Nutch 笔记(一):Nutch 快速上手指南(收藏)
来源:互联网 发布:绿叶装linux 编辑:程序博客网 时间:2024/06/04 19:23
原著未明,仅做收藏,谅解.

最近用到了nutch,目的是针对指定的一些网站抓取其内容,然后做分析用。
nutch 笔记是我使用nutch过程一系列总结,写下自己的学习经过和大家一起分享,也希望能得到大家的指点
好了,废话少说,言归正传,第一篇:Quick Start,我们的目标是快速的能跑起来,能检索出我们想要的结果。
首先要明白nutch是什么?
nutch是一个基于lucene的开源搜索引擎,它包括了所有你想要的东西,是一个完整的解决方案 。
一:安装JDK
如果你已经安装了JDK,并且已经设置了JAVA_HOME,那么跳过这一步
安装jdk
或者从sun公司网站下载bin文件执行安装
设置了JAVA_HOME
在最后面增加
二:下载nutch的最新版本nutch0.8.1
释放下来即可
三:抓取页面
增加url
编辑conf/crawl-urlfilter.txt,修改MY.DOMAIN.NAME为
修改conf/nutch-site.xml,增加http.agent.name值
执行bin/nutch crawl开始抓取页面
这个过程需要等待一些时间
四:检索
安装tomcat,我们使用apache网站上的包
将nutch自带的war文件拷贝到webapps下面
运行tomcat,如果不设定nutch-site.xml的searcher.dir的值,则需要在crawl目录下面执行
我们也可以设定nutch-site.xml的searcher.dir的值
增加
五:中文乱码
修改tomcat的server.xml,在Connector的tag最后增加
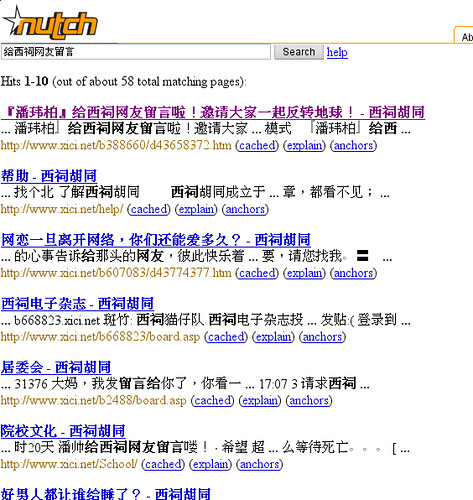
六:截图
参考:
nutch site:http://lucene.apache.org/nutch
nutch wiki:http://wiki.apache.org/nutch/
QUOTE:
这个笔记还是以前做项目时,用到nutch,写了两篇笔记,这个只是简单的不能再简单的使用说明而已,没什么太大的用处,就算给希望使用而不知道怎么使用的朋友一点建议吧
最近用到了nutch,目的是针对指定的一些网站抓取其内容,然后做分析用。
nutch 笔记是我使用nutch过程一系列总结,写下自己的学习经过和大家一起分享,也希望能得到大家的指点
好了,废话少说,言归正传,第一篇:Quick Start,我们的目标是快速的能跑起来,能检索出我们想要的结果。
首先要明白nutch是什么?
nutch是一个基于lucene的开源搜索引擎,它包括了所有你想要的东西,是一个完整的解决方案 。
一:安装JDK
如果你已经安装了JDK,并且已经设置了JAVA_HOME,那么跳过这一步
安装jdk
[Copy to clipboard] [ - ]
CODE:sudo apt-get install sun-java5-jdk
或者从sun公司网站下载bin文件执行安装
设置了JAVA_HOME
[Copy to clipboard] [ - ]
CODE:sudo vi ~/.bashrc
在最后面增加
[Copy to clipboard] [ - ]
CODE:export JAVA_HOME=/usr/lib/jvm/java-1.5.0-sun
export PATH=$PATH:$JAVA_HOME/bin
export PATH=$PATH:$JAVA_HOME/bin
二:下载nutch的最新版本nutch0.8.1
[Copy to clipboard] [ - ]
CODE:wget [url]http://apache.justdn.org/lucene/nutch/nutch-0.8.1.tar.gz[/url]
释放下来即可
[Copy to clipboard] [ - ]
CODE:tar zxvf nutch-0.8.1.tar.gz
三:抓取页面
增加url
[Copy to clipboard] [ - ]
CODE:cd nutch-0.8.1
mkdir urls
echo [url]http://www.xici.net[/url]>>urls/xici
mkdir urls
echo [url]http://www.xici.net[/url]>>urls/xici
编辑conf/crawl-urlfilter.txt,修改MY.DOMAIN.NAME为
[Copy to clipboard] [ - ]
CODE:+^http://([a-z0-9]*.)*xici.net/
修改conf/nutch-site.xml,增加http.agent.name值
[Copy to clipboard] [ - ]
CODE:<property>
<name>http.agent.name</name>
<value>test/unique</value>
</property>
<name>http.agent.name</name>
<value>test/unique</value>
</property>
执行bin/nutch crawl开始抓取页面
[Copy to clipboard] [ - ]
CODE:sudo bin/nutch crawl urls -dir crawl -depth 5 -topN 50&
这个过程需要等待一些时间
四:检索
安装tomcat,我们使用apache网站上的包
[Copy to clipboard] [ - ]
CODE:cd ..
