浅拷贝和深拷贝
来源:互联网 发布:大数据时代的营销变革 编辑:程序博客网 时间:2024/05/16 19:24
C++中对象的复制就如同“克隆”,用一个已有的对象快速地复制出多个完全相同的对象。一般而言,以下三种情况都会使用到对象的复制:
(1)建立一个新对象,并用另一个同类的已有对象对新对象进行初始化,例如:
- class Rect
- {
- private:
- int width;
- int height;
- };
- Rect rect1;
- Rect rect2(rect1); // 使用rect1初始化rect2,此时会进行对象的复制
(2)当函数的参数为类的对象时,这时调用此函数时使用的是值传递,也会产生对象的复制,例如:
- void fun1(Rect rect)
- {
- ...
- }
- int main()
- {
- Rect rect1;
- fun1(rect1); // 此时会进行对象的复制
- return 0;
- }
(3)函数的返回值是类的对象时,在函数调用结束时,需要将函数中的对象复制一个临时对象并传给改函数的调用处,例如:
- Rect fun2()
- {
- Rect rect;
- return rect;
- }
- int main()
- {
- Rect rect1;
- rect1=fun2();
- // 在fun2返回对象时,会执行对象复制,复制出一临时对象,
- // 然后将此临时对象“赋值”给rect1
- return 0;
- }
对象的复制都是通过一种特殊的构造函数来完成的,这种特殊的构造函数就是拷贝构造函数(copy constructor,也叫复制构造函数)。拷贝构造函数在大多数情况下都很简单,甚至在我们都不知道它存在的情况下也能很好发挥作用,但是在一些特殊情况下,特别是在对象里有动态成员的时候,就需要我们特别小心地处理拷贝构造函数了。下面我们就来看看拷贝构造函数的使用。
一、默认拷贝构造函数
很多时候在我们都不知道拷贝构造函数的情况下,传递对象给函数参数或者函数返回对象都能很好的进行,这是因为编译器会给我们自动产生一个拷贝构造函数,这就是“默认拷贝构造函数”,这个构造函数很简单,仅仅使用“老对象”的数据成员的值对“新对象”的数据成员一一进行赋值,它一般具有以下形式:
- Rect::Rect(const Rect& r)
- {
- width = r.width;
- height = r.height;
- }
当然,以上代码不用我们编写,编译器会为我们自动生成。但是如果认为这样就可以解决对象的复制问题,那就错了,让我们来考虑以下一段代码:
- class Rect
- {
- public:
- Rect() // 构造函数,计数器加1
- {
- count++;
- }
- ~Rect() // 析构函数,计数器减1
- {
- count--;
- }
- static int getCount() // 返回计数器的值
- {
- return count;
- }
- private:
- int width;
- int height;
- static int count; // 一静态成员做为计数器
- };
- int Rect::count = 0; // 初始化计数器
- int main()
- {
- Rect rect1;
- cout<<"The count of Rect: "<<Rect::getCount()<<endl;
- Rect rect2(rect1); // 使用rect1复制rect2,此时应该有两个对象
- cout<<"The count of Rect: "<<Rect::getCount()<<endl;
- return 0;
- }
这段代码对前面的类进行了一下小小的修改,加入了一个静态成员,目的是进行计数,统计创建的对象的个数,在每个对象创建时,通过构造函数进行递增,在销毁对象时,通过析构函数进行递减。在主函数中,首先创建对象rect1,输出此时的对象个数,然后使用rect1复制出对象rect2,再输出此时的对象个数,按照理解,此时应该有两个对象存在,但实际程序运行时,输出的都是1,反应出只有1个对象。此外,在销毁对象时,由于会调用销毁两个对象,类的析构函数会调用两次,此时的计数器将变为负数。出现这些问题最根本就在于在复制对象时,计数器没有递增,解决的办法就是重新编写拷贝构造函数,在拷贝构造函数中加入对计数器的处理,形成的拷贝构造函数如下:
- class Rect
- {
- public:
- Rect() // 构造函数,计数器加1
- {
- count++;
- }
- Rect(const Rect& r) // 拷贝构造函数
