数据库--高阶--通用Oracle、MS SQL和Mysql
来源:互联网 发布:寻求淘宝合作伙伴 编辑:程序博客网 时间:2024/04/30 01:20
1 IN 和 EXISTS
IN 是把外表和内表作hash 连接,
exists是对外表作loop循环,每次loop循环再对内表进行查询。
一直以来认为exists比in效率高的说法是不准确的。
测试:A表102806条,B表1283条
语句示例:
select uid from A where uid in(select uid from B)select uid from A where exists(select uid from B where uid=A.uid)
语句 外表 内表 时间(s)
-----------------------------------------------------------------
IN A B 1.115EXISTS A B 1.498
-----------------------------------------------------------------
IN B A 1.092EXISTS B A 0.016
-----------------------------------------------------------------
NOT IN A B 0.843NOT EXISTS A B 1.42
-----------------------------------------------------------------
NOT IN B A 1.076NOT EXISTS B A 0.187
=========================================================
外表>内表 IN 和NOT IN略好内表>外表 EXISTS和NOT EXISTS
当然,并不是绝对的。2 Java向Mysql Oracle输入日期
一方面了解Java和数据库的日期格式对应
示例:(不完全例子,可以有其他方法)
String sql = "INSERT INTO wp_posts ( post_date )VALUES(?)"; PreparedStatement pstmt = connection.prepareStatement(sql); Timestamp time = new Timestamp(System.currentTimeMillis()); pstmt.setTimestamp(1, time);//或者pstmt.setDate(10, new java.sql.Date(System.currentTimeMillis())); // 只有日期pstmt.setTime(11, new Time(System.currentTimeMillis())); // 只有时间pstmt.setTimestamp(12, new Timestamp(System.currentTimeMillis())); // 日期和时间
3 子查询
所有的子查询分为相关子查询和独立子查询,其中独立子查询可以独立运行。
子查询的结果可以是单值,多行单列的值 || 单行数据,多行数据。
关键字还有:IN EXISTS 比较符号和ANY ALL
=ANY和IN等价<>ALL和NOT IN等价>ANY大于最小的(>MIN)<ANY小于最大的(<MAX)>ALL大于最大的(>MAX)<ALL小于最小的(<MIN)=ALL结果返回1个值--> =,结果返回多个值-->空4 分页查询
http://www.2cto.com/database/201109/106128.html
4.1 MS SQL
可以使用存储过程,也可以使用游标。存储过程是个不错的选择,因为存储过程是颠末预编译的,执行效率高,也更灵活。
先看看单条 SQL 语句的分页 SQL 吧。
方法1:
SELECT TOP 页大小 * FROM table1 WHERE id NOT IN ( SELECT TOP 页大小*(页数-1) id FROM table1 ORDER BY id ) ORDER BY id
这里每次执行会除去之前已经分出去的数据。
方法2:SELECT TOP 页大小 * FROM ( SELECT ROW_NUMBER() OVER (ORDER BY id) AS RowNumber,* FROM table1 ) A WHERE RowNumber > 页大小*(页数-1)这个方法使用了Over分析函数,给出了列号,然后按需要取出相应的列号,简单明了。
