获取HTML网页内容SgmlReader
来源:互联网 发布:sql注入的步骤 编辑:程序博客网 时间:2024/05/09 22:32
Microsoft的XML大师Chris Lovett发布了一个新的SGML解析器(应该是2008年的版本),叫做SgmlReader(早期的SgmlReader在2006年以前就出了),它可以解析HTML文件,甚至将它们转换成一个格式规范的结构。SgmlReader派生于XmlReader,这就是说,你可以像运用诸如XmlTextReader这样的类来解析XML文件那样来解析HTML文件。
说明+最新源码:http://developer.mindtouch.com/en/docs/SgmlReader
备用源码地址:http://archive.msdn.microsoft.com/SgmlReader
也可参考:http://www.xmlforasp.net/codeSection.aspx?csID=94
将其实际应用的结果如图:
1. 示例网页(我们需要获取的):
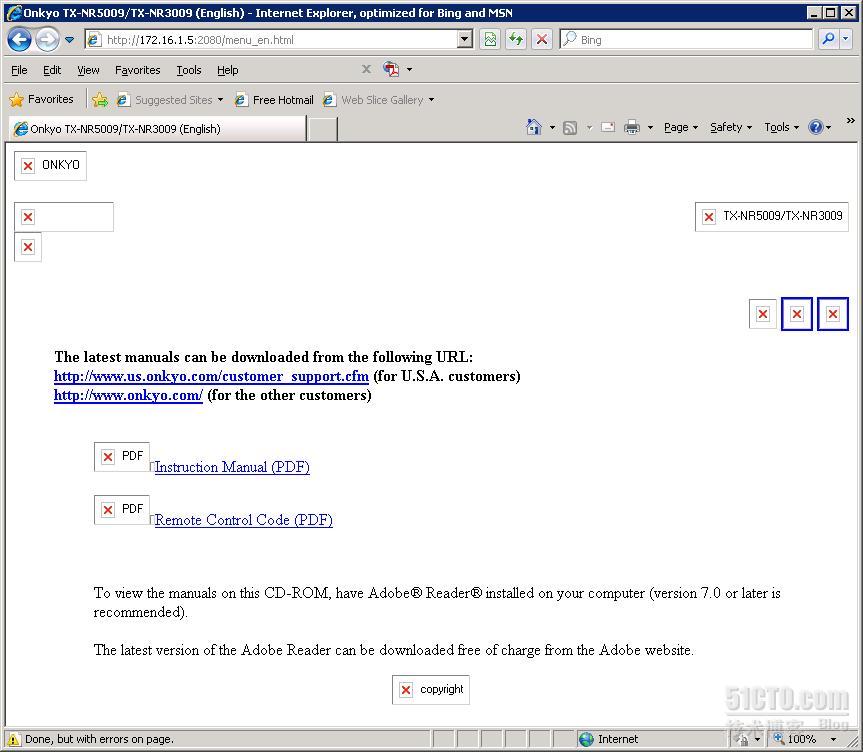
2. 获取<body>内所有标签的值
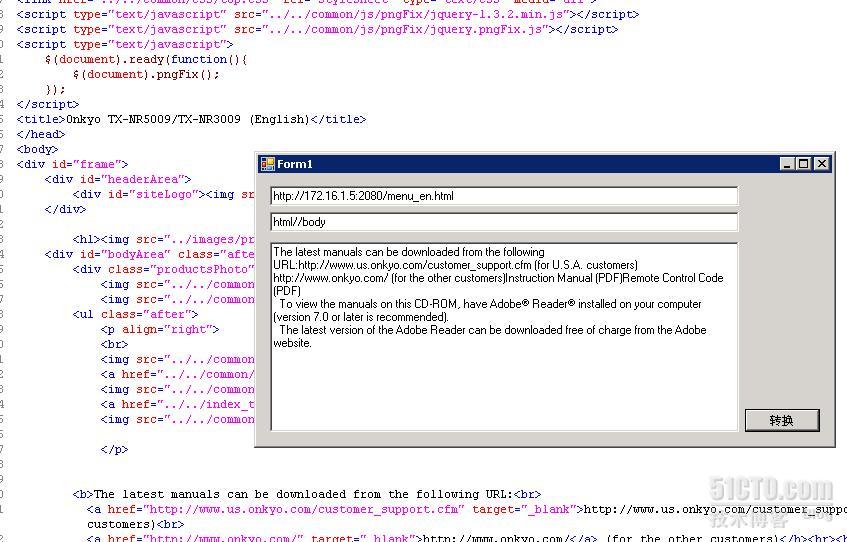
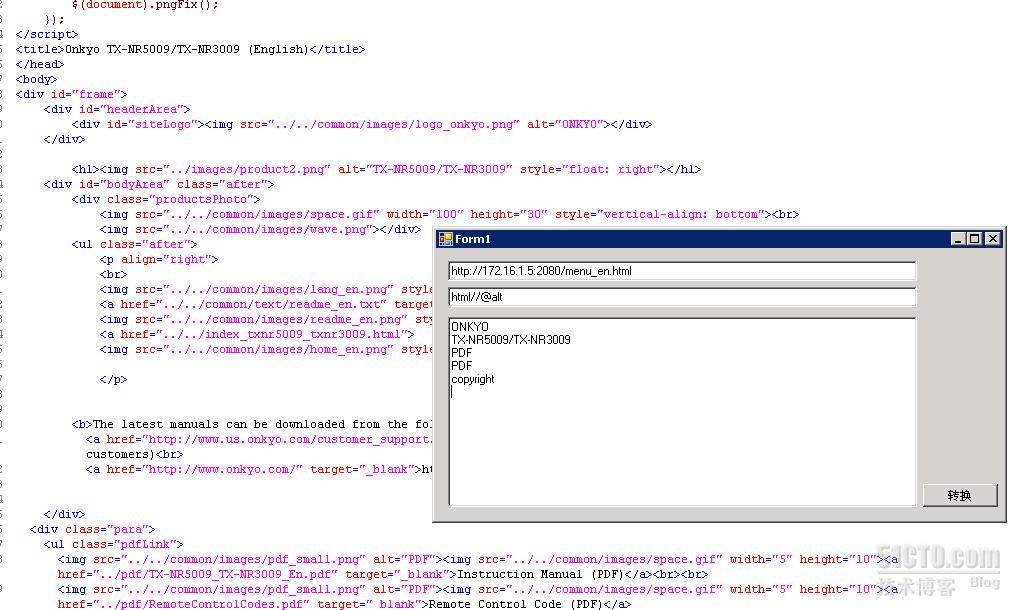
3. 获取<html>内所有alt属性值(图片提示信息)
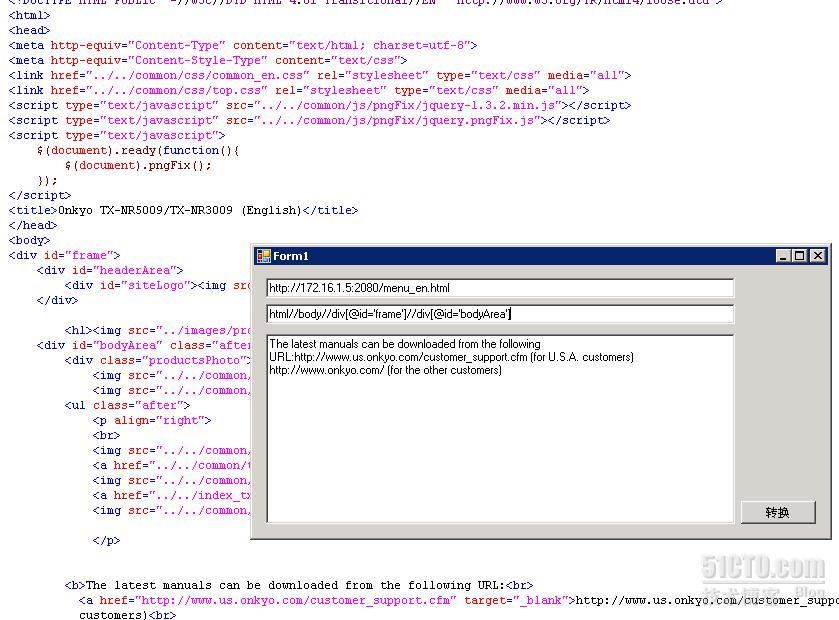
4. 获取<body>内<div>标签属性id为"frame"下,<div>标签属性id为"bodyArea",层内所有标签值
5. 以上示例都是获取远端HTML页面(http://172.16.1.5/menu_en.html)源码内容的示例,以下是获取本地HTML内标签值示例。

- private string GetWellFormedHTMLFile(string filePath, string xpath)
- {
- StreamReader sReader = null;
