常用数据结构与算法:二叉堆(binary heap)
来源:互联网 发布:mysql 修复表 编辑:程序博客网 时间:2024/06/07 09:46
一:什么是二叉堆
二:二叉堆的实现
三:使用二叉堆的几个例子
一:什么是二叉堆
1.1:二叉堆简介
二叉堆故名思议是一种特殊的堆,二叉堆具有堆的性质(父节点的键值总是大于或等于(小于或等于)任何一个子节点的键值),二叉堆又具有二叉树的性质(二叉堆是完全二叉树或者是近似完全二叉树)。当父节点的键值大于或等于(小于或等于)它的每一个子节点的键值时我们称它为最大堆(最小堆)。
二叉堆多数是以数组作为它们底层元素的存储,根节点在数组中的索引是1,存储在第n个位置的父节点它的子节点在数组中的存储位置为2n与2n+1。可以借用网上的一幅图来标示这种存储结构。其中数字表明节点在数组中的存储位置。
1 / \ 2 3 / \ / \ 4 5 6 7 / \ / \ 8 9 10 11
1.2:二叉堆支持的操作
二叉堆通常支持以下操作:删除,插入节点,创建二叉堆。这些操作复杂对都是O(log2n)
二叉堆也可以支持这些操作:查找。O(n)复杂度。
1.3:二叉堆的特点
二叉堆是专门为取出最大或最小节点而设计点数据结构,这种数据结构在查找一般元素方面性能和一般数组是没有多大区别的。二叉堆在取出最大或最最小值的性能表现是O(1),取出操作完成之后,二叉堆需要一次整形操作,以便得到下一个最值,这个操作复杂度O(log2n)。这是一个相当理想的操作时间。但是二叉堆也有一个缺点,就是二叉堆对存储在内存中的数据操作太过分散,这导致了二叉堆在cpu高速缓存的利用与内存击中率上面表现不是很好,这也是一个二叉堆理想操作时间所需要付出的代价。
1.4:二叉堆的使用范围
二叉堆主要的应用击中在两个地方一个是排序,一个是基于优先级队列的算法。比如:
1:A*寻路
2:统计数据(维护一个M个最小/最大的数据)
3:huffman code(数据压缩)
4:Dijkstra's algorithm(计算最短路径)
5:事件驱动模拟(粒子碰撞。这个比较有意思,从国外的一个网站看到过)
5:贝叶斯垃圾邮件过滤(这个只是听过没怎么了解)
二:二叉堆的实现
2.1:插入
当我们要在二叉堆中插入一个元素时我们通常要做的就是有三步
1.把要插入的节点放在二叉堆的最末端
2.把这个元素和它的父节点进行比较,如果符合条件或者该节点已是头结点插入操作就算完成了
3.如果不符合条件的话就交换该节点和父节点位置。并跳到第二步。
假设我们有一个如下的最大二叉堆,圆圈内数字代表的是节点,x代表节点插入位置,我们要插入的值是15,则步骤如下:
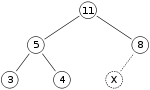
我们插入的位置为X,X的父节点是8,X与8进行比较,发现X(15)大于8于是8与15互换。
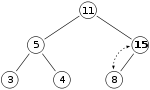
X(15)接着和11比较,发现15比11大于是互换。
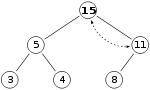
15已经是头结点操作插入操作结束。
插入节点不停向上比较的过程叫做向上整形。
void insert(Data data) {if(_last_index==0) //我们的数组从index 1,我们用第一个插入的数填充index 0.{_array.push_back(key);}_array.push_back(data); //将key插入数组最末swim_up(++_last_index); //对最后一个插入的数字进行向上整形}void swim_up(size_type n) //向上整形{size_type j; //n 代表向上整形的元素,j代表n的父节点while( (j = n / 2) > 0 && compare(_array[n], _array[j]) ) //判断n父节点是否为空&比较n与j大小{exchange(n, j);n=j;}}2.2:删除
二叉堆的删除操作指的是删除头结点的操作,也就是最小或者最大的元素。删除操作分为三步:
1.首先将头结点与最后一个节点位置互换(互换之后的最后一个节点就不再视为二叉堆的一部分)。
2.将互换之后的新的头结点与子节点进行比较,如果符合条件或者该节点没有子节点了则操作完成。
3.将它和子节点互换,并重复步骤2。(如果它的两个子节点都比它大/小,那么它与其中较大/小的一个互换位置。最大堆的话与较大的互换,最小堆的话与较小的互换。)
