MapReduce中的自定义多目录/文件名输出HDFS
来源:互联网 发布:阿里云公司 编辑:程序博客网 时间:2024/06/05 03:33
最近考虑到这样一个需求:
需要把原始的日志文件用hadoop做清洗后,按业务线输出到不同的目录下去,以供不同的部门业务线使用。
这个需求需要用到MultipleOutputFormat和MultipleOutputs来实现自定义多目录、文件的输出。
需要注意的是,在hadoop 0.21.x之前和之后的使用方式是不一样的:
hadoop 0.21 之前的API 中有 org.apache.hadoop.mapred.lib.MultipleOutputFormat 和 org.apache.hadoop.mapred.lib.MultipleOutputs,而到了 0.21 之后 的API为 org.apache.hadoop.mapreduce.lib.output.MultipleOutputs ,
新版的API 整合了上面旧API两个的功能,没有了MultipleOutputFormat。
本文将给出新旧两个版本的API code。
1、旧版0.21.x之前的版本:
01import java.io.IOException;02 03import org.apache.hadoop.conf.Configuration;04import org.apache.hadoop.conf.Configured;05import org.apache.hadoop.fs.Path;06import org.apache.hadoop.io.LongWritable;07import org.apache.hadoop.io.NullWritable;08import org.apache.hadoop.io.Text;09import org.apache.hadoop.mapred.FileInputFormat;10import org.apache.hadoop.mapred.FileOutputFormat;11import org.apache.hadoop.mapred.JobClient;12import org.apache.hadoop.mapred.JobConf;13import org.apache.hadoop.mapred.MapReduceBase;14import org.apache.hadoop.mapred.Mapper;15import org.apache.hadoop.mapred.OutputCollector;16import org.apache.hadoop.mapred.Reporter;17import org.apache.hadoop.mapred.TextInputFormat;18import org.apache.hadoop.mapred.lib.MultipleTextOutputFormat;19import org.apache.hadoop.util.Tool;20import org.apache.hadoop.util.ToolRunner;21 22public class MultiFile extends Configured implements Tool {23 24 public static class MapClass extends MapReduceBase implements25 Mapper<LongWritable, Text, NullWritable, Text> {26 27 @Override28 public void map(LongWritable key, Text value,29 OutputCollector<NullWritable, Text> output, Reporter reporter)30 throws IOException {31 output.collect(NullWritable.get(), value);32 }33 34 }35 36 // MultipleTextOutputFormat 继承自MultipleOutputFormat,实现输出文件的分类37 38 public static class PartitionByCountryMTOF extends39 MultipleTextOutputFormat<NullWritable, Text> { // key is40 // NullWritable,41 // value is Text42 protected String generateFileNameForKeyValue(NullWritable key,43 Text value, String filename) {44 String[] arr = value.toString().split(",", -1);45 String country = arr[4].substring(1, 3); // 获取country的名称46 return country + "/" + filename;47 }48 }49 50 // 此处不使用reducer51 /*52 * public static class Reducer extends MapReduceBase implements53 * org.apache.hadoop.mapred.Reducer<LongWritable, Text, NullWritable, Text>54 * {55 *56 * @Override public void reduce(LongWritable key, Iterator<Text> values,57 * OutputCollector<NullWritable, Text> output, Reporter reporter) throws58 * IOException { // TODO Auto-generated method stub59 *60 * }61 *62 * }63 */64 @Override65 public int run(String[] args) throws Exception {66 Configuration conf = getConf();67 JobConf job = new JobConf(conf, MultiFile.class);68 69 Path in = new Path(args[0]);70 Path out = new Path(args[1]);71 72 FileInputFormat.setInputPaths(job, in);73 FileOutputFormat.setOutputPath(job, out);74 75 