- StringWriter sw = null;
- SgmlReader reader = null;
- XmlTextWriter writer = null;
- try
- {
- sReader = new StreamReader(filePath);
- reader = new SgmlReader();
- reader.DocType = "HTML";
- reader.InputStream = new StringReader(sReader.ReadToEnd());
- sw = new StringWriter();
- writer = new XmlTextWriter(sw);
- writer.Formatting = Formatting.Indented;
- //writer.WriteStartElement("Test");
- while (reader.Read())
- {
- if (reader.NodeType != XmlNodeType.Whitespace)
- {
- writer.WriteNode(reader, true);
- }
- }
- //writer.WriteEndElement();
- if (xpath == null)
- {
- return sw.ToString();
- }
- else
- { //Filter out nodes from HTML
- StringBuilder sb = new StringBuilder();
- XPathDocument doc = new XPathDocument(new StringReader(sw.ToString()));
- XPathNavigator nav = doc.CreateNavigator();
- XPathNodeIterator nodes = nav.Select(xpath);
- while (nodes.MoveNext())
- {
- sb.Append(nodes.Current.Value + ((char)13).ToString());
- }
- return sb.ToString();
- }
- }
- catch (Exception exp)
- {
- writer.Close();
- reader.Close();
- sw.Close();
- sReader.Close();
- return exp.Message;
- }
- }
- 获取HTML网页内容SgmlReader
- C# 获取HTML网页内容SgmlReader
- 获取html网页的内容
- java获取网页html内容。。。。。。。
- Winnet获取网页HTML内容-Code
- 使用XPath解析HTML获取网页内容
- html 获取黏贴的网页内容
- 利用SgmlReader来解析HTML
- telnet建立http连接获取网页HTML内容
- telnet建立http连接获取网页HTML内容
- 获取WebView加载HTML时网页中的内容
- js获取网页选中部分的内容,包含html代码
- HTMLPARSER 爬取 html网页 获取标题 关键字 内容 url
- 获取WebView加载HTML时网页中的内容
- 【Jsoup】HTML解析器,轻松获取网页内容
- 获取WebView加载HTML时网页中的内容
- C# 获取指定HTML网页中的标签内容
- PHP获取HTML网页内容的多种方法(精)
- MySql乱码总结
- cmd下如何运行.exe文件
- poj 1002 487-3279(基础模拟题)
- HDU 2553 N皇后问题 深搜-dfs
- 数据挖掘导论课后习题第二章习题,此篇不断更新中直到本章所有习题全部完成
- 获取HTML网页内容SgmlReader
- SgmlReader使用小记
- 黑马程序员-IO
- STM32 时钟分布
- 我的人生-感悟
- java 动态代理
- Codeforces Round #165 (Div. 2)(完全)
- CodeBlocks中文版使用手册
- 《Algorithms》第8章:NP完全问题 学习笔记


