搜索之BM25 转
来源:互联网 发布:成都知美术馆官网 编辑:程序博客网 时间:2024/05/05 22:48
- 一直没有提到用户查询词,它到哪里去了呢?这里我们认为查询词给出了相关文档的信息。我们假定不在query中的单词在相关于不相关文档中的概率是相同的。因此我们只需要考虑在query中的词即可,不在的词不会对结果产生影响,log(1) = 0。
- 如果我们没有其它的反馈来支持我们的相关文档信息,那么我们假定单词i在相关文档中的概率为0.5。
- 大部分文档是无关文档 NR 近似等于 N,我们认为单词在不相关文档中出现的概率即为它在所有文档中出现的概率,也就是它在整个文档集合中出现的次数n(i) (注意每个文档对n(i)的贡献是0或者1),除以整个文档集合数目N。

(呃,看出来了吧,整了半天就是类似idf的东西,就是说文档中包含查询词中的词越多,分值越高,而每个查询词带来的贡献量是按照idf度量的。。。)
- 如果我们有反馈信息呢,即我们知道有R个相关文档,N-R个不相关文档,其中单词i在所有文档中有n(i)个文档包含它,没出现它的文档有N-n(i)个,R个相关文档中有r(i)个文档包含单词i,有R-r(i)个相关文档不包含i,在N-R个不相关文档中有n(i) – r(i)个包含单词i,有N-R-n(i) + r(i)个文档不包含单词i。于是p(i) = r(i) / R, s(i) = (n(i) – r(i))/(N – R),为了避免不出现单词带来0概率情况,比如r(i)等于0,平衡之我们采用分子+0.5,分母+1,p(i) =( r(i) + 0.5 )/( R + 1 ) , s(i) = (n(i) – r(i) + 0.5)/(N – R + 1)。
- 代入公式我们最终得到,注意这个公式如果无相关文档R == 0, r(i) == 0,就和3公式一致。//注打不出+ // 表示 + :( ,注意query可以被扩展,利用反馈的相关文档中的关键词。

这个公式效果怎么样?很差,因为类似只考虑idf,而不考虑tf,但是这个公式是BM25算法
. BM25算法
BM25是二元独立模型的扩展,其得分函数有很多形式,最普通的形式如下:
∑
其中,k1,k2,K均为经验设置的参数,fi是词项在文档中的频率,qfi是词项在查询中的频率。
K1通常为1.2,通常为0-1000
K的形式较为复杂
K=
上式中,dl表示文档的长度,avdl表示文档的平均长度,b通常取0.75
2. BM25具体实现
由于在典型的情况下,没有相关信息,即r和R都是0,而通常的查询中,不会有某个词项出现的次数大于1。因此打分的公式score变为
∑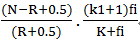
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
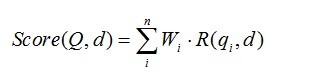
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
下面我们来看如何定义Wi。判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
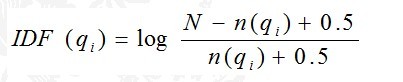
其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
我们再来看语素qi与文档d的相关性得分R(qi,d)。首先来看BM25中相关性得分的一般形式:
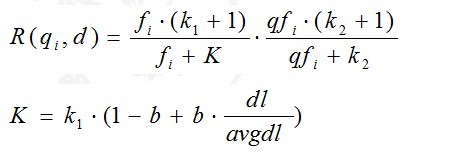
其中,k1,k2,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。dl为文档d的长度,avgdl为所有文档的平均长度。由于绝大部分情况下,qi在Query中只会出现一次,即qfi=1,因此公式可以简化为:
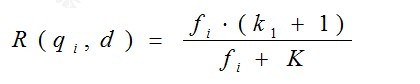
从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:
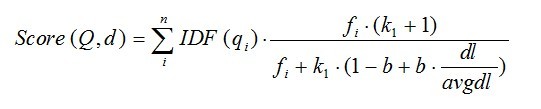
从BM25的公式可以看到,通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。
参考资料:
1. Project2--Lucene的Ranking算法修改:BM25算法
2. Okapi BM25算法详解
3. 谈谈BM25评分
- 搜索之BM25 转
- 搜索之BM25和BM25F模型
- 搜索相似之——BM25算法
- 搜索领域BM25算法
- BM25算法[转]
- BM25算法 [转]
- [转]OKapi BM25 算法
- BM25
- BM25
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- BM25算法
- 稳压管的使用与选取
- http详解
- Java中运行动态脚本Groovy
- 查找之二分查找
- 【Windows8系统与Win7的区别】
- 搜索之BM25 转
- 门户待办任务显示太多,如何提高性能
- Visual Studio + VAssistX常用快捷键
- 廉政公署如何查前一哥
- iPhone开发之 - 苹果推送通知服务(APNs)编程
- 中国足球是当今社会的缩影
- 公务员晋升解读 35岁是关键
- Cocos2dx------touch事件
- Memcached windows 下安装与测试


