查找算法小结:顺序查找、 二分查找、斐波那契查找 、插值查找
来源:互联网 发布:http协议传输数据 编辑:程序博客网 时间:2024/06/06 22:09
1.顺序查找:
主要过程: 从表中最后一个记录开始,依次向前逐个比较表中记录与给定值 ,若某一个记录与给定值相等时,则查找成功。反之,若直至第一个元素,其记录与给定值不等,则查找失败。
算法描述 :
int search_seq(int *a,int key,int n)
{ int i;
for(i=n-1;a[i]!=key;--i);
if(i>=0)
return i; // 查找成功 返回元素在数组中的位置
else
return -1; // 返回i =-1 ;则查找失败
}
时间复杂度: O((n+1)/2)
2. 二分查找:
应用对象:有序表
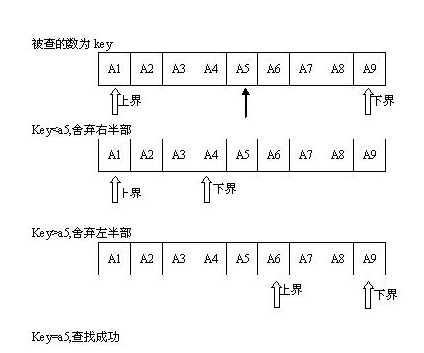
主要过程: 首先从表的中间位置元素 a[mid] 开始,与给定值key 进行比较,mid=(low+high)/2 ,(初始情况low=0,high=n-1),若相等,则查找成功。若key <a[mid],则需要重新修改查找区间为 [low,mid-1], 修改high=mid-1 ,mid=(low+high)/2 ,重新比较a[mid} 与key 值。 若若key >a[mid],则需要重新修改查找区间为 [mid+1,htgh], 修改low=mid+1,mid=(low+high)/2 ,重新比较a[mid} 与key 值. 如此往复比较 。 又称折半查找法 。
简言之: 对于给定值key,从序列的中间位置开始比较,如果当前位置值等于key,则查找成功;若x小于当前位置值,则在数列的前半段中查找;若key大于当前位置值则在数列的后半段中继续查找,直到找到为止。
算法描述 :
// 二分查找 key
int binary_search(int *a,int n,int key)
{
int low=0;
int high=n-1;
int mid; // 设置初始查找 上界 下界
while(low<=high)
{
mid=(low+high)/2; // 取中间位置
if(a[mid]>key)
high=mid-1; // 在区间[low,mid-1]内查找
else if(a[mid]<key)
low=mid+1; // 在区间[mid+1,high]内查找
else
return mid; //若相等,则查找成功 返回元素位置
}
return -1; // 查找失败
}
二分法的关键思想是 假设该数组的长度是N那么二分后是N/2,再二分后是N/4……直到二分到1结束(当然这是属于最坏的情况了,即每次找到的那个中点数都不是我们要找的),那么二分的次数就是基本语句执行的次数,于是我们可以设次数为x,N/2^x=1;则x=logn,底数是2,时间复杂度=O(Log2(N))
注:虽然二分法查找的效率高,但是要将表按关键字排序。而排序本身是一种很费时的运算,所以二分法比较适用于顺序存储结构。为保持表的有序性,在顺序结构中插入和删除都必须移动大量的结点。因此,二分查找特别适用于那种一经建立就很少改动而又经常需要查找的线性表。
3.斐波那契查找
应用对象:有序表
首先要明确:如果一个有序表的元素个数为n,并且n正好是(某个斐波那契数 - 1),即n=F[k]-1时,才能用斐波那契查找法。 如果有序表的元素个n不等于(某个斐波那契数 - 1),即n≠F[k]-1,这时必须要将有序表的元素扩展到大于n的那个斐波那契数 - 1才行,这段代码:
for (int i = n; i < F[k] - 1; i++)
{
a[i] = a[high];
}
便是这个作用
对于二分查找,分割是从mid= (low+high)/2开始;而对于斐波那契查找,分割是从mid = low + F[k-1] - 1开始的; 数组a现在的元素个数为F[k]-1个,即数组长为F[k]-1,mid把数组分成了左右两部分, 左边的长度为:F[k-1] - 1, 那么右边的长度就为(数组长-左边的长度-1), 即:(F[k]-1) - (F[k-1] - 1) = F[k] - F[k-1] - 1 = F[k-2] - 1。
斐波那契查找的核心是:
1)当key=a[mid]时,查找成功;
2)当key<a[mid]时,新的查找范围是第low个到第mid-1个,此时范围个数为F[k-1] - 1个,即数组左边的长度,所以要在[low, F[k - 1] - 1]范围内查找;
3)当key>a[mid]时,新的查找范围是第mid+1个到第high个,此时范围个数为F[k-2] - 1个,即数组右边的长度,所以要在[F[k - 2] - 1,F[k-1]-1]范围内查找
算法描述 :
// fibonacci 查找
