[+补充]多进程及多线程
来源:互联网 发布:mac如何访问国外网站 编辑:程序博客网 时间:2024/05/16 06:15
一.为何需要多进程(或者多线程),为何需要并发?
这个问题或许本身都不是个问题。但是对于没有接触过多进程编程的朋友来说,他们确实无法感受到并发的魅力以及必要性。
我想,只要你不是整天都写那种int main()到底的代码的人,那么或多或少你会遇到代码响应不够用的情况,也应该有尝过并发编程的甜头。就像一个快餐点的服务员,既要在前台接待客户点餐,又要接电话送外卖,没有分身术肯定会忙得你焦头烂额的。幸运的是确实有这么一种技术,让你可以像孙悟空一样分身,灵魂出窍,乐哉乐哉地轻松应付一切状况,这就是多进程/线程技术。并发技术,就是可以让你在同一时间同时执行多条任务的技术。你的代码将不仅仅是从上到下,从左到右这样规规矩矩的一条线执行。你可以一条线在main函数里跟你的客户交流,另一条线,你早就把你外卖送到了其他客户的手里。
所以,为何需要并发?因为我们需要更强大的功能,提供更多的服务,所以并发,必不可少。
二.多进程
什么是进程。最直观的就是一个个pid,官方的说法就:进程是程序在计算机上的一次执行活动。
说得简单点,下面这段代码执行的时候
- int main()
- {
- printf(”pid is %d/n”,getpid() );
- return 0;
- }
进入main函数,这就是一个进程,进程pid会打印出来,然后运行到return,该函数就退出,然后由于该函数是该进程的唯一的一次执行,所以return后,该进程也会退出。
看看多进程。linux下创建子进程的调用是fork();
- #include <unistd.h>
- #include <sys/types.h>
- #include <stdio.h>
- void print_exit()
- {
- printf("the exit pid:%d/n",getpid() );
- }
- main ()
- {
- pid_t pid;
- atexit( print_exit ); //注册该进程退出时的回调函数
- pid=fork();
- if (pid < 0)
- printf("error in fork!");
- else if (pid == 0)
- printf("i am the child process, my process id is %d/n",getpid());
- else
- {
- printf("i am the parent process, my process id is %d/n",getpid());
- sleep(2);
- wait();
- }
- }
i am the child process, my process id is 15806
the exit pid:15806
i am the parent process, my process id is 15805
the exit pid:15805
这是gcc测试下的运行结果。
关于fork函数,功能就是产生子进程,由于前面说过,进程就是执行的流程活动。
那么fork产生子进程的表现就是它会返回2次,一次返回0,顺序执行下面的代码。这是子进程。
一次返回子进程的pid,也顺序执行下面的代码,这是父进程。
(为何父进程需要获取子进程的pid呢?这个有很多原因,其中一个原因:看最后的wait,就知道父进程等待子进程的终结后,处理其task_struct结构,否则会产生僵尸进程,扯远了,有兴趣可以自己google)。
如果fork失败,会返回-1.
额外说下atexit( print_exit );需要的参数肯定是函数的调用地址。
这里的print_exit是函数名还是函数指针呢?答案是函数指针,函数名永远都只是一串无用的字符串。
某本书上的规则:函数名在用于非函数调用的时候,都等效于函数指针。
说到子进程只是一个额外的流程,那他跟父进程的联系和区别是什么呢?