说明,页大小:每页的行数;页数:第几页。使用时,请把“页大小”以及“页大小*(页数-1)”替换成数码。
4.2 Mysql
使用Limit, 接受一个或两个数字参数。
如果给定两个参数,第一个参数指定第一个返回记录行的偏移量,第二个参数指定返回记录行的最大数目。
初始记录行的偏移量是 0(而不是 1) 。
LIMIT 起始行, 每页多少行
SELECT * FROM TT LIMIT 1,20SELECT * FROM TT LIMIT 21,30
如果数据很大的话,可能需要有所改变
//方法同上mysql> select * from news limit 490000,10 //0.22 sec;//很明显,这种方式胜出 .mysql> select * from news where id>=(select id from news limit 490000,1) limit 10; //0.18 sec
4.3 Oracle
http://www.cnblogs.com/Ronger/archive/2012/05/14/2498971.html
方法1
SELECT * FROM ( SELECT A.*, ROWNUM RN FROM (SELECT * FROM TABLE_NAME) A WHERE ROWNUM <= 40 ) WHERE RN >= 21方法 1 第二层通过ROWNUM <= 40来控制最大值,在查询的最外层控制最小值。
方法2
方式2是去掉查询第二层的WHERE ROWNUM <= 40语句,在查询的最外层控制分页的最小值和最大值。
SELECT * FROM ( SELECT A.*, ROWNUM RN FROM (SELECT * FROM TABLE_NAME) A ) WHERE RN BETWEEN 21 AND 40对比这两种写法,绝大多数的情况下,方法1的效率比方法2高得多。
这是由于CBO优化模式下,Oracle可以将外层的查询条件推到内层查询中,以提高内层查询的执行效率。对于方法1查询语句,第二层的查询条件WHERE ROWNUM <= 40就可以被Oracle推入到内层查询中,这样Oracle查询的结果一旦超过了ROWNUM限制条件,就终止查询将结果返回了。
而方法2查询语句,由于查询条件BETWEEN 21 AND 40是存在于查询的第三层,而Oracle无法将第三层的查询条件推到最内层(即使推到最内层也没有意义,因为最内层查询不知道RN代表什么)。因此,对于方法2查询语句,Oracle最内层返回给中间层的是所有满足条件的数据,而中间层返回给最外层的也是所有数据。数据的过滤在最外层完成,显然这个效率要比第一个查询低得多。
5 公用表达式
http://www.cnblogs.com/CareySon/archive/2011/12/12/2284740.html
子查询 视图 公用表达式
简介
对于SELECT查询语句来说,通常情况下,为了使T-SQL代码更加简洁和可读,在一个查询中引用另外的结果集都是通过视图而不是子查询来进行分解的.但是,视图是作为系统对象存在数据库中,那对于结果集仅仅需要在存储过程或是用户自定义函数中使用一次的时候,使用视图就显得有些奢侈了。
公用表表达式(Common Table Expression)是SQL SERVER 2005版本之后引入的一个特性.CTE可以看作是一个临时的结果集,可以在接下来的一个SELECT,INSERT,UPDATE,DELETE,MERGE语句中被多次引用。使用公用表达式可以让语句更加清晰简练.
除此之外,根据微软对CTE好处的描述,可以归结为四点:
a. 可以定义递归公用表表达式(CTE)
b. 当不需要将结果集作为视图被多个地方引用时,CTE可以使其更加简洁
c. GROUP BY语句可以直接作用于子查询所得的标量列
d. 可以在一个语句中多次引用公用表表达式(CTE)
公用表表达式(CTE)的定义只包含三部分:
a. 公用表表达式的名字(在WITH之后)
b.所涉及的列名(可选)
c.一个SELECT语句(紧跟AS之后)
WITH expression_name [ ( column_name [,...n] ) ] AS .( CTE_query_definition )按照是否递归,可以将公用表(CTE)表达式分为递归公用表表达式和非递归公用表表达式.
