使用SGD(Stochastic Gradient Descent)进行大规模机器学习
来源:互联网 发布:java 日志slj4j 编辑:程序博客网 时间:2024/06/05 14:25
使用SGD(Stochastic Gradient Descent)进行大规模机器学习
- 博客分类:
- Machine Learning
sgdmachine learninglarge-scale
使用SGD(Stochastic Gradient Descent)进行大规模机器学习
1 基于梯度下降的学习
对于一个简单的机器学习算法,每一个样例包含了一个(x,y)对,其中一个输入x和一个数值输出y。我们考虑损失函数) ,它描述了预测值
,它描述了预测值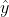 和实际值y之间的损失。预测值是我们选择从一函数族F中选择一个以w为参数的函数
和实际值y之间的损失。预测值是我们选择从一函数族F中选择一个以w为参数的函数) 的到的预测结果。
的到的预测结果。
我们的目标是寻找这样的函数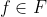 ,能够在训练集中最小化平均损失函数
,能够在训练集中最小化平均损失函数
=l\(f_w\(x\),y\)$$)
由于我们不知道数据的真实分布,所以我们通常使用
=\frac{1}{n}\sum_{i=1}^nl\(f\(x_i\),y_i\)$$)
来代替
=\int%20l\(f\(x\),y\)dP(z)$$)
经验风险) 用来衡量训练集合的效果。期望风险E(f)描述了泛化(generation)的效果,预测未知样例的能力。
用来衡量训练集合的效果。期望风险E(f)描述了泛化(generation)的效果,预测未知样例的能力。
如果函数族F进行足够的限制(sufficiently restrictive
),统计机器学习理论使用经验风险来代替期望风险。
1.1 梯度下降
我们经常使用梯度下降(GD)的方式来最小化期望风险,每一次迭代,基于) 更新权重w:
更新权重w:
$$) ,
,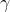 为学习率,如果选择恰当,初始值选择合适,这个算法能够满足线性的收敛。也就是:
为学习率,如果选择恰当,初始值选择合适,这个算法能够满足线性的收敛。也就是: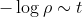 ,其中
,其中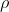 表示残余误差(residual error)。
表示残余误差(residual error)。
基于二阶梯度的比较出名的算法是牛顿法,牛顿法可以达到二次函数的收敛。如果代价函数是二次的,矩阵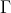 是确定的,那么这个算法可以一次迭代达到最优值。如果足够平滑的话,
是确定的,那么这个算法可以一次迭代达到最优值。如果足够平滑的话,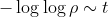 。但是计算需要计算偏导hession矩阵,对于高维,时间和空间消耗都是非常大的,所以通常采用近似的算法,来避免直接计算hession矩阵,比如BFGS,L-BFGS。
。但是计算需要计算偏导hession矩阵,对于高维,时间和空间消耗都是非常大的,所以通常采用近似的算法,来避免直接计算hession矩阵,比如BFGS,L-BFGS。
1.2 随机梯度下降
SGD是一个重要的简化,每一次迭代中,梯度的估计并不是精确的计算,而是基于随即选取的一个样例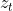 :
:
$$)
随机过程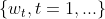
依赖于每次迭代时随即选择的样例,尽管这个简化的过程引入了一些噪音,但是我们希望他的表现能够和GD的方式一样。
随机算法不需要记录哪些样例已经在前面的迭代过程中被访问过,有时候随机梯度下降能够直接优化期望风险,因为样例可能是随机从真正的分布中选取的。
随机梯度算法的收敛性已经在随机近似算法的论文所讨论。收敛性要满足:
 并且
并且
二阶随机梯度下降:
$$)
这种方法并没有减少噪音,也不会对计算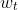 有太大改进。
有太大改进。
1.3 随即梯度的一些例子
下面列了一些比较经典的机器学习算法的随机梯度,

1 基于梯度下降的学习
对于一个简单的机器学习算法,每一个样例包含了一个(x,y)对,其中一个输入x和一个数值输出y。我们考虑损失函数
我们的目标是寻找这样的函数
由于我们不知道数据的真实分布,所以我们通常使用
来代替
经验风险
如果函数族F进行足够的限制(sufficiently restrictive
),统计机器学习理论使用经验风险来代替期望风险。
1.1 梯度下降
我们经常使用梯度下降(GD)的方式来最小化期望风险,每一次迭代,基于
基于二阶梯度的比较出名的算法是牛顿法,牛顿法可以达到二次函数的收敛。如果代价函数是二次的,矩阵
1.2 随机梯度下降
SGD是一个重要的简化,每一次迭代中,梯度的估计并不是精确的计算
随机过程
依赖于每次迭代时随即选择的样例,尽管这个简化的过程引入了一些噪音,但是我们希望他的表现能够和GD的方式一样。
随机算法不需要记录哪些样例已经在前面的迭代过程中被访问过,有时候随机梯度下降能够直接优化期望风险,因为样例可能是随机从真正的分布中选取的。
随机梯度算法的收敛性已经在随机近似算法的论文所讨论。收敛性要满足:
二阶随机梯度下降:
这种方法并没有减少噪音,也不会对计算
1.3 随即梯度的一些例子
下面列了一些比较经典的机器学习算法的随机梯度,
- 使用SGD(Stochastic Gradient Descent)进行大规模机器学习
- 使用SGD(Stochastic Gradient Descent)进行大规模机器学习
- 使用SGD(Stochastic Gradient Descent)进行大规模机器学习
- 使用SGD(Stochastic Gradient Descent)进行大规模机器学习
- 使用SGD(Stochastic Gradient Descent)进行大规模机器学习
- 使用SGD(Stochastic Gradient Descent)进行大规模机器学习
- 【转载】逻辑回归:使用SGD(Stochastic Gradient Descent)进行大规模机器学习
- Stochastic Gradient Descent (SGD)
- 随机梯度下降(Stochastic Gradient Descend, SGD)算法在大规模数据机器学习问题的使用
- SGD(Stochastic Gradient Descent)随机梯度下降
- 【机器学习学习过程中的笔记1——Stochastic gradient descent 和 Batch gradient descent 】
- BGD(Batch Gradient Descent), SGD (Stochastic Gradient Descent), MBGD (Mini-Batch Gradient Descent)
- 【转载】Stochastic Gradient Descent
- Optimization:Stochastic Gradient Descent
- Optimization: Stochastic Gradient Descent
- method_SGD(Stochastic Gradient Descent)
- Stochastic Gradient Descent
- 台大机器学习笔记(10-11)——Linear Models for Classification&Stochastic Gradient Descent
- hdu 3681 Prison Break (旅行商问题)
- C++智能指针auto_ptr
- UVa 1423 Guess (拓扑排序)
- cocos2dx 2.1.4 shader解析-1
- CAP理论十二年回顾:"规则"变了
- 使用SGD(Stochastic Gradient Descent)进行大规模机器学习
- hdu3404 Switch lights
- In-Stream大数据处理模式
- 1022. Digital Library (30)
- 用 NDK 编译 ffmpeg 到 Android 平台
- linux避免进程随终端关闭而被关闭
- In-Stream Big Data Processing
- poj 3041 Asteroids 二分图匹配
- Understanding GC pauses in JVM, HotSpot's minor GC.


