一些算法的MapReduce实现——最小生成树
来源:互联网 发布:科幻电影推荐 知乎 编辑:程序博客网 时间:2024/06/03 20:51
最小生成树算法学习
以下转载自:http://blog.csdn.net/fengchaokobe/article/details/7521780
正文
所谓最小生成树,就是在一个具有N个顶点的带权连通图G中,如果存在某个子图G',其包含了图G中的所有顶点和一部分边,且不形成回路,并且子图G'的各边权值之和最小,则称G'为图G的最小生成树。
由定义我们可得知最小生成树的三个性质:
•最小生成树不能有回路。
•最小生成树可能是一个,也可能是多个。
•最小生成树边的个数等于顶点的个数减一。
本文将介绍两种最小生成树的算法,分别为克鲁斯卡尔算法(Kruskal Algorithm)和普利姆算法(Prim Algorithm)。
第一节 克鲁斯卡尔算法(Kruskal Algorithm)
克鲁斯卡尔算法的核心思想是:在带权连通图中,不断地在边集合中找到最小的边,如果该边满足得到最小生成树的条件,就将其构造,直到最后得到一颗最小生成树。
克鲁斯卡尔算法的执行步骤:
第一步:在带权连通图中,将边的权值排序;
第二步:判断是否需要选择这条边(此时图中的边已按权值从小到大排好序)。判断的依据是边的两个顶点是否已连通,如果连通则继续下一条;如果不连通,那么就选择使其连通。
第三步:循环第二步,直到图中所有的顶点都在同一个连通分量中,即得到最小生成树。
下面我用图示法来演示克鲁斯卡尔算法的工作流程,如下图:
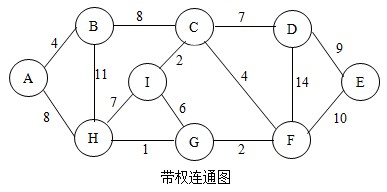
所谓最小生成树,就是在一个具有N个顶点的带权连通图G中,如果存在某个子图G',其包含了图G中的所有顶点和一部分边,且不形成回路,并且子图G'的各边权值之和最小,则称G'为图G的最小生成树。
由定义我们可得知最小生成树的三个性质:
•最小生成树不能有回路。
•最小生成树可能是一个,也可能是多个。
•最小生成树边的个数等于顶点的个数减一。
本文将介绍两种最小生成树的算法,分别为克鲁斯卡尔算法(Kruskal Algorithm)和普利姆算法(Prim Algorithm)。
第一节 克鲁斯卡尔算法(Kruskal Algorithm)
克鲁斯卡尔算法的核心思想是:在带权连通图中,不断地在边集合中找到最小的边,如果该边满足得到最小生成树的条件,就将其构造,直到最后得到一颗最小生成树。
克鲁斯卡尔算法的执行步骤:
第一步:在带权连通图中,将边的权值排序;
第二步:判断是否需要选择这条边(此时图中的边已按权值从小到大排好序)。判断的依据是边的两个顶点是否已连通,如果连通则继续下一条;如果不连通,那么就选择使其连通。
第三步:循环第二步,直到图中所有的顶点都在同一个连通分量中,即得到最小生成树。
下面我用图示法来演示克鲁斯卡尔算法的工作流程,如下图:
首先,将图中所有的边排序(从小到大),我们将以此结果来选择。排序后各边按权值从小到大依次是:
HG < (CI=GF) < (AB=CF) < GI < (CD=HI) < (AH=BC) < DE < BH < DF
接下来,我们先选择HG边,将这两个点加入到已找到点的集合。这样图就变成了,如图
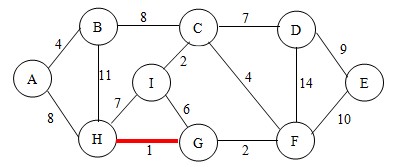
继续,这次选择边CI(当有两条边权值相等时,可随意选一条),此时需做判断。
判断法则:当将边CI加入到已找到边的集合中时,是否会形成回路?