我很想建议你看看linux内核的注解(有兴趣可以看看,那里才有本质上的了解),总之,fork后,子进程会复制父进程的task_struct结构,并为子进程的堆栈分配物理页。理论上来说,子进程应该完整地复制父进程的堆,栈以及数据空间,但是2者共享正文段。
关于写时复制:由于一般 fork后面都接着exec,所以,现在的 fork都在用写时复制的技术,顾名思意,就是,数据段,堆,栈,一开始并不复制,由父,子进程共享,并将这些内存设置为只读。直到父,子进程一方尝试写这些区域,则内核才为需要修改的那片内存拷贝副本。这样做可以提高 fork的效率。
三.多线程
线程是可执行代码的可分派单元。这个名称来源于“执行的线索”的概念。在基于线程的多任务的环境中,所有进程有至少一个线程,但是它们可以具有多个任务。这意味着单个程序可以并发执行两个或者多个任务。
简而言之,线程就是把一个进程分为很多片,每一片都可以是一个独立的流程。这已经明显不同于多进程了,进程是一个拷贝的流程,而线程只是把一条河流截成很多条小溪。它没有拷贝这些额外的开销,但是仅仅是现存的一条河流,就被多线程技术几乎无开销地转成很多条小流程,它的伟大就在于它少之又少的系统开销。(当然伟大的后面又引发了重入性等种种问题,这个后面慢慢比较)。
还是先看linux提供的多线程的系统调用:
int pthread_create(pthread_t *restrict tidp,
const pthread_attr_t *restrict attr,
void *(*start_rtn)(void),
void *restrict arg);
Returns: 0 if OK, error number on failure
第一个参数为指向线程标识符的指针。
第二个参数用来设置线程属性。
第三个参数是线程运行函数的起始地址。
最后一个参数是运行函数的参数。
- #include<stdio.h>
- #include<string.h>
- #include<stdlib.h>
- #include<unistd.h>
- #include<pthread.h>
- void* task1(void*);
- void* task2(void*);
- void usr();
- int p1,p2;
- int main()
- {
- usr();
- getchar();
- return 1;
- }
- void usr()
- {
- pthread_t pid1, pid2;
- pthread_attr_t attr;
- void *p;
- int ret=0;
- pthread_attr_init(&attr); //初始化线程属性结构
- pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED); //设置attr结构为分离
- pthread_create(&pid1, &attr, task1, NULL); //创建线程,返回线程号给pid1,线程属性设置为attr的属性,线程函数入口为task1,参数为NULL
- pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE);
- pthread_create(&pid2, &attr, task2, NULL);
- //前台工作
- ret=pthread_join(pid2, &p); //等待pid2返回,返回值赋给p
- printf("after pthread2:ret=%d,p=%d/n", ret,(int)p);
- }
- void* task1(void *arg1)
- {
- printf("task1/n");
- //艰苦而无法预料的工作,设置为分离线程,任其自生自灭
- pthread_exit( (void *)1);
- }
- void* task2(void *arg2)
- {
- int i=0;
- printf("thread2 begin./n");
- //继续送外卖的工作
- pthread_exit((void *)2);
- }
这个多线程的例子应该很明了了,主线程做自己的事情,生成2个子线程,task1为分离,任其自生自灭,而task2还是继续送外卖,需要等待返回。(因该还记得前面说过僵尸进程吧,线程也是需要等待的。如果不想等待,就设置线程为分离线程)
额外的说下,linux下要编译使用线程的代码,一定要记得调用pthread库。如下编译:
gcc -o pthrea -pthread pthrea.c
四.比较以及注意事项
1.看完前面,应该对多进程和多线程有个直观的认识。如果总结多进程和多线程的区别,你肯定能说,前者开销大,后者开销较小。确实,这就是最基本的区别。
