希尔排序
来源:互联网 发布:春纪护肤品怎么样知乎 编辑:程序博客网 时间:2024/05/16 06:22
#include <iostream>using namespace std;void shellsort(int a[],int n){int i,j,gap;gap = n/2;while(gap > 0){for(i = gap;i < n;i++){int temp = a[i];for(j = i;j >= gap && a[j - gap] > a[j];j -= gap){a[j] = a[j - gap];}a[j] = temp;}gap /= 2;}}int main(int argc, char const *argv[]){int a[] = {1,4,2,1,4,1,55,3};int len = sizeof(a)/sizeof(int);shellsort(a,len);for(int i=0;i<len;i++){cout<<a[i]<<" ";}cout<<endl;return 0;}步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作。算法最开始以一定的步长进行排序。然后会继续以一定步长进行排序,最终算法以步长为1进行排序。当步长为1时,算法变为插入排序,这就保证了数据一定会被排序。
Donald Shell 最初建议步长选择为 并且对步长取半直到步长达到 1。虽然这样取可以比
并且对步长取半直到步长达到 1。虽然这样取可以比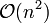 类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。 可能希尔排序最重要的地方在于当用较小步长排序后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长5进行了排序然后再以步长3进行排序,那么该数列不仅是以步长3有序,而且是以步长5有序。如果不是这样,那么算法在迭代过程中会打乱以前的顺序,那就不会以如此短的时间完成排序了。
类的算法(插入排序)更好,但这样仍然有减少平均时间和最差时间的余地。 可能希尔排序最重要的地方在于当用较小步长排序后,以前用的较大步长仍然是有序的。比如,如果一个数列以步长5进行了排序然后再以步长3进行排序,那么该数列不仅是以步长3有序,而且是以步长5有序。如果不是这样,那么算法在迭代过程中会打乱以前的顺序,那就不会以如此短的时间完成排序了。
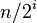
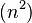
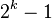

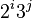
已知的最好步长序列是由Sedgewick提出的 (1, 5, 19, 41, 109,...),该序列的项来自 9 * 4^i - 9 * 2^i + 1 和 4^i - 3 * 2^i + 1 这两个算式[1].这项研究也表明“比较在希尔排序中是最主要的操作,而不是交换。”用这样步长序列的希尔排序比插入排序和堆排序都要快,甚至在小数组中比快速排序还快,但是在涉及大量数据时希尔排序还是比快速排序慢。
另一个在大数组中表现优异的步长序列是(斐波那契数列除去0和1将剩余的数以黄金分割比的两倍的幂进行运算得到的数列):(1, 9, 34, 182, 836, 4025, 19001, 90358, 428481, 2034035, 9651787, 45806244, 217378076, 1031612713, …)[2]
可以参考:http://blog.csdn.net/morewindows/article/details/6668714
http://zh.wikipedia.org/wiki/%E5%B8%8C%E5%B0%94%E6%8E%92%E5%BA%8F
http://blog.chinaunix.net/uid-24467128-id-3229221.html
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 希尔排序
- 判断给定数组是否是二叉树的前序或者后序遍历结果
- 如果你很迷茫,就好好读读这8句话
- 我的Android进阶之旅------>Android电话窃听实例
- javascript动态创建table
- java 执行shell
- 希尔排序
- 【算法导论笔记】模糊排序7-6
- 使用BoundsChecker查找内存泄露
- C语言第六堂课后作业
- HDU1003 Max Sum && HDU1024 Max Sum Plus Plus
- 今日总结 4月9日
- 磁盘IO:缓存IO、直接IO、内存映射
- C++内存管理
- PHP高效率写法(详解原因)


