java 类库分析之HashMap
来源:互联网 发布:数据库测试包括什么 编辑:程序博客网 时间:2024/06/03 11:20
JAVA类库分析之HashMap
1. HashMap概述
1.1)重要参数
HashMap是什么,相信大家都很清楚,这里偷个懒,从网上摘了一段描述HashMap的文字:
HashMap是基于哈希表的 Map接口的实现。此实现提供所有可选的映射操作,并允许使用 null值和 null 键。(除了HashMap非同步和允许使用 null之外,HashMap类与 Hashtable大致相同)。此类不保证映射的顺序,特别是它不保证该顺序恒久不变。此实现假定哈希函数将元素适当地分布在各桶之间,可为基本操作(get和 put)提供稳定的性能。
HashMap 的实例有两个参数影响其性能:初始容量和加载因子。容量是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。加载因子是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子 (0.75)在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap类的操作中,包括 get 和 put操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash操作。
1.2)同步机制
注意,此实现不是同步的。如果多个线程同时访问一个哈希映射,而其中至少一个线程从结构上修改了该映射,则它必须保持外部同步。(结构上的修改是指添加或删除一个或多个映射关系的任何操作;仅改变与实例已经包含的键关联的值不是结构上的修改)。一般可以通过封装一个同步对象来完成同步,如synchronized(Object obj),或者通过使用 Collections.synchronizedMap()方法来创建一个包装过的HashMap,这样就能保证访问的同步了。
此外,对迭代器的访问类似于Vector,都是采用的fail-fast方式来操作。在迭代器创建后,除了迭代器自己的remove方法外,其他任何方式从结构上对HashMap进行修改,迭代器都会抛出ConcurrentModificationException异常。
2. 代码分析
2.1)HashMap数据结构
/*存储元素的数组,大小必须是2的指数次方,默认是16*/ transient Entry[ ] table; /** * HashMap中的存储的<K,V>映射的数目。 */ transient int size; /** * threshold=容量*加载因子。当实际数目大于threshold时,HashMap就需要扩容。 */ int threshold; /** * 哈希表的加载因子,默认为0.75 */ final float loadFactor; /*Entry类,结构如下,包括<K,V>对,哈希值以及一个next项。 此外,它还提供了key与value的set与get方法。*/ static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; final int hash; Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; } … } HashMap采用数组来存储数据,我们知道针对key哈希会出现重复值,HashMap通过链表法来解决冲突,即数组中的每个项都形成了一个链表,如图1所示。table为Entry类型的数组,每个数组项的链表通过Entry结构来连接。这个Entry结构与LinkedList中的Entry有所不同,它只是一个单向链表,所以只有一个next项指向下一个元素,此外,它包含的是<K,V>对,同时还有一个哈希值hash。
当我们往hashmap中put元素的时候,先根据key的hash值得到这个元素在数组中的位置(即下标),然后就可以把这个元素放到对应的位置中了。如果这个元素所在的位子上已经存放有其他元素了,那么在同一个位子上的元素将以链表的形式存放,新加入的放在链头,最先加入的放在链尾。从hashmap中get元素时,首先计算key的hashcode,找到数组中对应位置的某一元素,然后通过key的equals方法在对应位置的链表中找到需要的元素。如果每个数组项中都只有一个元素,则在O(1)的时间就可以得到需要的元素,从而不需要去遍历链表。
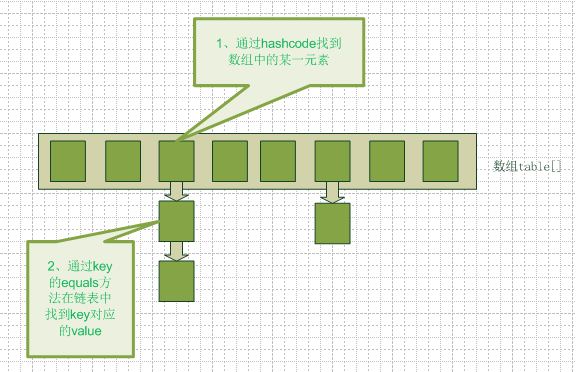
图1—哈希表的存取结构
2.2)HashMap初始化