假设我们有如下一个最大堆,圆圈内数字表示节点的值:

现在我们删除头结点11,我们将11头结点与最末一个节点4互换。
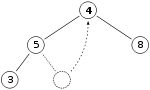
互换之后我们剔除了最后一个节点。我们将4与它的子节点进行比较,发现它比它的两个节点都小,不满足条件跳到步骤3。

我们将4与它的子节点中较大的一个进行互换(最小堆则和最小的一个互换)。然后继续进行步骤2,但是我们发现节点4已经没有子节点于是操作结束。
这个不停向下比较的操作我们称作向下整形。
const T& get_min() //不允许修改值,这样会造成堆被破坏. { return _array[1]; } void pop_min() //如果没有数据在队列中,这个行为是未定义的. { _array[1]=_array[_last_index--]; _array.pop_back(); sink_down(1); } void sink_down(size_type n) { size_type j; //j 是 n的子节点的索引 while( ( j = 2 * n) <= _last_index ) { if( j + 1 <= _last_index && _compare(_array[j+1],_array[j]) ) //比较两个子节点,取出其中较小的. j=j+1; if( _compare(_array[j],_array[n]) ) //较小的子节点与父节点进行比较 exchange(n,j); n=j; } }2.3:构建二叉堆
构建二叉堆很简单只要我们把要构建的元素一个一个的进行插入操作插入到二叉堆中即构建了一个二叉堆。
2.4:堆排序
堆排序其实分为以下几步:
1:首先将待排序的n个元素构建一个二叉堆array[n]
2:执行删除操作,只是这里我们并不是删除头结点,而是将头结点换到二叉堆末尾,并形成一个出去队列末尾的新二叉堆。
3:重复步骤2,直到删除了最后一个元素。
这个过程其实就是先构建一个最大/最小二叉堆,然后不停的取出最大/最小元素(头结点),插入到新的队列中,以此达到排序的目的。观察下面这个从wiki上面截取的gif图。

这幅图描述的是一个最大堆,柱子的高度代表了元素的大小,可以看出不停的把头结点换到新形成的二叉堆的最末,然后就形成了一个有序队列。
三:使用二叉堆的例子
A*寻路:
这里只是举一个相对于来说比较简单的例子,用A*寻路来解决8-PUZZLE(8格数字拼图),当然更为经典的一种是15-puzzle,它们道理都是一样的。下面来看看这个问题的描述。
在一个九宫格里面,有1-8 8个数字和一个空格,我们可以移动空格上下左右相邻的数字到空格,然后通过这种移动方式我们最终要求9宫格里面的数字,形成1-8的顺讯排列。类似如下
1 3 1 3 1 2 3 1 2 3 1 2 34 2 5 => 4 2 5 => 4 5 => 4 5 => 4 5 67 8 6 7 8 6 7 8 6 7 8 6 7 8
初始 第1次移动 第2次移动 第3次移动 第4次移动
这个问题在我小时候玩图片拼板的时候很难,几乎很久都拼不成功,但是我们只要找到决窍就行了。有两种诀窍是广泛使用的一种称作Hamming priority function,而另外一种就是Manhattan priority function。这里我们使用更为广泛使用的Manhattan方法作为讲解。
Manhattan方法:我们用这个9宫格里面每个数字到达自己指定位置的距离加上我们目前总共移动的步数来表示一个度量值M。这里所指的每个数字到达自己指定位置的距离指的是通过横向移动和纵向移动到达自己规定位置的距离。举例:
1 3
4 2 5
7 8 6
在这里图中数字“1”在位置1上于是距离为0。数字“3”到达自己的指定位置需要右移一步于是距离为1,“4"在位置4上于是距离为0,"2"需要向上移动一步到达自己的制定位置距离为1,”5“需要左移一步距离为1,”7“”8“在指定位置上距离0,6需要向上移动一步距离1,于是这个图形的总距离为4。