job.setJobName("MultiFile");76 job.setMapperClass(MapClass.class);77 job.setInputFormat(TextInputFormat.class);78 job.setOutputFormat(PartitionByCountryMTOF.class);79 job.setOutputKeyClass(NullWritable.class);80 job.setOutputValueClass(Text.class);81 82 job.setNumReduceTasks(0);83 JobClient.runJob(job);84 return 0;85 }86 87 public static void main(String[] args) throws Exception {88 int res = ToolRunner.run(new Configuration(), new MultiFile(), args);89 System.exit(res);90 }91 92}1hadoop fs -cat /tmp/multiTest.txt25765303,1998,14046,1996,"AD","",,1,12,42,5,59,11,1,0.4545,0,0,1,67.3636,,,,35785566,1998,14088,1996,"AD","",,1,9,441,6,69,3,0,1,,0.6667,,4.3333,,,,45894770,1999,14354,1997,"AD","",,1,,82,5,51,4,0,1,,0.625,,7.5,,,,55765303,1998,14046,1996,"CN","",,1,12,42,5,59,11,1,0.4545,0,0,1,67.3636,,,,65785566,1998,14088,1996,"CN","",,1,9,441,6,69,3,0,1,,0.6667,,4.3333,,,,75894770,1999,14354,1997,"CN","",,1,,82,5,51,4,0,1,,0.625,,7.5,,,,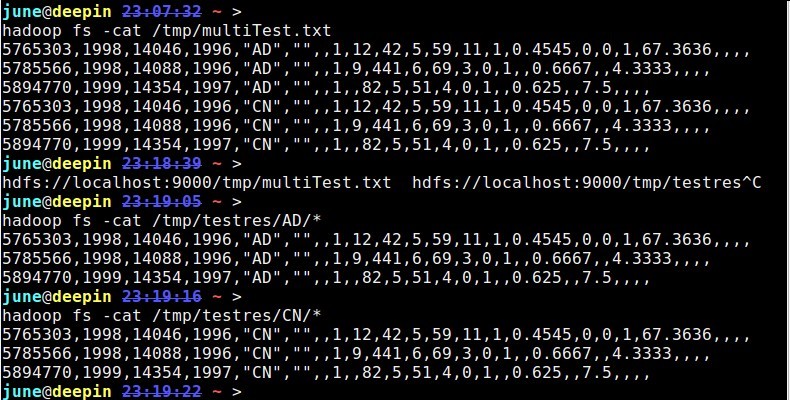
from:
MultipleOutputFormat Example
http://mazd1002.blog.163.com/blog/static/665749652011102553947492/2、新版0.21.x及之后的版本:
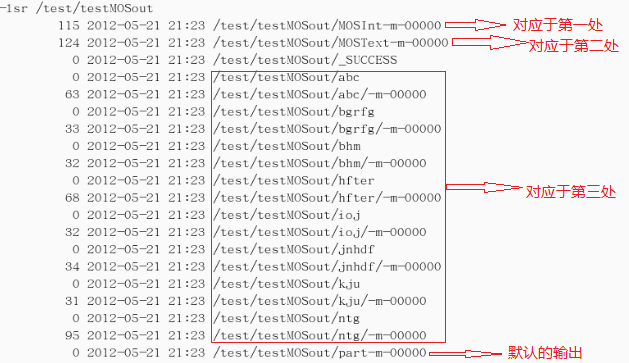
01public class TestwithMultipleOutputs extends Configured implements Tool {02 03 public static class MapClass extends Mapper<LongWritable,Text,Text,IntWritable> {04 05 private MultipleOutputs<Text,IntWritable> mos;06 07 protected void setup(Context context) throws IOException,InterruptedException {08 mos = new MultipleOutputs<Text,IntWritable>(context);09 }10 11 public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{12 String line = value.toString();13 String[] tokens = line.split("-");14 15 mos.write("MOSInt",new Text(tokens[0]), new IntWritable(Integer.parseInt(tokens[1]))); //(第一处)16 mos.write("MOSText", new Text(tokens[0]),tokens[2]); //(第二处)17 mos.write("MOSText", new Text(tokens[0]),line,tokens[0]+"/"); //(第三处)同时也可写到指定的文件或文件夹中18 }19 20 protected void cleanup(Context context) throws IOException,InterruptedException {21 mos.close();22 }23 24 }25 public int run(String[] args) throws Exception {26 27 Configuration conf = getConf();28 29 Job job = new Job(conf,"word count with MultipleOutputs");30 31 job.setJarByClass(TestwithMultipleOutputs.class);32 33 Path in = new Path(args[0]);34 Path out = new Path(args[1]);35 36 FileInputFormat.setInputPaths(job, in);37 FileOutputFormat.setOutputPath(job, out);38 39 job.setMapperClass(MapClass.class);40 job.setNumReduceTasks(0); 41 42 MultipleOutputs.addNamedOutput(job,"MOSInt",TextOutputFormat.class,Text.class,IntWritable.class);43 MultipleOutputs.addNamedOutput(job,"MOSText",TextOutputFormat.class,Text.class,Text.class);44 45 System.exit(job.waitForCompletion(true)?0:1);46 return 0;47 }48 49 public static void main(String[] args) throws Exception {50 51 int res = ToolRunner.run(new Configuration(), new TestwithMultipleOutputs(), args);52 System.exit(res);53 }54 55}测试的数据:
abc-1232-hdf
abc-123-rtd
ioj-234-grjth
ntg-653-sdgfvd