- {
- width = r.width;
- height = r.height;
- count++; // 计数器加1
- }
- ~Rect() // 析构函数,计数器减1
- {
- count--;
- }
- static int getCount() // 返回计数器的值
- {
- return count;
- }
- private:
- int width;
- int height;
- static int count; // 一静态成员做为计数器
- };
自己编写拷贝构造函数又可以分为两种情况——浅拷贝与深拷贝。
二、浅拷贝
所谓浅拷贝,指的是在对象复制时,只是对对象中的数据成员进行简单的赋值,上面的例子都是属于浅拷贝的情况,默认拷贝构造函数执行的也是浅拷贝。大多情况下“浅拷贝”已经能很好地工作了,但是一旦对象存在了动态成员,那么浅拷贝就会出问题了,让我们考虑如下一段代码:
- class Rect
- {
- public:
- Rect() // 构造函数,p指向堆中分配的一空间
- {
- p = new int(100);
- }
- ~Rect() // 析构函数,释放动态分配的空间
- {
- if(p != NULL)
- {
- delete p;
- }
- }
- private:
- int width;
- int height;
- int *p; // 一指针成员
- };
- int main()
- {
- Rect rect1;
- Rect rect2(rect1); // 复制对象
- return 0;
- }
在这段代码运行结束之前,会出现一个运行错误。原因就在于在进行对象复制时,对于动态分配的内容没有进行正确的操作。我们来分析一下:
在运行定义rect1对象后,由于在构造函数中有一个动态分配的语句,因此执行后的内存情况大致如下:
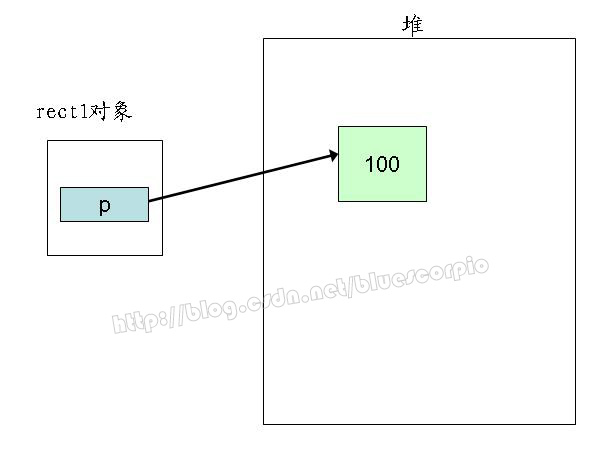
在使用rect1复制rect2时,由于执行的是浅拷贝,只是将成员的值进行赋值,所以此时rect1.p和rect2.p具有相同的值,也即这两个指针指向了堆里的同一个空间,如下图所示:
![]()
当然,这不是我们所期望的结果,在销毁对象时,两个对象的析构函数将对同一个内存空间释放两次,这就是错误出现的原因。我们需要的不是两个p有相同的值,而是两个p指向的空间有相同的值,解决办法就是使用“深拷贝”。
三、深拷贝
在“深拷贝”的情况下,对于对象中动态成员,就不能仅仅简单地赋值了,而应该重新动态分配空间,如上面的例子就应该按照如下的方式进行处理:
- class Rect
- {
- public:
- Rect() // 构造函数,p指向堆中分配的一空间
- {
- p = new int(100);
- }
- Rect(const Rect& r)
- {
- width = r.width;
- height = r.height;
- p = new int; // 为新对象重新动态分配空间
- *p = *(r.p);
- }
- ~Rect() // 析构函数,释放动态分配的空间
- {
- if(p != NULL)
- {
- delete p;
- }
- }
- private:
- int width;
- int height;
- int *p; // 一指针成员
- };
此时,在完成对象的复制后,内存的一个大致情况如下:
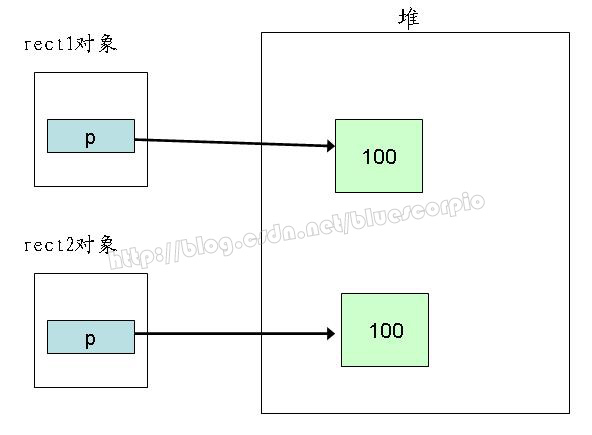
此时rect1的p和rect2的p各自指向一段内存空间,但它们指向的空间具有相同的内容,这就是所谓的“深拷贝”。
此外,在与“对象的复制”很类似的“对象的赋值”的情况下,也会出现同样的问题。在“对象的赋值”一文中再来讨论此问题。
通过对对象复制的分析,我们发现对象的复制大多在进行“值传递”时发生,这里有一个小技巧可以防止按值传递——声明一个私有拷贝构造函数。甚至不必去定义这个拷贝构造函数,这样因为拷贝构造函数是私有的,如果用户试图按值传递或函数返回该类对象,将得到一个编译错误,从而可以避免按值传递或返回对象。
c++默认的拷贝构造函数是浅拷贝
浅拷贝就是对象的数据成员之间的简单赋值,如你设计了一个没有类而没有提供它的复制构造函数,当用该类的一个对象去给令一个对象赋值时所执行的过程就是浅拷贝,如:
class A { public: A(int _data) : data(_data){} A(){}
private: int data; };
int main() { A a(5), b = a; // 仅仅是数据成员之间的赋值 }
这一句b = a;就是浅拷贝,执行完这句后b.data = 5;