5.1 非递归公用表表达式(CTE)
非递归公用表表达式(CTE)是查询结果仅仅一次性返回一个结果集用于外部查询调用。并不在其定义的语句中调用其自身的CTE
非递归公用表表达式(CTE)的使用方式和视图以及子查询一致
一个简单的非递归公用表表达式:
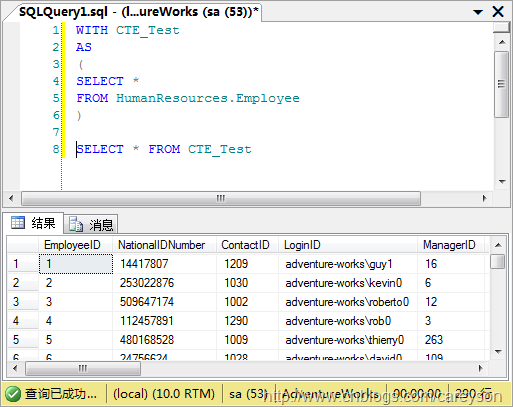
当然,公用表表达式的好处之一是可以在接下来一条语句中多次引用:
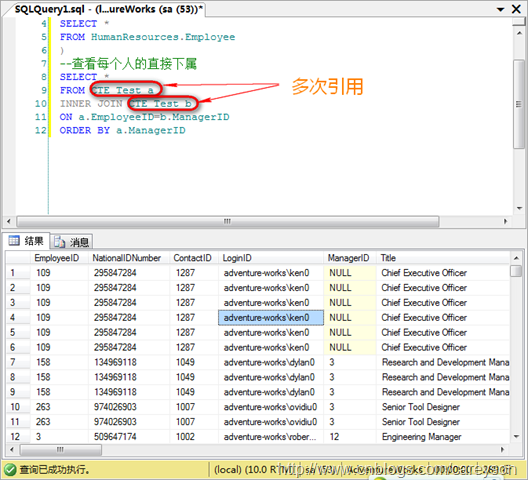
前面我一直强调“在接下来的一条语句中”,意味着只能接下来一条使用:
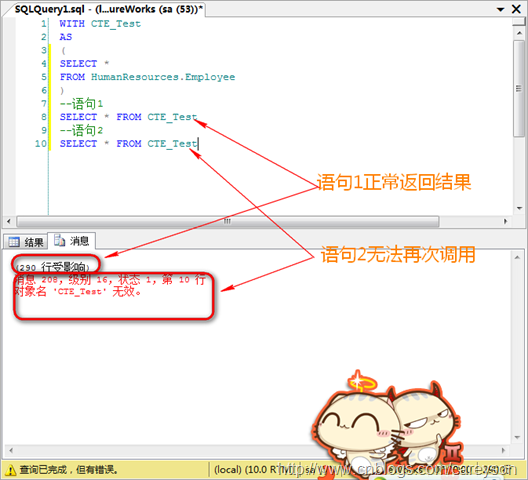
由于CTE只能在接下来一条语句中使用,因此,当需要接下来的一条语句中引用多个CTE时,可以定义多个,中间用逗号分隔:

5.2 递归公用表表达式(CTE)
对于递归公用表达式来说,实现原理也是相同的,同样需要在语句中定义两部分:
a. 基本语句
b. 递归语句
比如:在AdventureWork中,我想知道每个员工所处的层级,0是最高级
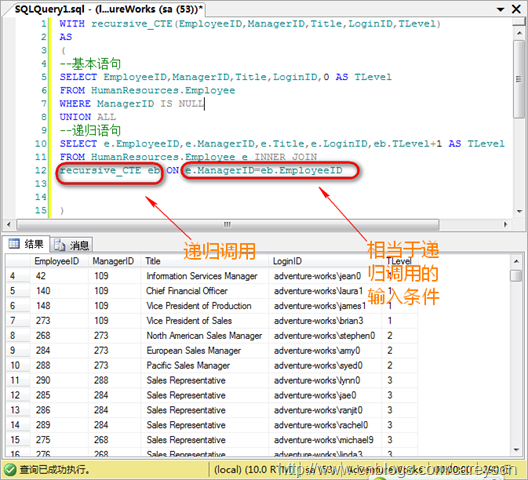
以上可以显示全公司的等级表。
这么复杂的查询通过递归CTE变得如此优雅和简洁.这也是CTE最强大的地方.
当然,越强大的力量,就需要被约束.如果使用不当的话,递归CTE可能会出现无限递归。从而大量消耗SQL Server的服务器资源.因此,SQL Server提供了OPTION选项,可以设定最大的递归次数:
还是上面那个语句,限制了递归次数:

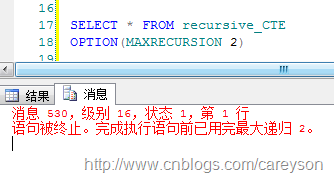
这个最大递归次数往往是根据数据所代表的具体业务相关的,比如这里,假设公司层级最多只有2层.