/* *不指定参数,则默认加载因子loadFactor为0.75,默认大小为16, *threshold=*16*0.75=12 */ public HashMap() { this.loadFactor =DEFAULT_LOAD_FACTOR; threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR); table =new Entry[DEFAULT_INITIAL_CAPACITY]; init(); } public HashMap(int initialCapacity) { this(initialCapacity,DEFAULT_LOAD_FACTOR); } /** *指定参数的构造方法,如果初始容量不为2的指数次幂,则会找到一个最小的2的指数次幂的值,使得它大于等于初始容量。 **/ public HashMap(int initialCapacity,float loadFactor) { if (initialCapacity < 0) thrownew IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; //最大为1<<30. if (loadFactor <= 0 || Float.isNaN(loadFactor)) thrownew IllegalArgumentException("Illegal load factor: " + loadFactor); // Find a power of 2 >= initialCapacity int capacity = 1; while (capacity < initialCapacity) capacity <<= 1; this.loadFactor = loadFactor; threshold = (int)(capacity * loadFactor); table =new Entry[capacity]; init(); } 重点注意一下带两个参数的构造方法,其初始化时的初始大小不一定是你所指定的大小。比如new HashMap(12, 0.75),则HashMap初始容量会是16,因为必须保证HashMap的初始容量为2的指数幂。至于为什么要这么做,在最后再单独分析。
后面的init()方法是个钩子方法,所谓钩子方法,就是说你能在子类中加入自己的实现。HashMap默认init()方法为一个空的方法,里面什么都没有。
2.3)定位数据
如同前面介绍的HashMap的结构,那么如何定位要访问的数据呢?首先肯定是需要对key进行哈希的。当然这不仅仅是使用key.hashCode()这么简单,因为比如key是String类型的话,String类的hashCode()算法是s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1](n为字符串的长度),相当于是31进制。如String=”ab”,则hashCode()的值为97*31 ^(2-1)+ 98*31^(2-2)=3105。假设两个字符串都是有两个字符,那么如果满足 a1*31+b1 = a2*31 +b2这个等式,这两个字符串的hashcode()就一样,也就是(a1-a2)*31=b2-b1,如果设a1-a2=1,那么b2-b1=31就好。例如字符串”Aa”与”BB”的hashCode都是2112,所以由此看来碰撞的可能性还是很大的。
如上一段分析,简单的hashCode()难以满足要求,那么在HashMap中额外使用了一个哈希函数,它对key的hashCode()的值进行了再次哈希,该哈希函数代码如下所示:
static int hash(int h) { // This function ensures that hashCodes that differ only by // constant multiples at each bit position have a bounded // number of collisions (approximately 8 at default load factor). h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); } 这个哈希方法在本文后面会单独讨论它的巧妙之处。我们暂且继续往下分析。得到了key的哈希值后,我们需要定位该key在数组table的哪一项中,方法indexFor()就是用来定位数组项的。代码如下所示,方1法第一个参数为key的哈希值,第二个则是table数组的大小,代码的作用就是使用key的哈希值模除数组大小,如哈希值为97,table大小为16的话,则会定位到97&(16-1)=1。即table数组的第1项。
/** * Returns index for hash code h. */ static int indexFor(int h,int length) { return h & (length-1); } 当 length 总是 2 的倍数时,h & (length-1) 将是一个非常巧妙的设计:假设 h=5,length=16, 那么 h & length - 1 将得到 5;如果 h=6,length=16, 那么 h & length - 1 将得到 6 ……如果 h=15,length=16, 那么 h & length - 1 将得到 15;但是当 h=16 时 , length=16 时,那么 h & length - 1 将得到 0 了;当 h=17 时 , length=16 时,那么 h & length - 1 将得到 1 了……这样保证计算得到的索引值总是位于 table 数组的索引之内。 2.4)常用方法分析
V put(K key, V value):
方法说明:建立指定key和value之间的映射。如果已经存在key,则替换对应的value,并返回原来的value;如果原来没有建立映射,则建立映射,并返回null。当然返回null还有一种可能就是原来的value为null,因为HashMap允许key和value为null。
方法源代码