1.如果没有形成回路,那么直接将其连通。此时,对于边的集合又要做一次判断:这两个点是否在已找到点的集合中出现过?
①.如果两个点都没有出现过,那么将这两个点都加入已找到点的集合中;
②.如果其中一个点在集合中出现过,那么将另一个没有出现过的点加入到集合中;
③.如果这两个点都出现过,则不用加入到集合中。
2.如果形成回路,不符合要求,直接进行下一次操作。
根据判断法则,不会形成回路,将点C和点I连通,并将点C和点I加入到集合中。如图:
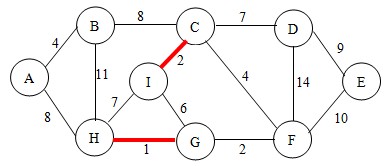
继续,这次选择边GF,根据判断法则,不会形成回路,将点G和点F连通,并将点F加入到集合中。如图:

继续,这次选择边AB,根据判断法则,不会形成回路,将其连通,并将点A和点B加入到集合中。如图:

继续,这次选择边CF,根据判断法则,不会形成回路,将其连通,此时这两个点已经在集合中了,所以不用加入。如图:
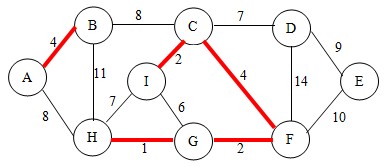
继续,这次选择边GI,根据判断法则,会形成回路,如下图,直接进行下一次操作。

继续,这次选择边CD,根据判断法则,不会形成回路,将其连通,并将点D加入到集合中。如图:

继续,这次选择边HI,根据判断法则,会形成回路,直接进行下一次操作。
继续,这次选择边AH,根据判断法则,不会形成回路,将其连通,此时这两个点已经在集合中了,所以不用加入。
继续,这次选择边BC,根据判断法则,会形成回路,直接进行下一次操作。
继续,这次选择边DE,根据判断法则,不会形成回路,将其连通,并将点E加入到集合中。如图:
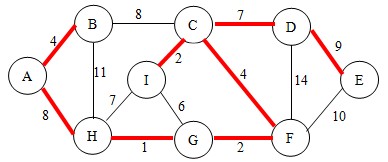
继续,这次选择边BH,根据法则,会形成回路,进行下一次操作。
最后选择边DF,根据法则,会形成回路,不将其连通,也不用加入到集合中。
好了,所有的边都遍历完成了,所有的顶点都在同一个连通分量中,我们得到了这颗最小生成树。
通过生成的过程可以看出,能否得到最小生成树的核心问题就是上面所描述的判断法则。那么,我们如何用算法来描述判断法则呢?我认为只需要三个步骤即可:
⒈将某次操作选择的边XY的两个顶点X和Y和已找到点的集合作比较,如果
①.这两个点都在已找到点的集合中,那么return 2;
②.这两个点有一个在已找到点的集合中,那么return 1;
③这两个点都不在一找到点的集合中,那么return 0;
⒉当返回值为0或1时,可判定不会形成回路;
⒊当返回值为2时,判定能形成回路的依据是:假如能形成回路,设能形成回路的点的集合中有A,B,C,D四个点,那么以点A为起始点,绕环路一周后必能回到点A。如果能回到,则形成回路;如果不能,则不能形成回路。
判断法则:当将边CI加入到已找到边的集合中时,是否会形成回路?
1.如果没有形成回路,那么直接将其连通。此时,对于边的集合又要做一次判断:这两个点是否在已找到点的集合中出现过?