6 派生表
派生表是Microsoft公司新推出的SQL2005数据库的一个增强功能。
派生表是一个查询结果生成的表,类似于临时表。
派生表可以简化查询,避免使用临时表。相比手动生成临时性能更优越。派生表与其他表一样出现在查询的FROM子句中
select * from (select * from athors) temptemp 就是派生表
Every derived table must have its own alias(每个派生表必须有自己的别名)
派生出来的表必须要是一个有效的表.因此,它必须遵守以下几条规则:
1. 所有列必须要有名称
2. 列名称必须是要唯一
3. 不允许使用ORDER BY(除非指定了TOP)
举例:
bbc国家概况表
显示每个地区以及的该地区国家总人口数不少于1000万的国家总数.
SELECT region, COUNT(name) FROM bbc WHERE population >=10000000 GROUP BY region
使用派生表:
SELECT region, COUNT(name) FROM (SELECT region, name FROM bbc WHERE population>=10000000) temp1 GROUP BY region或者
SELECT region, COUNT(name) FROM (select name,region from bbc where population>=10000000) as temp1 group by region
7 透视,逆透视
形成数据透视表
http://database.51cto.com/art/201107/274606_2.htm
8 分组,分组集
GROUP
CUBE ROLLUP
COMPUTE
GROUPING
9 合并数据 Merge
Merge关键字是一个神奇的DML关键字。它在SQL Server 2008被引入,它能将Insert,Update,Delete简单的并为一句。MSDN对于Merge的解释非常的短小精悍:”根据与源表联接的结果,对目标表执行插入、更新或删除操作。例如,根据在另一个表中找到的差异在一个表中插入、更新或删除行,可以对两个表进行同步。”,通过这个描述,我们可以看出Merge是关于对于两个表之间的数据进行操作的。
http://www.cnblogs.com/lenxu/archive/2012/02/14/2350922.html 详见

10 Output子句
1 )能从修改的行中返回数据,可以与INSERT , DELETE ,UPDATE, MERGE 等一起使用
2 )在存储过程中修饰输出变量
http://blog.csdn.net/leamonjxl/article/details/6604836
11 锁机制
http://www.360doc.com/content/07/0702/07/1_589777.shtml
12 可编程性
存储过程 用户自定义函数 触发器 || 游标
13 索引
数据库中一个值或一组值的排序结构
14 事务处理
- 数据库--高阶--通用Oracle、MS SQL和Mysql
- 用C++库连接Oracle, MS SQL, MySQL等数据库
- 用BAT启动、关闭数据库(MS SQL/MYSQL/ORACLE)服务
- MS SQL Server和Oracle对数据库事务处理的差异性
- MS SQL Server,Oracle 和 MySQL 有哪些区别
- Oracle与Mysql等数据库通用SQL优化技巧
- 如何在Oracle SQL Developer 中连接MS SQL Server、MySQL数据库
- 如何在Oracle SQL Developer 中连接MS SQL Server、MySQL数据库
- 如何在Oracle SQL Developer 中连接MS SQL Server、MySQL数据库
- 如何在Oracle SQL Developer 中连接MS SQL Server、MySQL数据库(转)
- 采用工厂模式思想,通用连接ms sql server/oracle
- C#操作MS SQL Server 数据库的通用类
- ORACLE和MS SQL SQL语法区别
- MS Server, MySql,Oracle数据库的区别
- 【Database】常用数据库Oracle/MySQL/MS SQL Server 驱动包下载地址
- 数据库查询排序使用随机排序结果示例(Oracle/MySQL/MS SQL Server)
- oracle通过透明网关(Oracle Transparent Geteways),访问ms sql server和其他数据库
- oracle通过透明网关(Oracle Transparent Geteways),访问ms sql server和其他数据库
- Coreseek代码结构分析(转)
- URAL 1260
- _ARRAYOF Variant* aParams
- 使用网盘建立自己的svn版本控制
- 记录一些编程相关的网址
- 数据库--高阶--通用Oracle、MS SQL和Mysql
- Android之Adapter用法总结(纠错)
- 模糊查询,用?传值
- Search in Rotated Sorted Array
- SQL查询行转列
- 庞果网幸运数,一解,失败的例子吧
- Oracle高级应用之去重聚合函数
- 选择排序
- 谁是下一个价值19亿美元的91无线?谁又是下一个百度?