2.线程函数的可重入性:
说到函数的可重入,和线程安全,我偷懒了,引用网上的一些总结。
线程安全:概念比较直观。一般说来,一个函数被称为线程安全的,当且仅当被多个并发线程反复调用时,它会一直产生正确的结果。
可重入:概念基本没有比较正式的完整解释,但是它比线程安全要求更严格。根据经验,所谓“重入”,常见的情况是,程序执行到某个函数foo()时,收到信号,于是暂停目前正在执行的函数,转到信号处理函数,而这个信号处理函数的执行过程中,又恰恰也会进入到刚刚执行的函数foo(),这样便发生了所谓的重入。此时如果foo()能够正确的运行,而且处理完成后,之前暂停的foo()也能够正确运行,则说明它是可重入的。
线程安全的条件:
要确保函数线程安全,主要需要考虑的是线程之间的共享变量。属于同一进程的不同线程会共享进程内存空间中的全局区和堆,而私有的线程空间则主要包括栈和寄存器。因此,对于同一进程的不同线程来说,每个线程的局部变量都是私有的,而全局变量、局部静态变量、分配于堆的变量都是共享的。在对这些共享变量进行访问时,如果要保证线程安全,则必须通过加锁的方式。
可重入的判断条件:
要确保函数可重入,需满足一下几个条件:
1、不在函数内部使用静态或全局数据
2、不返回静态或全局数据,所有数据都由函数的调用者提供。
3、使用本地数据,或者通过制作全局数据的本地拷贝来保护全局数据。
4、不调用不可重入函数。
可重入与线程安全并不等同,一般说来,可重入的函数一定是线程安全的,但反过来不一定成立。它们的关系可用下图来表示:
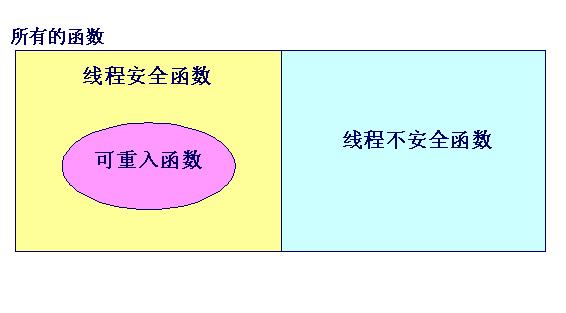
比如:strtok函数是既不可重入的,也不是线程安全的;加锁的strtok不是可重入的,但线程安全;而strtok_r既是可重入的,也是线程安全的。
如果我们的线程函数不是线程安全的,那在多线程调用的情况下,可能导致的后果是显而易见的——共享变量的值由于不同线程的访问,可能发生不可预料的变化,进而导致程序的错误,甚至崩溃。
3.关于IPC(进程间通信)
由于多进程要并发协调工作,进程间的同步,通信是在所难免的。
稍微列举一下linux常见的IPC.
linux下进程间通信的几种主要手段简介:
- 管道(Pipe)及有名管道(named pipe):管道可用于具有亲缘关系进程间的通信,有名管道克服了管道没有名字的限制,因此,除具有管道所具有的功能外,它还允许无亲缘关系进程间的通信;
- 信号(Signal):信号是比较复杂的通信方式,用于通知接受进程有某种事件发生,除了用于进程间通信外,进程还可以发送信号给进程本身;linux除了支持Unix早期信号语义函数sigal外,还支持语义符合Posix.1标准的信号函数sigaction(实际上,该函数是基于BSD的,BSD为了实现可靠信号机制,又能够统一对外接口,用sigaction函数重新实现了signal函数);
- 报文(Message)队列(消息队列):消息队列是消息的链接表,包括Posix消息队列system V消息队列。有足够权限的进程可以向队列中添加消息,被赋予读权限的进程则可以读走队列中的消息。消息队列克服了信号承载信息量少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 共享内存:使得多个进程可以访问同一块内存空间,是最快的可用IPC形式。是针对其他通信机制运行效率较低而设计的。往往与其它通信机制,如信号量结合使用,来达到进程间的同步及互斥。
- 信号量(semaphore):主要作为进程间以及同一进程不同线程之间的同步手段。
- 套接口(Socket):更为一般的进程间通信机制,可用于不同机器之间的进程间通信。起初是由Unix系统的BSD分支开发出来的,但现在一般可以移植到其它类Unix系统上:Linux和System V的变种都支持套接字。
或许你会有疑问,那多线程间要通信,应该怎么做?前面已经说了,多数的多线程都是在同一个进程下的,它们共享该进程的全局变量,我们可以通过全局变量来实现线程间通信。如果是不同的进程下的2个线程间通信,直接参考进程间通信。
4.关于线程的堆栈
说一下线程自己的堆栈问题。
是的,生成子线程后,它会获取一部分该进程的堆栈空间,作为其名义上的独立的私有空间。(为何是名义上的呢?)由于,这些线程属于同一个进程,其他线程只要获取了你私有堆栈上某些数据的指针,其他线程便可以自由访问你的名义上的私有空间上的数据变量。(注:而多进程是不可以的,因为不同的进程,相同的虚拟地址,基本不可能映射到相同的物理地址)
5.在子线程里fork
看过好几次有人问,在子线程函数里调用system或者 fork为何出错,或者fork产生的子进程是完全复制父进程的吗?