我们从上图的”初始“状态开始,有两种移动方法,一种是”3“移动到空格,一种是”5“移动到空格。我们应该选择哪种移动方法呢,这个时候就需要使用我们刚才所说的度量值了,我们选择度量值小的一种移动方式。”3“移动到空格的方法距离3,移动步数1,度量值M=4。”5“移动到度量空格的距离5,移动步数为1,度量值M=6。我们选择”3“移动到空格的这种方式。这里的具体过程是我们把记录下“3”和“5”移动的这两种节点的父节点,然后分别计算他们的M值,然后放入到min bianry heap中,取出最小M值节点作为移动节点,并从min binary heap中删除这个节点。
1 3 1 3 54 2 5 4 2 7 8 6 7 8 6"3"移动到空格,M=4 “5”移动到空格,M=6
当我们选出了第一次的移动节点之后,我们就要在第一次的移动节点上再决定下一次的移动节点,下一次怎么走一共有3+1种节点,3种是基于上一次移动后我们新加入的移动节点,1种是上一次我们并没有沿用的移动节点,我们计算3种新节点的M值并记录他们的父节点然后再把它们加入取出最小的作为下一次的移动节点,直到我们得到距离等于0的节点位置。
当我们找到距离等于0的节点之后,我们递归查找该节点父节点直到查找到根节点位置,这个查找的顺续的逆序便是我们移动节点到达最终目的地的顺序
这里有一个A*寻路中需要注意的地方,我们并不会删除我们没有沿用的节点,而是仍然留住它在min binary heap中作为备选节点以防现有路线不是最优解或是不能到达终点。
这种数字拼盘程序还有一种非常值得注意的地方,即是这种数字拼盘总是存在着一种无法求解的可能,比如8-puzzle中,这种排序和它的变种都无法解:
1 2 3
4 5 6
8 7
面对这种难题,有一种较为合理的解决方法来判断,我们只需要交换我们初始节点中同一排的相邻两个节点位置(两个都为非空节点)得到另外一种初始化节点,在这两种方案中只有一种方案能够解。所以我们只需要同时计算两种初始节点,只要其中一个得出解了那么另外一个即可以判断是无解的了。
好奇的你或许会问为什么交换了同一排相邻的两个非空节点的位置之后,新得到的节点的可解性与旧节点的可解性相反。这个问题严谨的数学解释需要参考较早的研究论文,并且对于非专业学生也比较晦涩难懂。我能想到的比较容易解释方式及是“同一排两个节点交换了位置之后,你永远也无法通过移动还原到交换前的模样。”这也即是
1 2 3 1 2 3 4 5 6 得不到=>4 5 6 的原因。8 7 7 8
实现:
下面是这个8-puzzle问题的代码实现,零零散散写了2,3百行的code,写得比较随意,代码的泛型没有做,所以暂时只支持8-puzzle问题的求解,但是只要稍微改动下就能支持n puzzle问题了。因为写的较快,注释暂时忽略了.........。代码的输出在标准输出上,运用了上面讲到的技术判断不能求解的情况,二叉堆底层使用的vector,支持泛型。
代码下载地址
- 常用数据结构与算法:二叉堆(binary heap)
- 数据结构与算法12: 二叉堆(Binary Heap)
- 【数据结构与算法基础】优先队列(二叉堆实现) / Priority Queue implemented by binary heap
- 数据结构之Binary Heap(二叉堆)
- 数据结构与算法分析(Java语言描述)(11)—— 二叉堆(Binary Heap)
- Binary Heap(二叉堆)
- 二叉堆-Binary heap
- 二叉堆(Binary Heap)
- [数据结构与算法]堆排序 Heap Sort
- 二叉堆(Binary heap)
- 【数据结构与算法】二叉堆
- 《数据结构与算法分析》二叉堆详解
- 数据结构与算法——二叉堆
- 数据结构与算法分析-优先队列 堆(heap)
- 数据结构 之 二叉堆(Heap)
- 二叉堆 build算法 c++ 数据结构与算法
- 部分GNU代码片 10、二叉堆(Binary Heap)
- 02. 优先队列-二叉堆(Binary Heap)
- c++实现数据结构六 链式栈
- netfilter按端口过滤报文
- Oracle 视图
- hadoop自定义文件的输入格式
- Android开发新手HelloWorld解析
- 常用数据结构与算法:二叉堆(binary heap)
- strcpy的缺陷和改进
- 堆和栈,队列的区别
- javascript 数值操作
- Java Url 编码
- Android游戏开发十日通(3)-创建第一个Android游戏
- ArcGIS for Android 之Geocode查询的实现
- linux c 日期 转化成 秒
- socket入门学习 作者:吴秦