wget [url]http://mirror.vmmatrix.net/apache/tomcat/tomcat-5/v5.5.20/bin/apache-tomcat-5.5.20.tar.gz[/url]
tar zxvf apache-tomcat-5.5.20.tar.gz
wget [url]http://mirror.vmmatrix.net/apache/tomcat/tomcat-5/v5.5.20/bin/apache-tomcat-5.5.20.tar.gz[/url]
tar zxvf apache-tomcat-5.5.20.tar.gz
将nutch自带的war文件拷贝到webapps下面
[Copy to clipboard] [ - ]
CODE:rm -rf apache-tomcat-5.5.20/webapps/ROOT*
cp nutch-0.8.1/nutch*.war apache-tomcat-5.5.20/webapps/ROOT.war
cp nutch-0.8.1/nutch*.war apache-tomcat-5.5.20/webapps/ROOT.war
运行tomcat,如果不设定nutch-site.xml的searcher.dir的值,则需要在crawl目录下面执行
[Copy to clipboard] [ - ]
CODE:sudo ${TOMCAT的目录}/bin/startup.sh
我们也可以设定nutch-site.xml的searcher.dir的值
[Copy to clipboard] [ - ]
CODE:sudo vi ${TOMCAT的目录}/webapps/ROOT/WEB-INF/classes/nutch-site.xml
增加
[Copy to clipboard] [ - ]
CODE:<property>
<name>searcher.dir</name>
<value>/home/martin/doc/nutch-0.8.1/crawl</value>
</property>
<name>searcher.dir</name>
<value>/home/martin/doc/nutch-0.8.1/crawl</value>
</property>
五:中文乱码
修改tomcat的server.xml,在Connector的tag最后增加
[Copy to clipboard] [ - ]
CODE:URIEncoding="UTF-8"
六:截图
参考:
nutch site:http://lucene.apache.org/nutch
nutch wiki:http://wiki.apache.org/nutch/
- Nutch 笔记(一):Nutch 快速上手指南(收藏)
- Nutch学习笔记(一)
- Nutch 笔记(一):Quick Start
- Nutch 笔记(一):Quick Start
- Nutch总结(一)
- Nutch 笔记(二):Craw more urls and Recrawl(收藏)
- Nutch Wiki ---Nutch的详细介绍(EN)(收藏)
- Nutch 2.3.1+ Hbase + Hadoop + Solr 单机指南(一)
- Nutch 快速入门(Nutch 1.7)
- Nutch笔记
- Nutch 笔记
- Nutch笔记
- nutch
- nutch
- Nutch
- Nutch
- nutch
- Nutch
- VB 各种进制相互转换大全
- 用js获取提交的字符串的字节数
- Struts+Spring+Hibernate配置全过程
- 动态语言小结
- Linux命令中正则表达式的运用
- Nutch 笔记(一):Nutch 快速上手指南(收藏)
- 显示连接到SQLserver上的用户IP及名称(转载)
- Spring AOP之Hello World
- spring,ioc模式与ejb3的SLSB实现
- JAVA--操作Execl
- java.lang.OutOfMemoryError: Java heap space问题
- 如何跟进止损的设置方法
- 看看玻璃代码,就知道你的车窗玻璃是谁造的
- AJAX在静态HTML页面中实现权限控制的应用


