SQL SERVER插入数据操作
来源:互联网 发布:表格软件扫描录入 编辑:程序博客网 时间:2024/06/05 19:43
准备工作:
我需要一张User表,这张表有几个字段,还有一个自增长的数字id,表结构如下:

这是一张比现实应用中简单的多的用户表,UserID是自增长字段。
开始执行一个最简单的INSERT:
INSERT INTO [DB_BJ].[dbo].[User] ([UserName] ,[Email] ,[Signature] ,[CreateTime] ,[IP]) VALUES ('yukaizhao' ,'yukaizhao@abc.com' ,'My Blog ishttp://www.cnblogs.com/yukaizhao/' ,'2010-06-01' ,'127.0.0.1')我们在sql server管理器中,选中工具栏中的显示执行计划的图标(下图),并执行语句: 
其执行计划如下所示: 
查询计划显示sql server执行的sql并非我们写的原始sql,sql server先智能的将我们的sql语句转换为一个参数话的sql,如下:
INSERT INTO [DB_BJ].[dbo].[User]([UserName],[Email],[Signature],[CreateTime],[IP])values(@1,@2,@3,@4,@5)Sql server做了这步转换之后就可以让使用不同参数的sql可以使用同一个经过预编译的sql语句。
我们从执行计划的各个步骤看一下这个insert的执行过程,注意看sql server的执行计划要从右往左看.
1. 常量扫描做的工作是根据用户输入的sql中的常量生成一个行
MSDN的原话如下:
"The Constant Scan operator introduces one or more constant rows into a query. A Compute Scalar operator is often used after a Constant Scan to add columns to a row produced by the Constant Scan operator"
上面的话是MSDN上的解释,常量扫描会引入一个或者多个常量行到一个查询中;通常情况下紧跟常量扫描的是计算标量运算符,计算标量运算符会为常量扫描运算符产生的行添加列。
2. 计算标量,在这一步生成了自增id的值,请看下图,这一步输出了一个表达式Expr1003,为什么这个输出值是自增id,请看第4中的图

3. 第二个计算标量,将原始sql中的常量值赋给5个变量
4. 聚集索引插入,执行插入操作,将数据加入到数据表中,请看下图:
图中的第一个红框是给UserName赋值的表达式,[DB_BJ].[dbo].[User].[UserName] = RaiseIfNull([Expr1004]) ,这个谓词中的DB_BJ是我的测试数据库名字,RaiseIfNull应该是sql server自动添加的函数,用来在参数值为NULL是抛出异常;但是这个函数是不允许用户调用的。
第二个红框是给UserID赋值的,这里可以印证我们在第2步中的推断。
5. 最后一步是Insert,这一步将输入的sql语句的执行计划存储起来以便复用。
这只是一个最简单的INSERT语句的分析,下一篇我们继续分析一个稍微复杂一点的INSERT。
分析一下带外键表的INSERT的例子。

本文所用的数据表结构如上图所示;其中Blog表上BlogID是自增的主键,并在CreateUserID和CreateTime列上分别建有两个非唯一索引。
我们要往Blog表中插入一条数据,并分析其执行情况。
INSERT 语句如下:
INSERT INTO [DB_Cn].[dbo].[Blog] ([Title] ,[Tags] ,[Content] ,[CreateUserID] ,[CreateTime] ,[IP]) VALUES ('这是一个测试博客标题' ,'测试' ,'这是测试博客的内容,博主的地址是http://www.cnblogs.com/yukaizhao/' ,100 ,'2010-01-06' ,'127.0.0.1');
其执行计划要稍微复杂一些,如下所示
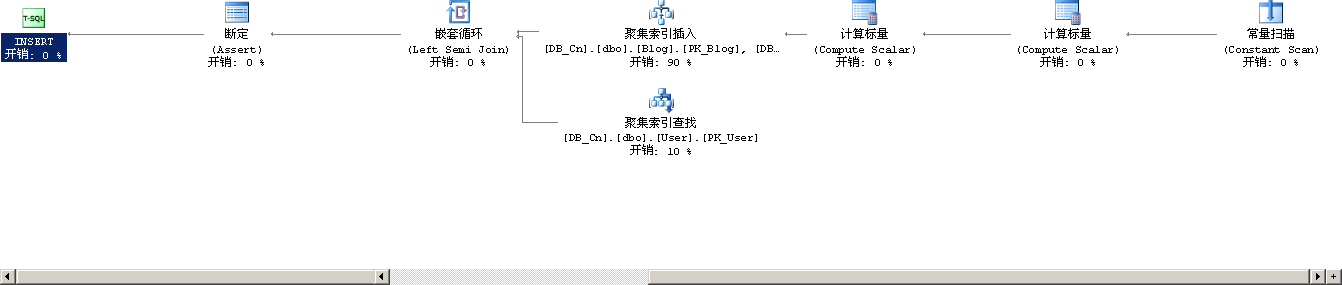
从右向左分析,第一步中的常量扫描是根据用户输入的sql语句生成一个数据行;第一个常量扫描生成了一个新的自增长id;第二个计算标量则是计算用户输入的sql语句中的常量值,这些在上一篇文章中有详细的叙述,请参考上文。
第四步是分叉的两步操作,上面的操作是聚集索引插入,下一步的操作是对User表的聚集索引查找,如下图是聚集索引插入的详细情况:

逻辑索引插入的部分估计开销为90%,这一步插入Blog表的主键,Blog表的两个索引IX_Blog和IX_Blog_CreateTime,对这两个索引的操作说明了在表中建索引会对表的插入操作效率产生负面影响;由于Blog表的CreateUserID字段是个外键,所以这一步还有一个输出列表输出了CreateUserID字段;这个字段要用来做外键是否存在的判断。
我们再看下对User表的聚集索引查找操作的详细情况:

这步中查找的对象是PK_User及User表的主键,主键的扫描是非常迅速的,尽管如此当User表非常大时,扫描的开销也是非常可观的。这里扫描的开销可以分为两个部分,一部分是cpu的开销,另外一个方面是扫描时sql server会自动给主键加上一个共享锁,既然加锁就有可能会造成死锁或排他锁的等待。
从这一步看如果我们对响应速度的要求远大于对数据一致性的要求时,可以考虑删掉外键,去掉这一步不必要的开销。
第五步:对第四步两个分叉操作产生的输出进行嵌套循环,这一步嵌套循环是为下一步的Assert做准备
第六部:Assert判断嵌套循环产生的CreateUserID是否为NULL,如果为NULL则会引发外键不存在的异常
最后一步执行INSERT操作。
从以上分析可以得出几点心得
1. 为什么使用自增长字段,在插入数据失败时自增长字段的编号会被占用?
因为自增长字段的值是在第二部计算标量是产生的,这一步已经将自增id加1了
2. 为什么给表建的索引多了会影响插入的性能
因为每一次插入都需要对每一个索引进行插入
3. 为什么在做大并发设计时,会不建外键,或将外键删除掉
因为外键会带来额外的cpu开销和锁资源的开销
- SQL SERVER插入数据操作
- [SQL Server] 批量插入数据
- Sql Server 循环插入数据
- 【SQL server】数据的插入
- SQL Server 插入空间数据
- 【SQL Server 批量插入数据】
- SQL server触发器、存储过程操作远程数据库插入数据,解决服务器已存在的问题
- sql server 数据的循环插入
- ACCESS数据插入到SQL SERVER
- sql server 跨数据库插入数据
- 连接Sql Server 查询、插入数据
- 将DataTable 数据插入 SQL SERVER 数据库
- SQL SERVER 批量数据插入方法
- SQL SERVER 快速插入千万条数据
- SQL Server 批量插入数据的方法
- SQL Server中,插入数据insert注意事项
- sql server 关于表数据的插入
- sql server 脚本插入一百五十万数据
- 深入理解容器系列片之四--------HashMap原理
- 南阳 8 一种排序
- 有关定时器收藏~
- 教你在 Debian 和 Ubuntu 上升级 MySQL
- easyui field 获取对象属性的值
- SQL SERVER插入数据操作
- DBUtils批量处理操作
- linux命令 sync
- 南阳 139 我排第几个
- IE6查看ActiveX控件是否已经安装以及版本号
- Error using pdist2 Too many input arguments
- NSAttributedString详解
- OER Voice Traffic Optimization Using Active Probes
- Linux下nm和ldd 命令


