排序算法理论与总结
来源:互联网 发布:纲鉴易知录 知乎 编辑:程序博客网 时间:2024/04/29 15:18
1. 前言
排序和查找是计算机科学中非常重要的一个课题,也是处理事务时常遇到的问题。可以说排序和查找是程序员必须掌握的基础知识。当前排序算法所要处理的问题特点:
(1)数据量大
(2)数据分布不集中
2. 排序的基本思想
一个优秀的排序算法必须遵循的思想:分而治之(Divide-Conquer-Merge)
首先对数据进行分块(Divide),然后对每一块排序(Sort),最后每一块合并(Merage)。
当然,其中还有很多可以优化的地方(这正是优秀的排序算法的由来)。比如对分块,如果能保证块间是有序的,那么岂不是省略了排序这一阶段,因为当块大小为1的时候,数据就已经有序了。(快排)
因此,Sort可能不是独立的,而是贯插于Divide和Merage当中。
3. 算法分类
分类基础排序O(n^2)
高级排序O(nlogn)
交换冒泡排序快排插入插入排序希尔选择选择排序堆排序
对于3种基础排序来说可以说几乎没有优化,其时间复杂度为O(n^2)。
对于高级排序来说都采用了分而治之的思想。其时间复杂度为O(nlogn)。
4. 算法的稳定性
稳定性:

如图所示:排序后两张5仍然保持原来的顺序,那么这个排序算法就是稳定的。
5. 算法评价
5.1O(n)
参见:算法分析O(n), O(nlogn)...5.2 时间复杂度
算法的评价包括2个方面:空间复杂度和时间复杂度。
随着计算机存储的发展,空间复杂度带来的代价大大降低(当然不是完全不考虑,随着大数据的发展,空间复杂度日益重要),所以着重考虑时间复杂度。
时间复杂度包括:比较次数,移动次数。为了便于算法分析,约定每一次比较和移动的消耗都是1个单位(当然: 移动的单位>比较的单位)。
各个算法的平均复杂度:
冒泡排序 O(n2)
插入排序 O(n2)
选择排序 O(n2)
归并排序 O(n log n)
堆排序 O(n log n)
快速排序 O(n log n)
希尔排序 O(n1.25)
基数排序 O(n)
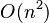
 (有序区,无序区)。把无序区的第一个元素插入到有序区的合适的位置。对数组:比较得少,换得多。直接选择排序数组(有序区,无序区)。在无序区里找一个最小的元素跟在有序区的后面。 对数组:比较得多,换得少。链表
(有序区,无序区)。把无序区的第一个元素插入到有序区的合适的位置。对数组:比较得少,换得多。直接选择排序数组(有序区,无序区)。在无序区里找一个最小的元素跟在有序区的后面。 对数组:比较得多,换得少。链表 (最大堆,有序区)。从堆顶把根卸出来放在有序区之前,再恢复堆。归并排序数组、链表
(最大堆,有序区)。从堆顶把根卸出来放在有序区之前,再恢复堆。归并排序数组、链表 , 如果不是从下到上把数据分为两段,从两段中逐个选最小的元素移入新数据段的末尾。可从上到下或从下到上进行。快速排序数组
, 如果不是从下到上把数据分为两段,从两段中逐个选最小的元素移入新数据段的末尾。可从上到下或从下到上进行。快速排序数组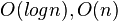 (小数,枢纽元,大数)。Accum qsort链表(无序区,有序区)。把无序区分为(小数,枢纽元,大数),从后到前压入有序区。 决策树排序
(小数,枢纽元,大数)。Accum qsort链表(无序区,有序区)。把无序区分为(小数,枢纽元,大数),从后到前压入有序区。 决策树排序 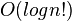
 O(n) <O(logn!) <O(nlogn) 计数排序数组、链表
O(n) <O(logn!) <O(nlogn) 计数排序数组、链表
 统计小于等于该元素值的元素的个数 i,于是该元素就放在目标数组的索引 i位。(i≥0)桶排序数组、链表
统计小于等于该元素值的元素的个数 i,于是该元素就放在目标数组的索引 i位。(i≥0)桶排序数组、链表 将值为 i 的元素放入i 号桶,最后依次把桶里的元素倒出来。基数排序数组、链表
将值为 i 的元素放入i 号桶,最后依次把桶里的元素倒出来。基数排序数组、链表 ,最坏: 一种多关键字的排序算法,可用桶排序实现。
,最坏: 一种多关键字的排序算法,可用桶排序实现。- 均按从小到大排列
- k 代表数值中的"数位"个数
- n 代表数据规模
- m 代表数据的最大值减最小值
6. 参考
(1)排序算法
(2)data structures and algorithm analysis in c++
- 排序算法理论与总结
- 排序算法理论与总结
- 理论---排序算法
- 排序算法总结与思考
- 【数据结构与算法】【排序】总结
- 排序算法总结与实现
- 排序算法总结与实现
- 数据结构与算法-排序总结
- 算法--简单排序算法总结与模板
- 《数据结构与算法分析》排序算法总结
- 【数据结构与算法】-常见排序算法总结
- 【数据结构与算法】【排序算法】排序算法总结
- 算法与数据结构-常用排序算法总结1-比较排序
- 算法与数据结构-常用排序算法总结2-计数排序
- 算法与数据结构-常用排序算法总结2-桶排序
- Java常用排序算法冒泡排序与选择排序总结
- A*算法理论与实践
- A*算法理论与实践
- 窗口子类化三:SubClassWindow详解
- Houdini下的俄罗斯方块(一)
- ubuntu下source、sh、bash、./执行脚本的区别
- Linux中断(interrupt)子系统之一:中断系统基本原理
- 飞思卡尔单片机DZ60---SCI(查询接收)
- 排序算法理论与总结
- busybox中ash对全局环境变量/etc/profile文件的处理
- 类的继承性
- mmc与sd的不同
- 探讨一下关于在线播放阻止用户下载你的MP3的问题
- ubuntu linux 备份与恢复
- 整理关于JVM方面的知识点
- 给定链表的头指针和一个结点指针,在O(1)时间删除该结点
- Linux中断(interrupt)子系统之二:arch相关的硬件封装层