kju-876-btyun
bhm-530-bhyt
hfter-45642-bhgf
bgrfg-8956-fmgh
jnhdf-8734-adfbgf
ntg-68763-nfhsdf
ntg-98634-dehuy
hfter-84567-drhuk
结果截图:(结果输出到/test/testMOSout)
PS:遇到的一个问题:
如果没有mos.close(), 程序运行中会出现异常:
12/05/21 20:12:47 WARN hdfs.DFSClient: DataStreamer Exception:
org.apache.hadoop.ipc.RemoteException:org.apache.hadoop.hdfs.server.namenode.LeaseExpiredException: No lease on
/test/mosreduce/_temporary/_attempt_local_0001_r_000000_0/h-r-00000 File does not exist. [Lease. Holder: DFSClient_-352105532, pendingcreates: 5]
from:
MultipleOutputFormat和MultipleOutputs
http://www.cnblogs.com/liangzh/archive/2012/05/22/2512264.html
Hadoop利用Partitioner对输出文件分类(改写partition,路由到指定的文件中)
http://superlxw1234.iteye.com/blog/1495465
http://ghost-face.iteye.com/blog/1869926
更多参考&推荐阅读:
1、【Hadoop】利用MultipleOutputs,MultiOutputFormat实现以不同格式输出到多个文件
http://www.cnblogs.com/iDonal/archive/2012/08/07/2626588.html
2、cdh3u3 hadoop 0.20.2 MultipleOutputs 多输出文件初探
http://my.oschina.net/wangjiankui/blog/49521
3、使用MultipleOutputs
http://blog.163.com/ecy_fu/blog/static/444512620101274344951/
4、Hadoop reduce多个输出
http://blog.csdn.net/inte_sleeper/article/details/7042020
5、Hadoop 0.20.2中怎么使用MultipleOutputFormat实现多文件输出和完全自定义文件名
http://www.cnblogs.com/flying5/archive/2011/05/04/2078407.html
6、Hadoop OutputFormat浅析
http://zhb-mccoy.iteye.com/blog/1591635
7、others:
https://sites.google.com/site/hadoopandhive/home/how-to-write-output-to-multiple-named-files-in-hadoop-using-multipletextoutputformat
https://issues.apache.org/jira/browse/HADOOP-3149
http://grokbase.com/t/hadoop/common-user/112ewx7s15/could-i-write-outputs-in-multiple-directories
8、MultipleOutputs 官方范例
http://hadoop.apache.org/docs/stable/api/org/apache/hadoop/mapreduce/lib/output/MultipleOutputs.html
9、多数据源输入:MultipleInputs
http://stackoverflow.com/questions/17456369/mapreduce-job-with-mixed-data-sources-hbase-table-and-hdfs-files
https://groups.google.com/forum/#!topic/nosql-databases/SH61smOV-mo
http://bigdataprocessing.wordpress.com/2012/07/27/hadoop-hbase-mapreduce-examples/
http://hbase.apache.org/book/mapreduce.example.html
- MapReduce中的自定义多目录/文件名输出HDFS
- MapReduce中的自定义多目录/文件名输出HDFS
- MapReduce中的自定义多目录/文件名输出<转>
- MapReduce-MulitipleOutputs实现自定义输出到多个目录
- mapreduce多目录输出(MultipleOutputFormat和MultipleOutputs)
- hadoop自定义输出文件名
- 自定义输出文件名
- hadoop自定义输出文件名
- MapReduce 编程 系列八 根据输入路径产生输出路径和清除HDFS目录
- 实现mapreduce多文件自定义输出
- 实现mapreduce多文件自定义输出
- 实现mapreduce多文件自定义输出
- mapreduce实现多文件自定义输出
- 实现MapReduce多文件自定义输出
- mapreduce获取输入文件名、输出路径
- Hadoop MapReduce 修改输出文件名 MultipleOutputs
- 自定义MapReduce导入HDFS数据到HBase
- Hadoop的多文件输出及自定义文件名
- oracle dual表
- 启动app ,EditText失去焦点,点击获取焦点
- 在网页中交互unity3d
- 深入浅出图解C#堆与栈 C# Heap(ing) VS Stack(ing) 第五节 引用类型复制问题及用克隆接口ICloneable修复
- Linux下Makefile的automake生成全攻略
- MapReduce中的自定义多目录/文件名输出HDFS
- IOS汉字编码转化 分类: IOS
- 关于PropertyEditorSupport
- oracle 选择数据块大小
- 24.1 Lua debug library
- innobackupex参数说明
- 单例设计模式
- C#开发日志[2013-12-5]创建Bitmap引发"参数无效"异常
- Android 画图方式总结


