Office文件格式突变,促使Java和Office更完美集成
来源:互联网 发布:电脑看摄像头软件 编辑:程序博客网 时间:2024/04/28 15:19
Office是大家非常熟悉的办公软件。它的强大的文字和表格的处理能力几乎无人能敌。而其中的Excel除了被应用在传统的表格处理中,也常被广大程序员“抓”来充当报表系统的前端。如我们使用的Java Web程序,在后台生成一个带报表数据的Excel文件,然后将这个文件送到前台浏览器(必须是IE),这样这个Excel文件就可以嵌入到IE中。
这样处理报表既可以利用Excel强大的表格处理功能,又可以使程序员省了很多的麻烦。但这么做有一个限制。就是服务器的Java生成Excel报表时,一般不会使用COM来调用Excel组件,而是按着Excel文件的二进制格式直接生成Excel文件。但由于Office是商业软件,微软并没有将Office的文件格式完全公开(就算公开,也不是最新版本的),这样就给生成Excel文件带来了一定的困难。虽然一些比较新的Office文档可以保存成XML格式,但这种文件格式只是一种简陋的替代,再说前端的IE并不认XML格式的Excel文档。也许是微软意识到了这个问题,在新推出的Office2007中彻底解决了这个问题。
在以前老版本Office中,由于法律或技术原因,脱离Office来处理Office文档将会遇到非常多的问题。也许是开源给微软带来的压力,或许是其他的原因,微软对Office2007的格式做了和以前完全不同的处理。以前的Office文档是100%的二进制格式。第三方的工具操作起来非常不方便,而Office2007从整体上都是基于XML格式的,这里并不是说Office2007文档可以保存成XML格式。而是Office2007默认的文档格式就是XML的(Word的docx、Excel的xlsx等)。也许有人会感到奇怪,用文本编辑器打开docx后,显示的仍然是二进制格式,并不是什么XML。其实docx并不是普通的XML格式,当然,也不只是一个XML文件,docx本质上是一个zip文件,里面有一系列的xml、目录和其他的文件。如果我们将docx改成zip。就可以用winzip等软件将其解开(从这一点我们可以看出,docx中的x就是指XML)。如图1是一个word2007文档解开后的目录结构。
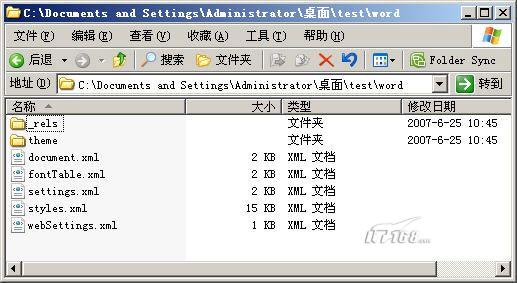
图1 docx文档解开后的目录结构
目录中的XML都是基于OpenXML格式的,这个规范微软已经提供提交给了ECMA,因此,这已经成为公共的标准,我们可以自由地使用它们。由于Office2007文档全部使用了压缩的xml格式,因此,只有支持读取zip格式和xml格式的语言都可以操作Office2007的文档,当然,Java也不例外。而使用Java和Office联合操作报表将更加容易。在本文中将演示如何使用Java来操作Office2007的文档,这里以word2007为例。
下面是一个简单的Word文档,如图2如示:
图2 一个简单的word文档
我们将这个文档保存为test.docx。注意,不要保存成向后兼容的word文档格式,也不要保存成Office2003或更好的Office的WordML格式。这个文档将是一个压缩的zip格式,如果将test.docx改成test.zip,解开后的目录结构如图1如示:
从上面解开的文件结构可以非常清楚地了解test.docx的保存结构。在Java中我们可以使用java.util.zip包来解开test.docx。从这个目录结构我们可以很容易地猜出文档的主要内容保存在document.xml中。而其他的xml文件将保存不同的信息。如字体信息将保存在fontTable.xml中,而Office主题将保存在theme.xml和theme1.xml中。
下面我们开使使用Java对这个文件进行操作。首先我们使用JUnit4来确定test.docx是否存在,以及是否可以对其进行读写,代码如下:
下面的代码将简单地验证java.util.zip.ZipFile类是否可以打开test.docx。
@Test public void verifyFile()
...{
assertTrue(new File("test.docx").exists());
}

经过测试,ZipFile完全可以操作test.docx。看来很多人都迫不急待了,下面就让我们来从test.docx中来读取数据吧。首先应该打开document.xml文件。代码如下:
...{
}

但是运行上面的代码将抛出一个异常,好象说明document.xml并不存在,事实上并不是如此。而是ZipFile API需要一个完整的文件或目录名,因此,需要将上面的路径变成word/document.xml。
下一步我们将通过ZipFile得到一个ZipEntry对象,并通过这个对象来看看xml中有什么,代码如下:
- Office文件格式突变,促使Java和Office更完美集成
- Office文件格式
- Win7自家OFFICE完美抠图 比ps更简单
- office 文件格式 索引
- Office檔案格式(Office文件格式)
- Office文件格式兼容包FileFormatConverters(office 2010)
- 如何完美卸载office
- 完美卸载office
- 完美卸载office
- Office集成之“艺术字”
- Microsoft Office Word、Excel 和 PowerPoint 文件格式兼容包
- office
- office
- office
- Office
- office
- office
- office
- 第一篇文章阿
- 是陷阱还是机遇,《赢在中国》背后只有一双手么?
- Java灵活的控制Word
- “快乐宝宝”风波始末 (一)
- June 2007
- Office文件格式突变,促使Java和Office更完美集成
- 使用JS/VBS来测试你的COM组件
- 修改了Prototype框架
- [转]我如烟的世界里曾飘落幻美的花
- 2007年值得去思考的N大软件技术
- Servlet 3.0
- 专家教您如何在C语言中巧用正则表达式
- Software Development in Unix Environment
- linux下用lex/yacc实现的一个小汇编器,for 体系实习2,实习中唯一可以拿的出来的东西


