"Big Data"- Reporting Over Hadoop using Hive-Intellicus 5.2
来源:互联网 发布:京都小众景点.知乎 编辑:程序博客网 时间:2024/06/07 02:27
https://www.intellicus.com/product/documents/release_notes/5.2/Hadoop.htm
"Big Data"- Reporting Over Hadoop using Hive
Intellicus 5.2 forays into the "Big Data" world by providing Reporting over Hadoop, using Hive as the JDBC Interface. This enables you to leverage your Hadoop System to get meaningful Business Insights into the huge datasets in the underlying HDFS.
Intellicus provides a much richer experience to the user, thru Dashboards, Charts, tabular reports etc., for doing analysis on the data. Intellicus Ad-hoc reporting also adds another layer of ease and power, in terms of filtering, grouping and summaries over the data present on a Hadoop system.
The Intellicus Solution:
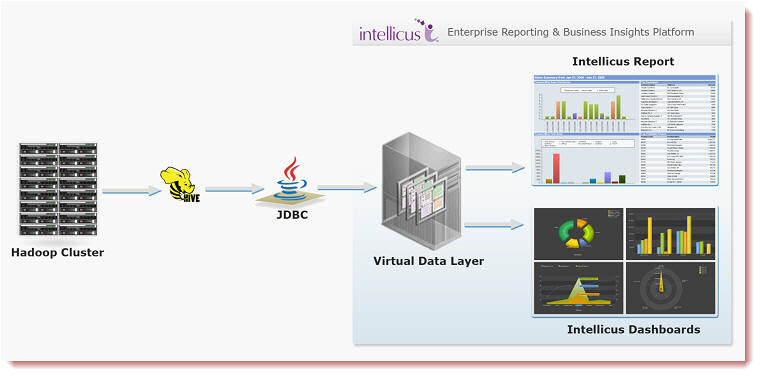
Note : The Hive JDBC driver has been enhanced to add some of the missing implementations and thus allows Intellicus to seamlessly communicate with a Hive Server as it does with any other regular RDBMS data source.
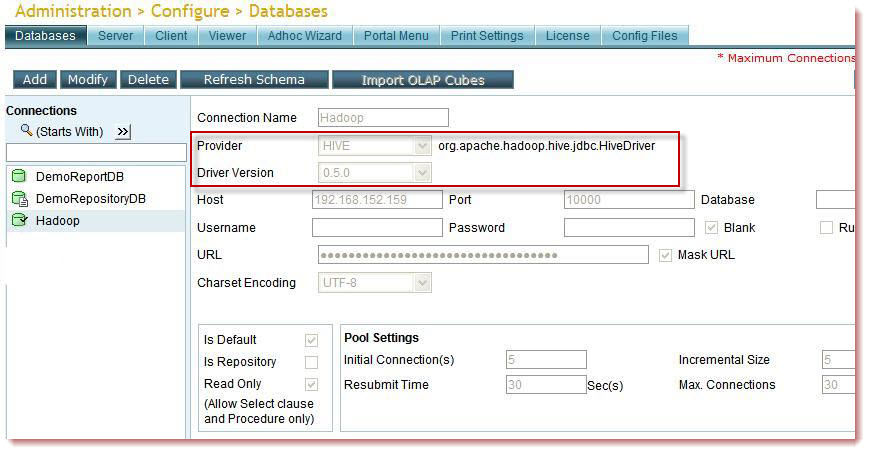
Connection
The connection to a Hive server can be made easily thru the existing interface in Intellicus, as shown
Creating Report Objects using Hive QL
The Report Objects (viz. Query objects and Parameter Objects) can be created using the existing interface of SQL Editor. You can also manually write Hive queries, as you write for other RDBMS.
The underlying data is available as Tables and query can be generated by drag-and-drop.
