Nutch 笔记(一):Quick Start
来源:互联网 发布:淘宝如何添加公益宝贝 编辑:程序博客网 时间:2024/05/17 01:24
Nutch 笔记(一):Quick Start
最近用到了nutch,目的是针对指定的一些网站抓取其内容,然后做分析用。
nutch 笔记是我使用nutch过程一系列总结,写下自己的学习经过和大家一起分享,也希望能得到大家的指点![]()
好了,废话少说,言归正传,第一篇:Quick Start,我们的目标是快速的能跑起来,能检索出我们想要的结果。
首先要明白nutch是什么?
nutch是一个基于lucene的开源搜索引擎,它包括了所有你想要的东西,是一个完整的解决方案 。
一:安装JDK
如果你已经安装了JDK,并且已经设置了JAVA_HOME,那么跳过这一步
安装jdk 代码
- sudo apt-get install sun-java5-jdk
或者从sun公司网站下载bin文件执行安装
设置了JAVA_HOME 代码
- sudo vi ~/.bashrc
在最后面增加代码
- export JAVA_HOME=/usr/lib/jvm/java-1.5.0-sun
- export PATH=$PATH:$JAVA_HOME/bin
二:下载nutch的最新版本nutch0.8.1
- wget http://apache.justdn.org/lucene/nutch/nutch-0.8.1.tar.gz
释放下来即可
代码
- tar zxvf nutch-0.8.1.tar.gz
三:抓取页面
增加url
- cd nutch-0.8.1
- mkdir urls
- echo http://www.xici.net>>urls/xici
编辑conf/crawl-urlfilter.txt,修改MY.DOMAIN.NAME为
- +^http://([a-z0-9]*.)*xici.net/
修改conf/nutch-site.xml,增加http.agent.name值
执行bin/nutch crawl开始抓取页面
- sudo bin/nutch crawl urls -dir crawl -depth 5 -topN 50&
这个过程需要等待一些时间
三:检索
安装tomcat,我们使用apache网站上的包
- cd ..
- wget http://mirror.vmmatrix.net/apache/tomcat/tomcat-5/v5.5.20/bin/apache-tomcat-5.5.20.tar.gz
- tar zxvf apache-tomcat-5.5.20.tar.gz
将nutch自带的war文件拷贝到webapps下面
- rm -rf apache-tomcat-5.5.20/webapps/ROOT*
- cp nutch-0.8.1/nutch*.war apache-tomcat-5.5.20/webapps/ROOT.war
运行tomcat,如果不设定nutch-site.xml的searcher.dir的值,则需要在crawl目录下面执行
- sudo ${TOMCAT的目录}/bin/startup.sh
我们也可以设定nutch-site.xml的searcher.dir的值
- sudo vi ${TOMCAT的目录}/webapps/ROOT/WEB-INF/classes/nutch-site.xml
增加代码
四:中文乱码
修改tomcat的server.xml,在Connector的tag最后增加代码
- URIEncoding="UTF-8"
五:截图 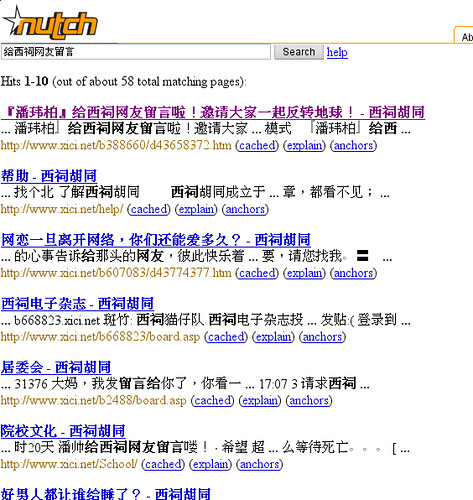
-----------------------
nutch site:http://lucene.apache.org/nutch
nutch wiki:http://wiki.apache.org/nutch/
本页地址:http://blog.csdn.net/liyang23456/archive/2007/04/26/1585208.aspx
- Nutch 笔记(一):Quick Start
- Nutch 笔记(一):Quick Start
- vue 学习笔记一之Quick Start
- Nutch学习笔记(一)
- mongoDB笔记1-quick start
- React实践笔记-Quick Start
- Nutch 笔记(一):Nutch 快速上手指南(收藏)
- Web Services Architecture Quick Start(一)
- Web Services Enhancements 3.0 Quick Start(一)
- quick-x笔记(一)配置环境
- quick-lua 学习笔记(一)t
- spark学习笔记之quick-start
- Quick Start
- Quick Start
- Nutch总结(一)
- Part I. 设计人员指南 Designer's Guide -- Chapter 1. 快速入门 Quick Start -- (一)
- Grails快速入门(Quick Start)
- Quick Start With PyCharm(翻译)
- 程序员创业成功必须遵守的几条铁律
- WEB专用服务器的安全设置
- 影响我的一件刻骨铭心的事
- 打造一个在线通信录,实现在线通讯录的显示、添加、删除
- 编程修养
- Nutch 笔记(一):Quick Start
- 程序员的灯下黑:坚持和良好心态近乎道
- 做个高效程序员
- ASP.NET中处理读写XML小结
- 对 MBCS 文本的 QuickSearch 搜索的误搜
- 1.4 微软的程序和项目管理
- 桌越科技关于程序员和软件开发
- Visual Studio 2005试用版升级为正式版
- 闪盘小偷的实现与代码