我测试过,只要你的线程函数满足前面的要求,都是正常的。
- #include<stdio.h>
- #include<string.h>
- #include<stdlib.h>
- #include<unistd.h>
- #include<pthread.h>
- void* task1(void *arg1)
- {
- printf("task1/n");
- system("ls");
- pthread_exit( (void *)1);
- }
- int main()
- {
- int ret=0;
- void *p;
- int p1=0;
- pthread_t pid1;
- pthread_create(&pid1, NULL, task1, NULL);
- ret=pthread_join(pid1, &p);
- printf("end main/n");
- return 1;
- }
上面这段代码就可以正常得调用ls指令。
不过,在同时调用多进程(子进程里也调用线程函数)和多线程的情况下,函数体内很有可能死锁。
准则3:多线程程序里不准使用fork
那看看实例吧.一执行下面的代码,在子进程的执行开始处调用doit()时,发生死锁的机率会很高.

 void* doit(void*)
void* doit(void*)  {
{2

3
static pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;4
5
pthread_mutex_lock(&mutex);6
7

 struct timespec ts = {10, 0};
struct timespec ts = {10, 0};9
10
pthread_mutex_unlock(&mutex);11
12
return 0;13
14
 }
}15

16
17
18
int main(void) {19
20
pthread_t t; 21
22
pthread_create(&t, 0, doit, 0); // 做成并启动子线程25
26
if (fork() == 0) {32
33
34
//在子进程被创建的瞬间,父的子进程在执行nanosleep的场合比较多35
36
doit(0); return 0;37
38
 }
}39
40
pthread_join(t, 0); // 等待子线程结束43
44
}45
以下是说明死锁的理由:- 父进程的内存数据会原封不动的拷贝到子进程中
- 子进程在单线程状态下被生成
在内存区域里,静态变量*2mutex的内存会被拷贝到子进程里.而且,父进程里即使存在多个线程,但它们也不会被继承到子进程里. fork的这两个特征就是造成死锁的原因.
译者注: 死锁原因的详细解释 ---
1. 线程里的doit()先执行.
2. doit执行的时候会给互斥体变量mutex加锁.
3. mutex变量的内容会原样拷贝到fork出来的子进程中(在此之前,mutex变量的内容已经被线程改写成锁定状态).
4. 子进程再次调用doit的时候,在锁定互斥体mutex的时候会发现它已经被加锁,所以就一直等待,直到拥有该互斥体的进程释放它(实际上没有人拥有这个mutex锁).
5. 线程的doit执行完成之前会把自己的mutex释放,但这是的mutex和子进程里的mutex已经是两份内存.所以即使释放了mutex锁也不会对子进程里的mutex造成什么影响.
1. 在fork前的父进程中,启动了线程1和2
2. 线程1调用doit函数
3. doit函数锁定自己的mutex
4. 线程1执行nanosleep函数睡10秒
5. 在这儿程序处理切换到线程2
6. 线程2调用fork函数
7. 生成子进程
8. 这时,子进程的doit函数用的mutex处于”锁定状态”,而且,解除锁定的线程在子进程里不存在
9. 子进程的处理开始
10.子进程调用doit函数
11.子进程再次锁定已经是被锁定状态的mutex,然后就造成死锁
像这里的doit函数那样的,在多线程里因为fork而引起问题的函数,我们把它叫做”fork-unsafe函数”.反之,不能引起问题的函数叫做”fork-safe函数”.虽然在一些商用的UNIX里,源于OS提供的函数(系统调用),在文档里有fork-safety的记载,但是在Linux(glibc)里当然!不会被记载.即使在POSIX里也没有特别的规定,所以那些函数是fork-safe的,几乎不能判别.不明白的话,作为unsafe考虑的话会比较好一点吧.(2004/9/12追记)Wolfram Gloger说过,调用异步信号安全函数是规格标准,所以试着调查了一下,在pthread_atforkの这个地方里有” In the meantime, only a short list of async-signal-safe library routines are promised to be available.”这样的话.好像就是这样.
