in和exists的区别与SQL执行效率分析
来源:互联网 发布:2.5平衡口耳机 知乎 编辑:程序博客网 时间:2024/06/07 19:33
SQL中in可以分为三类:
1、形如select * from t1 where f1 in ('a','b'),应该和以下两种比较效率
select * from t1 where f1='a' or f1='b'
或者 select * from t1 where f1 ='a' union all select * from t1 f1='b'
你可能指的不是这一类,这里不做讨论。
2、形如select * from t1 where f1 in (select f1 from t2 where t2.fx='x'),
其中子查询的where里的条件不受外层查询的影响,这类查询一般情况下,自动优化会转成exist语句,也就是效率和exist一样。
3、形如select * from t1 where f1 in (select f1 from t2 where t2.fx=t1.fx),
其中子查询的where里的条件受外层查询的影响,这类查询的效率要看相关条件涉及的字段的索引情况和数据量多少,一般认为效率不如exists。
除了第一类in语句都是可以转化成exists 语句的SQL,一般编程习惯应该是用exists而不用in,而很少去考虑in和exists的执行效率.
测试结果: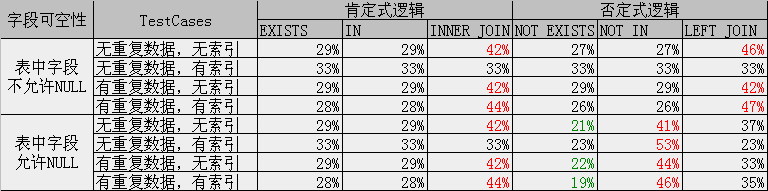
测试代码较长,附于本帖最后。
图表中百分数表示同一组3个查询的执行时间比例。红色表示3个语句中最慢,绿色表示3个语句中最快的,并列则没加颜色。
其中索引只测试了聚集索引,当表中字段较多且查询字段是非聚集索引时,选择执行计划的条件比较复杂,没有测试。并且当表中数量变化后,执行计划可能也有差异。图表反映了3种查询方式的解析机制的不同,基本结论是类似的,但具体情况还要视执行计划而定。
分析结论:
通常情况下,3种查询方式的执行时间:
EXISTS <= IN <= JOIN
NOT EXISTS <= NOT IN <= LEFT JOIN
只有当表中字段允许NULL时,NOT IN的方式最慢:
NOT EXISTS <= LEFT JOIN <= NOT IN
综上:
IN的好处是逻辑直观简单(通常是独立子查询);缺点是只能判断单字段,并且当NOT IN时效率较低,而且NULL会导致不想要的结果。
EXISTS的好处是效率高,可以判断单字段和组合字段,并不受NULL的影响;缺点是逻辑稍微复杂(通常是相关子查询)。
JOIN用在这种场合,往往是吃力不讨好。JOIN的用途是联接两个表,而不是判断一个表的记录是否在另一个表。
编程建议:
(以下三条建议中EXISTS和IN同时代指肯定式逻辑和加NOT后的否定式逻辑)
如果查询条件是单字段主键(有索引且不允许NULL),则EXISTS和IN的性能基本一样,IN的查询通常写法简单、逻辑直观。
如果查询条件涉及多个字段,则最好选择EXISTS,千万不要用字段拼接再IN的方式(索引会失效)。
如果条件不确定,选用EXISTS是最保险的办法,性能最好,不受三值逻辑影响(EXISTS只会返回True/False不会返回Unknown),但代码逻辑稍稍复杂,思路要理清楚,而且相关字段最好采用“表(别)名.字段名”的形式。
源地址: http://www.cnblogs.com/diction/archive/2008/01/18/1043844.html
http://bbs.csdn.net/topics/350022037
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的区别与SQL执行效率分析
- in和exists的SQL执行效率分析
- [Oracle] 分析函数(4)- Order By字句
- R语言编程艺术——考试成绩的回归分析[一]
- CDialog窗口类的Class Style中没有CS_VREDRAW和CS_HREDRAW导致自绘有问题
- 你妹都看得懂的手机网游制作教程(第21篇)游戏黑屏了,别急我们来调试代码
- C#,C++,Java三者的一些区别
- in和exists的区别与SQL执行效率分析
- 大数四则运算的C++实现
- 电视剧看合适的即可发生的方式根深蒂固
- ZBar 支持i386 armv6 armv7 armv7s x86_64 arm64
- TCP的那些事儿
- 数据结构中的树
- VS2012 创建项目未找到与约束匹配的导出
- AES For Delphi And Java, AES/ECB/PKCS5Padding(一)
- C#开发、部署Windows Services服务


