hdu 3068 最长回文
来源:互联网 发布:erp仓库管理系统 php 编辑:程序博客网 时间:2024/06/05 12:45
manacher算法。。。,又学会了一个算法
代码如下:
#include<stdio.h>#include<string.h>#define M 110010char s[M],ss[M*2];//s代表原来的字符串,ss代表插入之后的字符串int p[M*2]; //表示以i为中心的(包含i这个字符)回文串半径长int min(int a,int b){ return a>b?b:a;}int main(){ int i,id,mx,max,m,n; while(scanf("%s",s)!=EOF) { ss[0]='$'; n=strlen(s); for(i=0;i<n;i++) { ss[2*i+1]='#'; ss[2*(i+1)]=s[i]; } ss[2*i+1]='#'; ss[2*(i+1)]='\0'; id=1; mx=0; max=0; m=strlen(ss); for(i=1;i<m;i++) { if(mx>i) p[i]=min(mx-i,p[2*id-i]); else p[i]=1; while(ss[i+p[i]]==ss[i-p[i]]) { p[i]++; } if(i+p[i]>mx) { mx=i+p[i]; id=i; } if(p[i]>max) max=p[i]; } printf("%d\n",max-1); } return 0;} manachar算法解释:简单的说id是上一个回文的中心,它的最大长度mx,有一个点i ,他的关于id的对称点j,
取mx-j,与p[j]的最小值
深度解析:
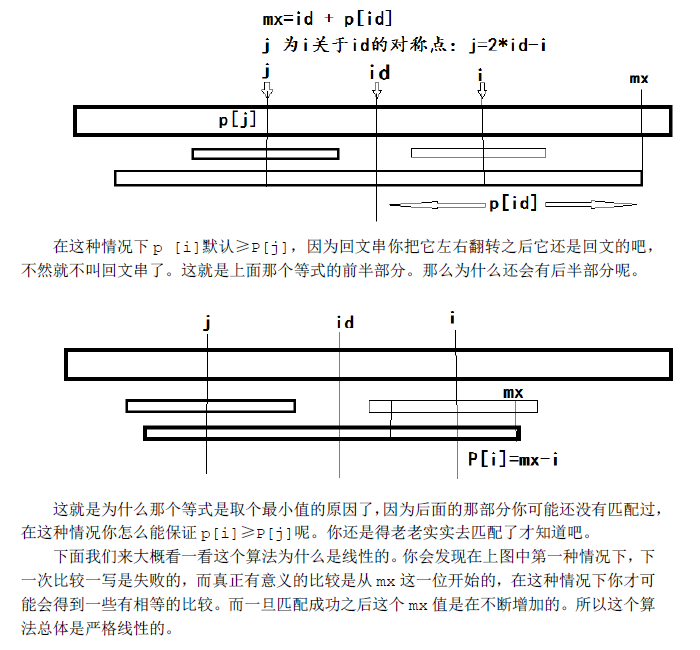
这个算法有一个很巧妙的地方,它把奇数的回文串和偶数的回文串统一起来考虑了。这一点一直是在做回文串问题中时比较烦的地方。这个算法还有一个很好的地方就是充分利用了字符匹配的特殊性,避免了大量不必要的重复匹配。
算法大致过程是这样。先在每两个相邻字符中间插入一个分隔符,当然这个分隔符要在原串中没有出现过。一般可以用‘#’分隔。这样就非常巧妙的将奇数长度回文串与偶数长度回文串统一起来考虑了(见下面的一个例子,回文串长度全为奇数了),然后用一个辅助数组P记录以每个字符为中心的最长回文串的信息。P[id]记录的是以字符str[id]为中心的最长回文串,当以str[id]为第一个字符,这个最长回文串向右延伸了P[id]个字符。
原串: w aa bwsw f d
新串: # w# a # a # b# w # s # w # f # d #
辅助数组P: 1 2 1 2 3 2 1 2 1 2 1 4 1 2 1 2 1 2 1
这里有一个很好的性质,P[id]-1就是该回文子串在原串中的长度(包括‘#’)。如果这里不是特别清楚,可以自己拿出纸来画一画,自己体会体会。当然这里可能每个人写法不尽相同,不过我想大致思路应该是一样的吧。
好,我们继续。现在的关键问题就在于怎么在O(n)时间复杂度内求出P数组了。只要把这个P数组求出来,最长回文子串就可以直接扫一遍得出来了。
由于这个算法是线性从前往后扫的。那么当我们准备求P[i]的时候,i以前的P[j]我们是已经得到了的。我们用mx记在i之前的回文串中,延伸至最右端的位置。同时用id这个变量记下取得这个最优mx时的id值。(注:为了防止字符比较的时候越界,我在这个加了‘#’的字符串之前还加了另一个特殊字符‘$’,故我的新串下标是从1开始的)
好,到这里,我们可以先贴一份代码了。
void pk()
{
int i;
int mx = 0;
int id;
for(i=1; i<n; i++)
{
if( mx > i )
p[i] = MIN( p[2*id-i], mx-i );
else
p[i] = 1;
for(; str[i+p[i]] == str[i-p[i]]; p[i]++)
;
if( p[i] + i > mx )
{
mx = p[i] + i;
id = i;
}
}
}
- HDU 3068 ( 最长回文 )
- HDU-3068 最长回文
- hdu 3068 最长回文
- Hdu 3068 最长回文
- HDU 3068 最长回文
- HDU-3068-最长回文
- hdu-最长回文-3068
- hdu 3068 最长回文
- 【HDU】3068 最长回文
- hdu 3068 最长回文
- HDU 3068 最长回文
- hdu 3068 最长回文
- hdu 3068 最长回文
- hdu-3068-最长回文
- HDU 3068 最长回文
- HDU 3068 最长回文
- HDU 3068 最长回文
- HDU - 3068 最长回文
- 数据库的最简单实现
- Text editor does not have a document provider
- WeChall Training: WWW-Robots
- Search Insert Position
- C++中格式化cout输出
- hdu 3068 最长回文
- 03.抽象工厂模式--AbstractFactory
- SVN升级到1.8后 Upgrade working copy
- cocos2d-x3.1.1 step by step 学习笔记2 cocos中的字符串
- 泛型类型的转换,协变和逆变
- Spring配置连接池
- mini2440 简单的dma工作原理实验
- 不能使用ctrl+space切换中英文输入法的问题
- DXP如何对一类元件进行处理 例如在PCB中对一批元件进行修改层 将top layer 改为bottom layer