①.如果两个点都没有出现过,那么将这两个点都加入已找到点的集合中;
②.如果其中一个点在集合中出现过,那么将另一个没有出现过的点加入到集合中;
③.如果这两个点都出现过,则不用加入到集合中。
2.如果形成回路,不符合要求,直接进行下一次操作。
根据判断法则,不会形成回路,将点C和点I连通,并将点C和点I加入到集合中。如图:
继续,这次选择边AH,根据判断法则,不会形成回路,将其连通,此时这两个点已经在集合中了,所以不用加入。
继续,这次选择边BC,根据判断法则,会形成回路,直接进行下一次操作。
继续,这次选择边DE,根据判断法则,不会形成回路,将其连通,并将点E加入到集合中。如图:
最后选择边DF,根据法则,会形成回路,不将其连通,也不用加入到集合中。
好了,所有的边都遍历完成了,所有的顶点都在同一个连通分量中,我们得到了这颗最小生成树。
通过生成的过程可以看出,能否得到最小生成树的核心问题就是上面所描述的判断法则。那么,我们如何用算法来描述判断法则呢?我认为只需要三个步骤即可:
⒈将某次操作选择的边XY的两个顶点X和Y和已找到点的集合作比较,如果
①.这两个点都在已找到点的集合中,那么return 2;
②.这两个点有一个在已找到点的集合中,那么return 1;
③这两个点都不在一找到点的集合中,那么return 0;
⒉当返回值为0或1时,可判定不会形成回路;
⒊当返回值为2时,判定能形成回路的依据是:假如能形成回路,设能形成回路的点的集合中有A,B,C,D四个点,那么以点A为起始点,绕环路一周后必能回到点A。如果能回到,则形成回路;如果不能,则不能形成回路。
最小生成树的MapReduce实现
如下图,求下图中的最小生成树

Input Format
edge_weight<tab>source<tab>destination
上图的输入格式为:
6<tab>A<tab>C5<tab>C<tab>E3<tab>C<tab>F2<tab>C<tab>D1<tab>B<tab>C2<tab>B<tab>D4<tab>A<tab>D4<tab>E<tab>F4<tab>D<tab>F5<tab>A<tab>B
Output Format
edge_weight<tab>source:destination
上图的输出结果为:
1<tab>B:C2<tab>C:D3<tab>C:F4<tab>A:D4<tab>E:F
结果图如下

该最小生成树的权重和为14
MSTMapper
MSTMapper 读取输入的数据,然后重新组织每一条记录,最后以key/value的形式提交给Reducer,其中key为边的权重,value是该边的起始node和终止node
代码如下
/** * * @author Deepika Mohan * * * Description : MSTMapper class that emits the input records in the * form of <key, value> pairs where the key is the weight and the * value is the source, destination pair. MapReduce has automatic * sorting by keys after the map phase. This property can be used to * sort the weights of the given graph. Therefore we have a mapper, * the output of which will have the data sorted by keys which are * weights in this program. So the reducer will get the edges in the * order of increasing weight. * * Input format : <key, value>: <automatically assigned key, * weight<tab>source<tab>destination> * * Output format: <key, value>: < weight,source:destination> * * * Hadoop version used : 0.20.2 */ // the type parameters are the input keys type, the input values type, the // output keys type, the output values type public static class MSTMapper extends Mapper<Object, Text, IntWritable, Text> { public void map(Object key, Text value, Context context) throws IOException, InterruptedException { Text srcDestPair = new Text(); // StringTokenizer itr = new StringTokenizer(value.toString()); String[] inputTokens = value.toString().split("\t"); String weight = inputTokens[0]; // get the weight int wt = Integer.parseInt(weight); IntWritable iwWeight = new IntWritable(wt); // setting the source and destination to the key value srcDestPair.set(inputTokens[1] + ":" + inputTokens[2]); // write <key, value> to context where the key is the weight, and the // value is the sourceDestinationPair context.write(iwWeight, srcDestPair); } }MSTReducer
经过Map阶段之后,key/value对被按照keys来排好序。下面的Reducer代码中有三个boolean变量,他们是来判断,1、该边是否已经被处理过了或者已经在最小生成集合了,是的话就忽略;2、该边加入到最小生成集合中是否会形成回路,是的话就忽略。
这个最小生成树的例子中,reducer的数目必须有且只有一个。如果该算法用多个reducer来实现的话,那么map过后,边会被按照key值划分,分到不同的reducer中。而Kruskal算法处理的边需要按照升序排列依次被处理,开始的最小生成树学习中有提到。如果在多个reduce的情况下,那么这个升序处理就没法被保重,可能导致不正确的结果。reducer代码如下:
/** * MSTReducer is based on Kruskal's algorithm. * * Reference: * http://www.personal.kent.edu/~rmuhamma/Algorithms/MyAlgorithms/GraphAlgor * /kruskalAlgor.htm * * Kruskal's algorithm : the MST is built as a forest. The edges are sorted by * weights and considered in the increasing order of the weights. Each vertex * is in its tree in the forest. Each edge is taken and if the end nodes of * the edge belong to disjoint trees , then they are merged and the edge is * considered to be in the MST. Else, the edge is discarded. * */ // The reducer to form the minimum spanning tree based on Kruskal's algorithm static class MSTReducer extends Reducer<IntWritable, Text, Text, Text> { /** * Map to hold the information about the set of nodes that are in the same * tree as the given node, each node is mapped to a set of nodes where the * set represents the nodes that are present in the same tree **/ Map<String, Set<String>> node_AssociatedSet = new HashMap<String, Set<String>>(); public void reduce(IntWritable inputKey, Iterable<Text> values, Context context) throws IOException, InterruptedException { // values represent the source, destination pair that have inputKey as its // edge weight // converting the type of inputKey to a Text String strKey = new String(); strKey += inputKey; Text outputKey = new Text(strKey); for (Text val : values) { // boolean values to check if the two nodes belong to the same tree, // useful for cycle detection boolean ignoreEdgeSameSet1 = false; boolean ignoreEdgeSameSet2 = false; boolean ignoreEdgeSameSet3 = false; Set<String> nodesSet = new HashSet<String>(); // split the srcDestination pair and add to the set, here the delimiter // character to split the strings is ":" because // the mapper used the same delimiter to append the source and // destination, some other delimiter can also be used. String[] srcDest = val.toString().split(":"); // getting the two nodes of an edge String src = srcDest[0]; String dest = srcDest[1]; // check if src and dest belong to the same tree/set, if so, ignore the // edge ignoreEdgeSameSet1 = isSameSet(src, dest); // form the verticesSet nodesSet.add(src); nodesSet.add(dest); ignoreEdgeSameSet2 = unionSet(nodesSet, src, dest); ignoreEdgeSameSet3 = unionSet(nodesSet, dest, src); // if all the following three boolean values are false, then adding the // edge to the tree will not form a cycle // therefore add the edge to the tree or write the edge to the output if (!ignoreEdgeSameSet1 && !ignoreEdgeSameSet2 && !ignoreEdgeSameSet3) { long weight = Long.parseLong(outputKey.toString()); // increment the counter by the weight value, the counter holds the // total weight of the minimum spanning tree context.getCounter(MSTCounters.totalWeight).increment(weight); // write the weight and srcDestination pair to the output context.write(outputKey, val); } } }unionSet方法
该方法用于将作为参数的两个节点nodes的各自的tree合并。最小生成树最终就是建立一个forest。每个node都有一个tree。在这个程序中。“Set”和“Tree”的概念是相互转换的使用的。一开始初始化每个node为一个tree,该tree仅包含自己。之后的一些合并操作最终会使其成为一个tree。本程序用一个Map来存储每个node的tree信息。如程序所示,如果Map不含有node1,将其和其关联的tree(or set)添加到map中。具体看代码,如下:
