[POJ][1009]Edge Detection
来源:互联网 发布:地方台电视直播软件 编辑:程序博客网 时间:2024/05/02 01:40
Description
A simple edge detection algorithm sets an output pixel's value to be the maximum absolute value of the differences between it and all its surrounding pixels in the input image. Consider the input image below:
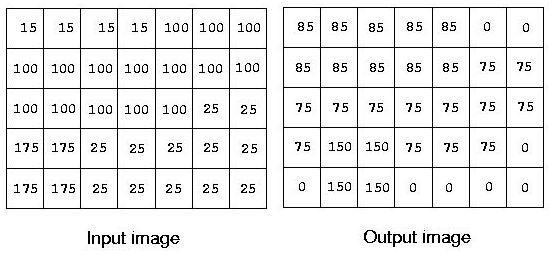
The upper left pixel in the output image is the maximum of the values |15-15|,|15-100|, and |15-100|, which is 85. The pixel in the 4th row, 2nd column is computed as the maximum of |175-100|, |175-100|, |175-100|, |175-175|, |175-25|, |175-175|,|175-175|, and |175-25|, which is 150.
Images contain 2 to 1,000,000,000 (109) pixels. All images are encoded using run length encoding (RLE). This is a sequence of pairs, containing pixel value (0-255) and run length (1-109). Input images have at most 1,000 of these pairs. Successive pairs have different pixel values. All lines in an image contain the same number of pixels.
Input
Output
Sample Input
715 4100 1525 2175 225 5175 225 50 01035 500000000200 5000000000 03255 110 1255 210 1255 210 1255 10 00
Sample Output
785 50 285 575 10150 275 30 2150 20 40 0100 499999990165 200 4999999900 03245 90 00
Hint
先说一句,这个题目特别考人的编码能力,我断断续续想了三天,写了一夜,调试了一上午。
(以下所说的边界值就是指输出中的RLE对里的第一个数据)
这个题目不需要算法就可以解决,纯模拟,但是数据量庞大,暴力的算肯定会TLE,所以模拟的时候计算的时候是有策略的。
输出结果是连续的,所以我们只要找到每个输出结果的开始点的索引,差值就是数字的个数,这样就可以轻松得到输出。
下面讨论如何找到每个输出结果的开始点
首先提出一个推论——输出开始点一定临近至少一个输入开始点
要想证明这个推论非常困难,我们可以证明其逆否命题——不临近输入开始点的点一定不是输出开始点
要不临近输入开始点,九个格子里的数字至少应该是
a a a a
b b (b) b
c c c c
(b)是我们选定的点,我们主要看右边九个数字,可以看出(b)一定不是输出开始点。
所以推论——输出开始点一定临近至少一个输入开始点——是正确的,也就是说,我们只要知道输入开始点,那么输入开始点加上周围的八个格子,这九个格子里面一定会出现输出开始点,那么我们的任务就是,找到输出开始点,计算其周围加上自身九个格子的边界值,和他们的索引值一并写入到一个二维数组里面去。
题目给出了提示,输入的RLE对不会超过1000,我们用一个[1010][2]的数组来存数据,用另一个二维数组存结果,也就是说极端情况下,存结果的二维数组需要[10010][2],多加几个个保险。
找到输入开始点,然后可以通过索引值加减width来找到周围八点的索引,注意有些索引超出范围是无效的。注意!用索引计算是为了避免目标点在边缘时出现的漏点情况!!!比如
a a a a a a
a a a a a a
a a c c c (c)
(a) a a a a a
(c)点的出现,导致(a)可能变成输出开始点。
要得到输出结果的边界值,则是获取目标点的pixel,再获取周围八点的pixel,这种情况,我建议不要直接用索引获取周围点,而是用 index / width 和 index % width 抽象一个二维数组,这样可以保证不会计算到不该计算的点。比如
a a a a a a
a a a a a a
a a c c c (c)
(a) a a a a (d)
获取(c)周围点时,不应计算(a)点
实际编写时,我发现最后一个点也需要计算本身和周围八点的边界值
这样我们就获得了输出开始点的边界值和索引,注意结果里面混杂了很多并非开始点的点,这个我们马上解决。
我们将边界值和对应索引值存在二维数组里,但是混杂了很多非开始点的,为了能得到边界值的连续个数,我们首先需要对二维数组进行排序,可是algorithm里面的sort函数无法直接排二维数组,所以我们修改一下存储形式,改用结构体。
struct node{ int value,start;} output[10010];结构体里面包含一个value一个start,分别存储边界值和索引,然后定义sort的第三个参数,这个参数是告诉sort排序时谁排在前面,该参数实际上是一个函数
bool comp(node n1,node n2) {return n1.start<n2.start;}这样当n1的start小于n2的start时,n1排在n2前面这样我们可以直接让结构体数组output按照索引值升序排列,接下来要求边界值连续的个数。
求的方法就是求每个边界值第一次出现的索引,注意被分隔开的边界值,即便是相等,也算不同的边界值。
具体来说,我们读取第一个节点的边界值,往后比较到第一个和它的边界值不同的节点,用后一个索引减去前一个索引,就是第一个节点边界值的最长连续个数,然后以第二个节点的边界值为准,找到第三个索引,减去第二个索引就是第二个边界值的最长连续个数。最后需要用总的索引值+1减去最后一个边界值最小的索引,即是最后一个边界值的最长连续个数。
下面给出AC代码
