的3个server上(X.X.X.251-253)。
当索引请求来了怎么处理,下一篇文章介绍。
- (一)solr4.0 solr4.0,solr4.2,solr4.3, replica collection core shard slice 概念阐述
- solr4.0 replica collection core shard slice 概念阐述 .
- solr4.0 replica collection core shard slice 概念
- Solrcloud/solr4.0/solr4.2/solr4.3/solr4.x (实时搜索)NRT及commit 相关问题
- Jenkins+Maven+SVN publish over ssh plugin--配置solr4.0/solr4.1/solr4.2/solr4.3 开发环境
- solr4.0环境搭建
- Solr4.0 SolrCloud概述
- Solr4.0 SolrCloud概述
- solr4.0环境搭建
- solr4.7新建core
- solr4.7新建core
- solr4.10新建core
- solr4.7新建core
- solr4.7新建core
- solr4.7新建core
- solr4.7新建core
- solr4.7新建core
- Solr4.3.1添加Core
- js的打字游戏的例子
- POJ 1305 勾股数组
- mount iso文件
- ArcGIS Engine10.0轻松入门级教程(5)——ArcEngine10.0三维开发
- js的百度的下拉框的例子
- (一)solr4.0 solr4.0,solr4.2,solr4.3, replica collection core shard slice 概念阐述
- DG3.1——逻辑备库说明
- Null component Catalina:type=JspMonitor,name=jsp,WebModule=//localhost/RixinWeb,J2EEApplication=non
- 第05章 数组 13 练习 11
- 可怜小女孩,模仿电视上吊死亡
- 触摸屏驱动一关键函数
- android中实现多个apk文件
- Unable to open log device '/dev/log/main': No such file or directory
- 51单片机和PC串口异步通信


