机器学习-笔记8
来源:互联网 发布:足球财富网数据频道 编辑:程序博客网 时间:2024/06/06 12:28
这是机器学习第8,9周内容的笔记,因为国庆的缘故有些耽误,所以两个部分放在一起总结归纳。
首先是聚类(Clustering),主要介绍的是K-Means算法,其实这个算法思想很简单,之前在《集体智慧编程》上面就了解过,这次补充学习了一些小细节。
算法的实质就是:(随机初始化聚点)
1、将样例的每个点分配给离它最近的那个聚点
2、统计所有同类点的中点,将聚点移到这个中点
重复1.2两个过程直到中心点不再变化,为了稳健可以多次算法选取最优的分类
大概过程如图所示:

一些值得注意的细节是,初始化的时候可以随机从样例中选择k个点作为初始聚点(k是据点数),k值的选取最好是人工选取,另一种兼容性较差的方法就是测试k值找到拐点(elbow):

接下来是数据降维(Dimensionality Reduction)
举个例子:3D-2D,就是在3D中选取一个平面,然后将所有的点映射到这个平面上,数据就变成了2D的了,我们需要做的就是选取一个对原数据影响最小平面,比较直观的就是点到平面的距离之和最小。这和liner regression的差别就是降维的cost fuction是垂线距离,而liner regression是参数的距离。
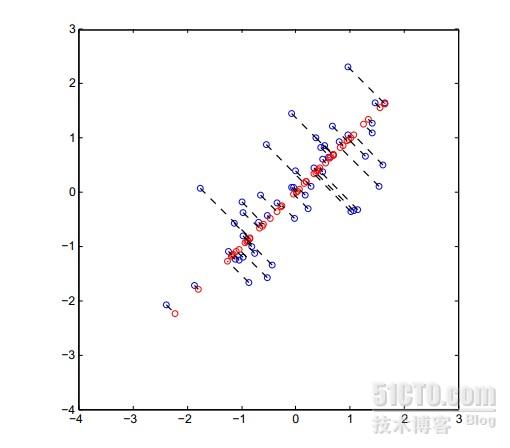
展示图片是2D-1D,蓝色为原数据点,红色为映射点。可以看出这种方法对数据是有影响的,但是只要在限定范围内,这种影响是可以接受的。
比较显著的一个实例就是ex7里面的图:

左边是原来的图片,右边是降维后再还原的图片。可以看出来至少不影响我们识别,降维处理对于高维数据的学习有非常大的作用。
具体算法是通过一个函数svd来实现的,奇异值分解(Singular value decomposition),具体的数学原理大家可以自己找找资料。


返回的U即是降维后的在高维中选择的向量,S用来计算降维后的数据失真度。

ex7中是要保证这样一个准确度
三:anomaly detection
anomaly detection就是给出一组数据,对于一个新的数据,让你判断这个数据是否异于总体的数据。
举例来说,

很明显越是远离中间的那一团点,就越是异常点,这个算法在智能控制登方面有很好的应用。
算法采用高斯分布(即正态分布)对样例进行学习,对于一个新的点通过它的概率来判断。

每一维的数据用一个正太分布函数表示,样例的概率即是所有维度的概率相乘。
最后通过之前学校过的F1 score来判断算法的优越性。
其后还介绍了一个multivariate的高斯分布函数,但是在练习中没有体现


可以说将数个高斯分布函数相乘是multivariate gaussian deviation的一个特例。
特例在每维的σ分别落在∑ 的对角线上,其它全部为0。
具体来说,矩阵Sigma控制图像的衍生,使图像可以斜着拉伸,使算法更智能

大概就是这些吧。课程已经学到了第九周,马上就要结束了。收获匪浅,感谢coursera,感谢Andrew ng。
本文出自 “DarkScope从这里开始(..” 博客,请务必保留此出处http://darkscope.blog.51cto.com/4254649/1020717
- 机器学习-笔记8
- 机器学习课堂笔记8
- OpenCV学习笔记(8)-机器学习
- 《机器学习》学习笔记
- 机器学习----学习笔记
- 机器学习学习笔记
- 机器学习 学习笔记
- 机器学习 学习笔记
- 机器学习 学习笔记
- 机器学习 学习笔记
- 机器学习 学习笔记
- 机器学习 学习笔记
- 机器学习 学习笔记
- 机器学习实战笔记8(kmeans)
- 机器学习笔记8——ERM
- 机器学习笔记(8)-树回归
- Tom机器学习笔记
- 【机器学习笔记】简介
- 机器学习-笔记5
- IDA*(迭代加深的A*算法) 八数码
- 机器学习-笔记6
- C++构造函数上的一点疑惑的解析
- 机器学习-笔记7
- 机器学习-笔记8
- 机器学习-笔记9-总结
- codec engine代码阅读五---CE_DIR/examples/ti/sdo/ce/examles/servers/video_copy
- 总结和规划
- mysql数据类型简介
- codec engine代码阅读六---CE_DIR/examples/ti/sdo/ce/examles/apps/video_copy
- 趣文:通俗解释主要编程语言及其用途
- Android 学习论坛博客及网站推荐(转载)
- codec engine代码阅读七---codecs中的xDM,XDAIS函数解析