// 输入查找数组 a 数组个数 n 要查找的关键字 key
// 若查找成功 返回 该值所在位置 否则 返回-1
int fibonacci_Search(int *a,int n,int key)
{
int low=0;
int high=n-1;
int k=0;
int mid=0;
int i;
int f[MAXSIZE];
creatFibonacci(f); // 生成 fibonacci 数列 0 1 1 2 3 5 8.。。。
while(n>f[k]-1) //找到 n 在f数列中的位置
++k;
for( i=n;i<f[k]-1;i++) // n不等于 f[k]-1 拓展原数组 使得新数组的个数 =f[k-1]-1 个
a[i]=a[high] ;
while(low<high)
{
mid=low+f[k-1]-1; // fibonacci 分割点
if(key<a[mid])
{
high=mid-1;
k=k-1; //修改 k值 [0, mid-1]内 共计 f(k-1)-1 个 继续查找
}
else if(key>a[mid])
{
low=mid+1;
k=k-2; //修改 k值 [mid+1, f(k)-1]内 共计 f(k-2)-1 个 继续查找
}
else
{
if(mid<=high)
return mid; // 找到 返回元素位置
else
{
return n-1;
}
}
}
return -1;
}
与二分查找相比,斐波那契查找算法的明显优点在于它只涉及加法和减法运算,而不用除法。因为除法比加减法要占去更多的机时,因此,斐波那契查找的平均性能要比折半查找好。
4.插值查找
对象: 关键字分布比较均匀的表
插值查找(Interpolation Search)是根据要查找的关键字key与查找表中最大最小记录的关键字比较后的查找方法,其核心就在于插值的计算公式 。
。
由二分查找改进而来

算法描述:
// 插值查找 key
int interpolation_Search(int *a,int n,int key)
{
int low=0;
int high=n-1;
int mid; // 设置初始查找 上界 下界
while(low<=high)
{
mid=low+(high-low)*(key-a[low])/(a[high]-a[low]); // 插值公式 ---区别于二分查找
if(a[mid]>key)
high=mid-1; // 在区间[low,mid-1]内查找
else if(a[mid]<key)
low=mid+1; // 在区间[mid+1,high]内查找
else
return mid; //若相等,则查找成功 返回元素位置
}
return -1; // 查找失败
}
插值查找时间复杂度仍为O(logn)。
对于表长较大,而关键字分布又比较均匀的查找表来说,插值查找算法的平均性能比折半查找要好得多。
反之,数组中如果分布极端不均匀,用插值查找则未必合适。
- 查找算法小结:顺序查找、 二分查找、斐波那契查找 、插值查找
- 顺序查找:二分查找,斐波那契查找,插值查找
- 二分查找,插值查找,斐波那契查找
- 静态查找(顺序查找,折半查找,插值查找,斐波那契查找)
- 常见的查找算法(顺序、二分、插值、斐波那契查找,哈希查找)
- 有序表查找(二分查找,插值查找,斐波那契查找)
- 【查找】二分查找、插值查找、斐波那契查找
- 查找(顺序查找、插值查找和斐波那契查找)
- 简单查找算法之折半查找、插值查找、斐波那契查找
- 查找(顺序查找、二分查找、插值查找)
- 有序向量:二分查找&斐波那契查找&插值查找
- 查找(顺序、二分、斐波那契和插值)算法的实现和测试
- 静态表查找(顺序查找,二分查找,斐波那契查找)
- 静态表查找(顺序查找,二分查找,斐波那契查找)
- 数据结构之查找——折半查找、插值查找、斐波那契查找
- 算法-01-二分查找/插值查找
- 有序查找算法(二分查找、差值查找、斐波那契查找)
- 数据结构 插值查找 斐波那契查找
- Binary Tree Inorder Traversal
- UIView
- java String
- MFC学习笔记(二)
- poj1276 多重背包
- 查找算法小结:顺序查找、 二分查找、斐波那契查找 、插值查找
- 进程间通信
- 装饰器的原理及其用法
- 3D Transformation 3D物体位移函数
- ios开发经典问题汇总
- 合并两个有序数组_向右循环移位
- 设计模式C++实现——抽象工厂模式
- IBM WebSphere Application Server Network Deployment 8.5.0.X 安装配置及补丁升级指南之Windows系统篇
- java使用DOM解析XML文件