#include<iostream>#include<cmath>#include<algorithm>using namespace std;int width,num,rle[1001][2],column,row,outputindex=0;//column和row都存储的是索引最大值const int EIGHT[9][2]={{-1,-1},{0,-1},{1,-1},{-1,0},{1,0},{-1,1},{0,1},{1,1},{0,0}};struct node{ int value,start;} output[10010];int getValue(int r,int c)//传入坐标找数,坐标是索引{ if(c<0 || c>column || r<0 || r>row) return -1; int n=r*width+c; int i=0; while(n>rle[i][1]) ++i; return rle[i][0];}void insertMaxAbs(int r,int c)//传入坐标找输出数,坐标是索引{ if(c<0 || c>column || r<0 || r>row) return; int v[10]; v[8]=getValue(r,c); for(int i=0;i<=7;++i) { v[i]=getValue(r+EIGHT[i][0],c+EIGHT[i][1]); } v[9]=-1; for(int i=0;i<=7;++i) { if(v[i]!=-1 && abs(v[i]-v[8])>v[9]) v[9]=abs(v[i]-v[8]); } if(v[9]==-1) v[9]=v[8]; output[outputindex].value=v[9]; output[outputindex++].start=r*width+c;}int getMaxAbs(int r,int c)//传入坐标找输出数,坐标是索引{ if(c<0 || c>column || r<0 || r>row) return -1; int v[10]; v[8]=getValue(r,c); for(int i=0;i<=7;++i) { v[i]=getValue(r+EIGHT[i][0],c+EIGHT[i][1]); } v[9]=-1; for(int i=0;i<=7;++i) { if(v[i]!=-1 && abs(v[i]-v[8])>v[9]) v[9]=abs(v[i]-v[8]); } if(v[9]==-1) v[9]=v[8]; return v[9];}bool comp(node n1,node n2) {return n1.start<n2.start;}int main(){ while(cin>>width && width!=0) { column=width-1; cout<<width<<endl; num=0; outputindex=0;//outputindex存放结果中最后一对值的索引再加一个,最后一个有特殊作用 while(cin>>rle[num][0]>>rle[num][1] && (rle[num][0]!=0 || rle[num][1]!=0)) { if(num>0) rle[num][1]+=rle[num-1][1]; else --rle[num][1]; ++num; } --num;//num存放最后一对的索引值 const int EIGHT_INDEX[9]={-1-width,-width,1-width,-1,0,1,width-1,width,width+1}; row=rle[num][1]/width; int temp; for(int j=0,n=0;j<=num;++j) { for(int i=0;i<=8;++i) { temp=n+EIGHT_INDEX[i]; insertMaxAbs(temp/width,temp%width); } n=rle[j][1]+1; } for(int i=0;i<=8;++i) { temp=rle[num][1]+EIGHT_INDEX[i]; insertMaxAbs(temp/width,temp%width); } sort(output,output+outputindex,comp); output[outputindex].value = -1; output[outputindex].start = rle[num][1]+1; int previous,p_start; for(int i=0;i<outputindex; )//找到每个边界值第一次出现的索引,后面一个节点索引减去前一个就是个数 { previous=output[i].value; p_start=output[i].start; while(previous==output[++i].value){} cout<<previous<<' '<<output[i].start-p_start<<endl; } cout<<"0 0"<<endl; } cout<<0<<endl; return 0;}- POJ 1009 Edge Detection
- poj 1009 Edge Detection
- poj 1009 Edge Detection
- POJ 1009 Edge Detection
- POJ-1009-Edge Detection
- [POJ][1009]Edge Detection
- POJ 1009: Edge Detection
- POJ 1009 Edge Detection
- POJ 1009--Edge Detection
- POJ 1009Edge Detection
- POJ 1009 Edge Detection
- POJ 1009--Edge Detection
- POJ 1009 Edge Detection
- poj 1009 Edge Detection (未完成)
- poj 1009 Edge Detection 模拟
- POJ 1009 Edge Detection 笔记
- POJ 1009 解题报告 Edge Detection
- POJ 1009 Edge Detection解题报告
- 第七周项目2-求两数正差值
- Python 实现SSH client
- 第一节课C++
- 使用BFD操作ELF
- hdu 1142 A Walk Through the Forest(spfa求最短路+记忆化搜索)
- [POJ][1009]Edge Detection
- 一步一步配置NLB(续)之深入测试
- spring四种依赖注入方式
- 技术杂烩
- WebView学习笔记(一)——网页未完成加载的等待进度条
- 向程序猿进化
- VMware安装CentOS 6.2之后,进行简单的网络配置
- 《Essential C++》笔记四、采用关键字inline带来的错误
- [历年IT笔试题]2014腾讯校园招聘笔试试题