如果对象中没有其他的资源(如:堆,文件,系统资源等),则深拷贝和浅拷贝没有什么区别,但当对象中有这些资源时,例子:
class A { public: A(int _size) : size(_size){data = new int[size];} // 假如其中有一段动态分配的内存 A(){}; ~A(){delete [] data;} // 析构时释放资源
private: int* data; int size; }
int main() { A a(5), b = a; // 注意这一句 }
这里的b = a会造成未定义行为,因为类A中的复制构造函数是编译器生成的,所以b = a执行的是一个浅拷贝过程。我说过浅拷贝是对象数据之间的简单赋值,比如:
b.size = a.size; b.data = a.data; // Oops!
这里b的指针data和a的指针指向了堆上的同一块内存,a和b析构时,b先把其data指向的动态分配的内存释放了一次,而后a析构时又将这块已经被释放过的内存再释放一次。
对同一块动态内存执行2次以上释放的结果是未定义的,所以这将导致内存泄露或程序崩溃。
所以这里就需要深拷贝来解决这个问题,深拷贝指的就是当拷贝对象中有对其他资源(如堆、文件、系统等)的引用时(引用可以是指针或引用)时,对象的另开辟一块新的资源,而不再对拷贝对象中有对其他资源的引用的指针或引用进行单纯的赋值。如:
class A { public: A(int _size) : size(_size){data = new int[size];} // 假如其中有一段动态分配的内存 A(){}; A(const A& _A) : size(_A.size){data = new int[size];} // 深拷贝 ~A(){delete [] data;} // 析构时释放资源
private: int* data; int size; }
int main() { A a(5), b = a; // 这次就没问题了 }
总结:
深拷贝和浅拷贝的区别是在对象状态中包含其它对象的引用的时候,当拷贝一个对象时,如果需要拷贝这个对象引用的对象,则是深拷贝,否则是浅拷贝。
看看effective c++ 中的解释吧!
条款11: 为需要动态分配内存的类声明一个拷贝构造函数和一个赋值操作符
看下面一个表示string对象的类:
// 一个很简单的string类
class string {
public:
string(const char *value);
~string();
... // 没有拷贝构造函数和operator=
private:
char *data;
};
string::string(const char *value)
{
if (value) {
data = new char[strlen(value) + 1];
strcpy(data, value);
}
else {
data = new char[1];
*data = '\0';
}
}
inline string::~string() { delete [] data; }
请注意这个类里没有声明赋值操作符和拷贝构造函数。这会带来一些不良后果。
如果这样定义两个对象:
string a("hello");
string b("world");
其结果就会如下所示:
a: data——> "hello\0"
b: data——> "world\0"
对象a的内部是一个指向包含字符串"hello"的内存的指针,对象b的内部是一个指向包含字符串"world"的内存的指针。如果进行下面的赋值:
b = a;
因为没有自定义的operator=可以调用,c++会生成并调用一个缺省的operator=操作符(见条款45)。这个缺省的赋值操作符会执行从a的成员到b的成员的逐个成员的赋值操作,对指针(a.data和b.data) 来说就是逐位拷贝。赋值的结果如下所示:
a: data --------> "hello\0"
/
b: data --/ "world\0"
这种情况下至少有两个问题。第一,b曾指向的内存永远不会被删除,因而会永远丢失。这是产生内存泄漏的典型例子。第二,现在a和b包含的指针指向同一个字符串,那么只要其中一个离开了它的生存空间,其析构函数就会删除掉另一个指针还指向的那块内存。
string a("hello"); // 定义并构造 a
{ // 开一个新的生存空间
string b("world"); // 定义并构造 b
...
b = a; // 执行 operator=,
// 丢失b的内存
} // 离开生存空间, 调用
// b的析构函数
string c = a; // c.data 的值不能确定!