随便说一下,malloc函数就是一个维持自身固有mutex的典型例子,通常情况下它是fork-unsafe的.依赖于malloc函数的函数有很多,例如printf函数等,也是变成fork-unsafe的.
直到目前为止,已经写上了thread+fork是危险的,但是有一个特例需要告诉大家.”fork后马上调用exec的场合,是作为一个特列不会产生问题的”.什么原因呢..?exec函数*6一被调用,进程的”内存数据”就被临时重置成非常漂亮的状态.因此,即使在多线程状态的进程里,fork后不马上调用一切危险的函数,只是调用exec函数的话,子进程将不会产生任何的误动作.但是,请注意这里使用的”马上”这个词.即使exec前仅仅只是调用一回printf(“I’m child process”),也会有死锁的危险.
译者注:exec函数里指明的命令一被执行,改命令的内存映像就会覆盖父进程的内存空间.所以,父进程里的任何数据将不复存在.
规避方法1:做fork的时候,在它之前让其他的线程完全终止.
规避方法2:fork后在子进程中马上调用exec函数
规避方法3:”其他线程”中,不做fork-unsafe的处理
规避方法4:使用pthread_atfork函数,在即将fork之前调用事先准备的回调函数.
使用pthread_atfork函数,在即将fork之前调用事先准备的回调函数,在这个回调函数内,协商清除进程的内存数据.但是关于OS提供的函数(例:malloc),在回调函数里没有清除它的方法.因为malloc里使用的数据结构在外部是看不见的.因此,pthread_atfork函数几乎是没有什么实用价值的.
规避方法5:在多线程程序里,不使用fork
就是不使用fork的方法.即用pthread_create来代替fork.这跟规避策2一样都是比较实际的方法,值得推荐.
---------------------------------------------------------------------------------------------------
java创建多线程的方法
package sz.zondy.com.core;
import java.lang.Thread;
class MyThread implements java.lang.Runnable
{
private int threadId;
private int intell;
public MyThread(int id,int intell)
{
this.threadId = id;
this.intell = intell;
}
@Override
public synchronized void run()
{
System.out.println("Thread ID: " + this.threadId + " : " + this.intell);
}
}
public class Test{
/**
* @param args
* @throws InterruptedException
*/
public static void main(String[] args) throws InterruptedException
{
int i = 1;
new Thread(new MyThread(1,i)).start();
i++;
new Thread(new MyThread(2,i)).start();
Thread.sleep(1);
}
}
某次执行结果:(可能会先执行2)
Thread ID: 2 : 2
Thread ID: 1 : 1
- [+补充]多进程及多线程
- 多进程及多线程比较
- 进程、线程及多进程多线程简介
- php 多进程及多线程的优缺点
- 多线程_进程概述及多进程的意义
- Socket学习 - 多进程补充
- 多线程补充
- 【UnixC多线程\进程】多线程和多进程C代码及测试截图
- ubuntu 16.04 安装多lnmp 及多进程 多线程
- 多进程及多线程之间同步与通信
- 多线程还是多进程的选择及区别
- 多线程之间及多进程间的通信
- 多线程还是多进程的选择及区别
- 多线程还是多进程的选择及区别
- 多进程及多线程之间同步与通信
- 多线程还是多进程的选择及区别
- 多进程及多线程之间同步与通信
- 多线程还是多进程的选择及区别
- mac 删除 jdk
- 重头开始学JAVA
- HDU 1671
- 3D printer controller software for BeagleBone with BeBoPr Cape.
- MyBatis3整合Spring3、SpringMVC3
- [+补充]多进程及多线程
- 如何彻底清除MySQL
- [C#.NET][VB.NET] 程式執行時拖曳控制項
- poj 2455 二分+最大流
- NHibernate 3.2或以上的版本就没有 NHibernate.ByteCode.Castle.dll,NHibernate.ByteCode.LinFu.dll, NHibernate.Byt
- 寻找N个元素中最大的K个元素解法
- Linux man 命令后面的圆括号的意义
- fedora下dns的配置
- JAVA里面关于byte数组和String之间的转换问题


