Co-regularized PLSA for Multi-view Clustering
来源:互联网 发布:软件测试研究 编辑:程序博客网 时间:2024/04/30 12:27
这篇文章是比较新的一篇Muti-view Clustering的文章,它提出了一个CO-PLSA的模型,将不同view下的PLSA模型整合起来。这篇文章的主要基本思想是在某一个view下,如果两篇文章在主题空间中相似,那么他们在其他view下的主题空间也将类似。
我们都知道通常的PLSA生成过程如下:
根据概率
p(di) 选择一篇文档di 。根据概率
p(zk|di) 选择一个隐藏主题zk 。根据概率
p(wj|zk) 生成一个词wj 。
模型的联合概率分布:
写出似然函数
而COPlSA的目标函数就是
其中
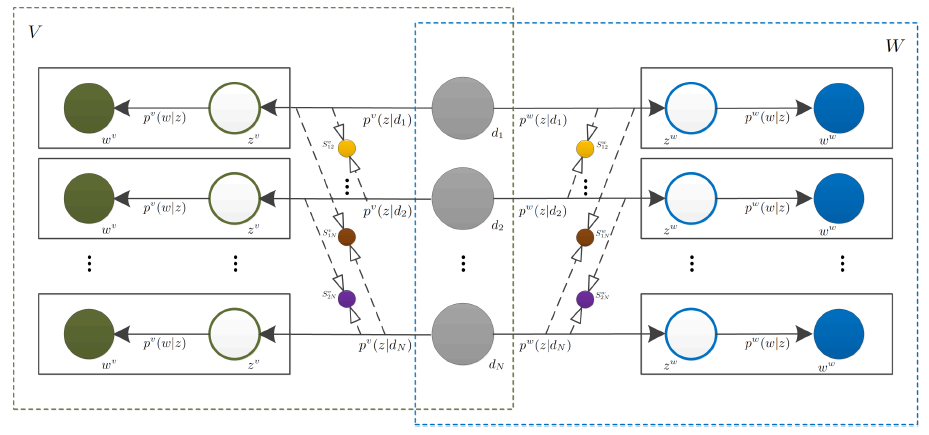
这个pairwise co-regularization R是将二个独立的view连接起来的桥梁,它被定义为
其中
在求解的时候,这个目标函数最大化问题可以用以下相互迭代的方法来解决
固定
Ψw=Ψ^w ,解决问题O(Ψv,Ψ^w) 。固定
Ψv=Ψ^v ,解决问题O(Ψ^v,Ψw) 。
解决具体问题的时候使用的是EM算法,就不详述了。
原来看这篇文章是想做内容和链接2个view的社区发现的,但是发现它的基本假设不一定相符,在内容和链接的2个view下数据是否有相似性还有待讨论。
参考文献:
1 Jiang,Y., Liu, J., Li, Z., Li, P., and Lu, H.: ‘Co-regularized PLSA for Multi-viewClustering’: ‘Computer Vision–ACCV 2012’ (Springer, 2013), pp. 202-213
0 0
- Co-regularized PLSA for Multi-view Clustering
- 阅读笔记之:Co-regularized multi-view spectral clustering-NIPS2011
- 论文解读:Multi-view Clustering via Joint Nonnegative Matrix Factorization
- Linguistically Regularized LSTMs for Sentiment Classification
- Funnel-structured cascade for multi-view face detection with alignmentawareness
- Multi-view Convolutional Neural Networks for 3D Shape Recognition
- Multi-View 3D Object Detection Network for Autonomous Driving
- PLSA
- Example for Agglomerative Clustering
- Affinity propagation for clustering
- test for co
- R for more powerful clustering
- Multi view adapter
- Projective Feature Learning for 3D Shapes with Multi-View Depth Images
- 论文阅读:Volumetric and Multi-View CNNs for Object Classification on 3D Data
- 论文阅读:Multi-view Convolutional Neural Networks for 3D Shape Recognition
- [论文解读]Multi-View 3D Object Detection Network for Autonomous Driving
- A Multi-View Deep Learning Approach for Cross Domain User Modeling in Recommendation Systems
- nagios 插件编写:检查磁盘状况
- hdu 1286 找新朋友(欧拉函数)
- 素数筛选法。
- 数码相机存储卡数据怎么恢复,如何解决数码相机内存卡数据恢复
- mysql 如何将行数插入到数据库
- Co-regularized PLSA for Multi-view Clustering
- Android NDK开发入门篇
- 解决Chrome代理proxy switchy无法使用方法
- STL容器 vector,list,deque 性能比较
- Selenium Python 致友自动登陆
- delphi中@ 什么意思
- java web进阶篇(九) Struts基础开发
- 多点触摸和手势检测
- Android的账号与同步机制