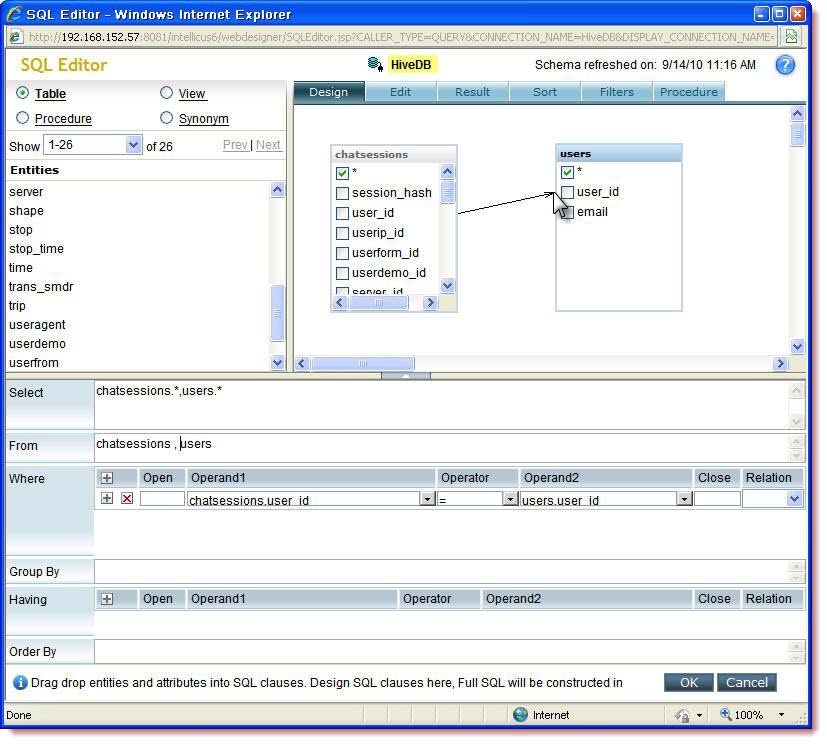
Note : The SQL generated by Intellicus SQL designer(Drag and Drop) for a "join" condition on Hive tables needs to be modified before being used. The generated SQL does not conform to the Hive QL syntax.
The Join (in the image above) generates the SQL as :

This query needs to be modified as:
Note "join" in place of "," and "on" in place of "where"

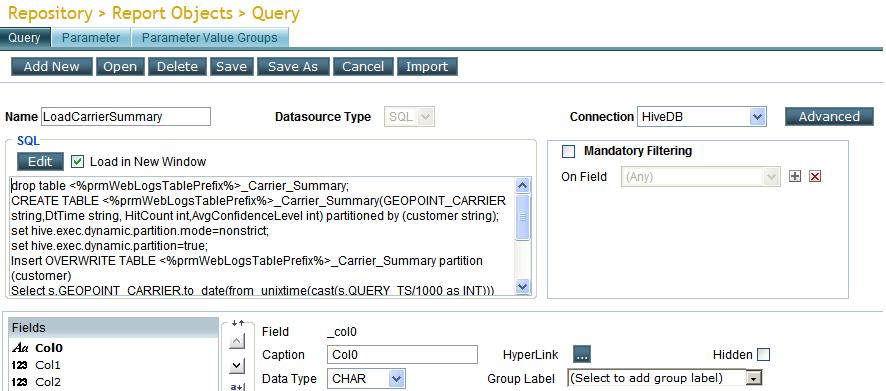
Support for execution of multiple queries on Hive
Building on the facility to analyze "Big Data" in 5.2, Intellicus 5.2 SP1 now provides support for execution of multiple queries through Query object on Hive. This facilitates execution of Map Reduce (MR) jobs in form of Hive SQLs. These jobs can be used to populate summary data in different tables. You can then do business analysis by creating reports on these populated summary tables.
Below image shows Hive SQLs in the SQL -Editor.
- "Big Data"- Reporting Over Hadoop using Hive-Intellicus 5.2
- Hive + Intellicus
- Big Data 及 Hadoop
- Big Data Analytics Beyond Hadoop
- Big Data--1, 初识hadoop
- Storing Big Data With Hive: RCFile
- OBIEE 11.1.1.7, Cloudera Hadoop & Hive/Impala Part 2 : Load Data into Hive Tables, Analyze using Hiv
- Big Data 2-- 单机配置hadoop
- Using In-Memory Computing to Simplify Big Data Analytics (zz)
- Easy, Real-Time Big Data Analysis Using Storm
- Hadoop HDFS over HTTP 2.4.1 - Using HTTP Tools
- Hadoop HDFS over HTTP 2.4.1 - Using HTTP Tools
- BIG DATA
- Big Data
- Big Data
- Big Data
- Big Data
- Big data
- poj1844
- rhel6.5 报unrecognized service错误
- 大数据起点
- android SQLite
- Android 入门 - 系统启动简介
- "Big Data"- Reporting Over Hadoop using Hive-Intellicus 5.2
- uva 10591 Happy Number(判重)
- 深入理解SELinux SEAndroid(最后部分)
- C# Panel实现多窗口切换
- 科大讯飞携手阿里云共筑移动互联生态圈
- RHEL6通过安装光盘制作本地yum源的方法
- I2C总线信号时序总结
- 在VS2010中应用SIFT(C)源码——from [FreedomShe]
- svn分支和合并实战(图解)