// method to unite the set of the two nodes - node1 and node2, this is // useful to add edges to the tree without forming cycles private boolean unionSet(Set<String> nodesSet, String node1, String node2) { boolean ignoreEdge = false;// boolean value to determine whether to ignore // the edge // if the map does not contain the key, add the key, value pair if (!node_AssociatedSet.containsKey(node1)) { node_AssociatedSet.put(node1, nodesSet); } else { // get the set associated with the key Set<String> associatedSet = node_AssociatedSet.get(node1); Set<String> nodeSet = new HashSet<String>(); nodeSet.addAll(associatedSet); Iterator<String> nodeItr = nodeSet.iterator(); Iterator<String> duplicateCheckItr = nodeSet.iterator(); // first check if the second node is contained in any of the sets from // node1 to nodeN // if so, ignore the edge as the two nodes belong to the same set/tree while (duplicateCheckItr.hasNext()) { String node = duplicateCheckItr.next(); if (node_AssociatedSet.get(node).contains(node2)) { ignoreEdge = true; } } // if the associatedSet contains elements {node1 , node2, .., nodeN} // get the sets associated with each of the element from node1 to nodeN while (nodeItr.hasNext()) { String nextNode = nodeItr.next(); if (!node_AssociatedSet.containsKey(nextNode)) { node_AssociatedSet.put(nextNode, nodesSet); } // add the src and dest to the set associated with each of the // elements in the associatedSet // the src and dest will get added to the set associated with node1 to // nodeN node_AssociatedSet.get(nextNode).addAll(nodesSet); } } return ignoreEdge; }// method to determine if the two nodes belong to the same set // this is done by iterating through the map and checking if any of the set // contains the two nodes private boolean isSameSet(String src, String dest) { boolean ignoreEdge = false; // boolean value to check whether the edge // should be ignored // iterating through the map for (Map.Entry<String, Set<String>> node_AssociatedSetValue : node_AssociatedSet .entrySet()) { Set<String> nodesInSameSet = node_AssociatedSetValue.getValue(); // if the src and dest of an edge are in the same set, ignore the edge if (nodesInSameSet.contains(src) && nodesInSameSet.contains(dest)) { ignoreEdge = true; } } return ignoreEdge; }以上最小生成树的过程翻译自[1]
但是有个问题,单个reducer,里面需要一个额外的Map数据结构node_AssociatedSet来存储所有的nodes的信息,如果内存优先的话,该部就无法完成。只能写disk来完成,大家可以想想有没有更好的解法。
是否还有优化空间?减少中间结果的生成来提速。后续有想法在补充吧。暂时还在学习阶段。
以上有哪里不对的地方,还望指出,不胜感激!~!
Reference
1、http://hadooptutorial.wikispaces.com/Sorting+feature+of+MapReduce
完整代码下载
0 0
- 一些算法的MapReduce实现——最小生成树
- MapReduce 实现最小生成树
- 关于图ADT的一些算法——最小生成树算法(普利姆/Prim算法)
- 一些算法的MapReduce实现——好友推荐
- 一些算法的MapReduce实现——MapReduce Job的单元测试实例
- 最小生成树算法——Kruskal算法Java实现
- 最小生成树的prim算法实现
- 最小生成树的prim算法实现
- 最小生成树Kruskal算法的实现
- 最小生成树的Prim算法实现
- 最小生成树—Prim的实现
- 最小生成树——prim算法实现
- C语言——Prim算法实现最小生成树
- 构造最小生成树的算法——Prim算法
- 一些算法的MapReduce实现——矩阵相乘一步实现
- 一些算法的MapReduce实现——矩阵-向量乘法实现
- 一些算法的MapReduce实现——倒排索引实现
- 最小生成树算法—kcruscal算法
- 针对UAC安全的研究与思考
- android最新源码(4.4.2_r1版本以上)下载
- 最炫丽的网页平面UI课程就在广州传智播客
- hbase 常用操作
- Java解析Json(org.json,json-lib)
- 一些算法的MapReduce实现——最小生成树
- 【虚拟化基础知识培训】为什么需要了解下虚拟化
- NDK java和c参数传递
- AVCaptureSession拍照时如何设置扫描速率
- FastReport经验汇总
- Oracle RAC ASM 实例 从10.2.0.1 升级到 10.2.0.4 说明
- 中国共产党十大元帅和十大大将
- 【discuz x3】家园页面产生的动态
- Concurrent Programming with Processes