// a.data 已被删除
例子中最后一个语句调用了拷贝构造函数,因为它也没有在类中定义,c++以与处理赋值操作符一样的方式生成一个拷贝构造函数并执行相同的动作:对对象里的指针进行逐位拷贝。这会导致同样的问题,但不用担心内存泄漏,因为被初始化的对象还不能指向任何的内存。比如上面代码中的情形,当c.data用a.data的值来初始化时没有内存泄漏,因为c.data没指向任何地方。不过,假如c被a初始化后,c.data和a.data指向同一个地方,那这个地方会被删除两次:一次在c被摧毁时,另一次在a被摧毁时。
拷贝构造函数的情况和赋值操作符还有点不同。在传值调用的时候,它会产生问题。当然正如条款22所说明的,一般很少对对象进行传值调用,但还是看看下面的例子:
void donothing(string localstring) {}
string s = "the truth is out there";
donothing(s);
一切好象都很正常。但因为被传递的localstring是一个值,它必须从s通过(缺省)拷贝构造函数进行初始化。于是localstring拥有了一个s内的指针的拷贝。当donothing结束运行时,localstring离开了其生存空间,调用析构函数。其结果也将是:s包含一个指向localstring早已删除的内存的指针。
顺便指出,用delete去删除一个已经被删除的指针,其结果是不可预测的。所以即使s永远也没被使用,当它离开其生存空间时也会带来问题。
解决这类指针混乱问题的方案在于,只要类里有指针时,就要写自己版本的拷贝构造函数和赋值操作符函数。在这些函数里,你可以拷贝那些被指向的数据结构,从而使每个对象都有自己的拷贝;或者你可以采用某种引用计数机制,去跟踪当前有多少个对象指向某个数据结构。引用计数的方法更复杂,而且它要求构造函数和析构函数内部做更多的工作,但在某些(虽然不是所有)程序里,它会大量节省内存并切实提高速度。
对于有些类,当实现拷贝构造函数和赋值操作符非常麻烦的时候,特别是可以确信程序中不会做拷贝和赋值操作的时候,去实现它们就会相对来说有点得不偿失。前面提到的那个遗漏了拷贝构造函数和赋值操作符的例子固然是一个糟糕的设计,那当现实中去实现它们又不切实际的情况下,该怎么办呢?很简单,照本条款的建议去做:可以只声明这些函数(声明为private成员)而不去定义(实现)它们。这就防止了会有人去调用它们,也防止了编译器去生成它们。
关于本条款中所用到的那个string类,还要注意一件事。构造函数体内,在两个调用new的地方都小心地用了[],尽管有一个地方实际只需要单个对象。在配套使用new和delete时一定要采用相同的形式,所以这里也这么做了。一定要经常注意,当且仅当相应的new用了[]的时候,delete才要用[]。
- 浅拷贝和深拷贝
- 浅拷贝和深拷贝
- 浅拷贝和深拷贝
- 深拷贝和浅拷贝
- 深拷贝和浅拷贝
- 深拷贝和浅拷贝
- 浅拷贝和深拷贝
- 浅拷贝和深拷贝
- 深拷贝和浅拷贝
- 深拷贝和浅拷贝
- 浅拷贝和深拷贝
- 浅拷贝和深拷贝
- 浅拷贝和深拷贝
- 深拷贝 和 浅拷贝
- 浅拷贝和深拷贝
- 浅拷贝和深拷贝
- 深拷贝和浅拷贝
- 深拷贝和浅拷贝
- Cannot Write to RAM for Flash Algorithms ! 的解决方法
- Java 反射机制
- c代码调用java代码
- hadoop的trash配置及使用
- hdoj1009解题报告
- 浅拷贝和深拷贝
- nyoj-14-会场安排
- 中日开战
- nyoj-47-过河问题
- 第2章 Android应用的界面编程
- ZOJ 3300 Mahjong DFS暴力解决。。
- poj 2479 Maximum sum(dp&最大子段和)
- How to Crack Wi-Fi Passwords—for Beginners!
- dojo实现省份地市级联---省份数据源