public V put(K key, V value) { /* *如果key==null,则调用专门的方法处理。 */ if (key ==null) return putForNullKey(value); int hash = hash(key.hashCode()); //计算key的哈希值。 int i = indexFor(hash,table.length); //定位数组项 for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))){ V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i);//加入新的项 return null; //原来不存在该项,所以返回null } /** * Adds a new entry with the specified key, value and hash code to * the specified bucket. It is the responsibility of this * method to resize the table if appropriate. * * Subclass overrides this to alter the behavior of put method. */ void addEntry(int hash, K key, V value,intbucketIndex) { Entry<K,V> e = table[bucketIndex]; //加入该项到链表头部 table[bucketIndex] =new Entry<K,V>(hash, key, value, e); if (size++ >= threshold) resize(2 * table.length); }
private V putForNullKey(V value) { for (Entry<K,V> e =table[0]; e !=null; e = e.next) { if (e.key ==null) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(0, null, value, 0); return null; } 1.1) 若key为null时,直接存储在table[0]中。1) 首先判断key是否为null,若为null,则调用专门的方法putForNullKey(value)处理并返回。
1.2.1)如果事先已经存在key为null的映射,则替换后返回old value。
1.2.2)如果不存在,则添加新的项到链表中,注意的是其hash为0,key为null,value为指定的值,数组项索引也为0。
2) 若key不为null,则
2.1)首先计算key的哈希值,然后根据哈希值和table数组的长度定位数组项。
2.2)对数组项的链表进行遍历,如果key的哈希值与链表中的某一项的哈希值相等且key本身引用值相等或者引用值所指向的对象相等,则替换相应项的value值为新的value,并返回老的value。如果没有找到相同的key,则加入该项到链表中。(这里说明一下为什么即判断key的哈希值(e.hash==hash)又判断key本身的值(k==e.key)或者指向对象的值(key.equals(k))。这是因为如果两个key的哈希值不同,但是他们还是可能哈希到同一个数组项中,从而构成链表。例如key1哈希值为65,key2哈希值为33,table大小为16,则它们最终都定位到数组table的第1项中。因此首先判断hash值是否相等,若hash值不相等,则肯定不是同一个key。若哈希值相等了,然后再依次判断是否key相等或者key所指向的对象相等。(因为两个key不同,它们的哈希值也可能相等,这就是碰撞了))。
2.3)addEntry方法直接将新的项加入到链表的头部,新项的next引用指向原来的链表项。此外判断是否需要扩容,如果此时存储的项数目size大于等于threshold,则扩大HashMap容量为原来的2倍。
2.4)resize方法用来扩容HashMap。默认是扩容至原来的2倍大小。
//扩充HashMap的容量。 void resize(int newCapacity) { Entry[] oldTable =table; int oldCapacity = oldTable.length; if (oldCapacity ==MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return; } Entry[] newTable =new Entry[newCapacity];//创建新的数组。 transfer(newTable);//传输数据到新的数组中 table = newTable; //更新table的引用 threshold = (int)(newCapacity *loadFactor);//更新threshold值 } /** * 将原来数组中元素传输到新数组中。注意: 1)原来数组中元素存储的位置与新数组会不同,因为新的数组容量已经改变。所以数组定位到的项会不同。但是key的哈希值不变,所以还是一样可以定位到新数组中,因为我们在传输数据的时候也是根据它的哈希值来存到新数组项中的。 2)因为哈希表扩容后,原来哈希表数组项的链表中的元素都需要重新哈希,而且不一定哈希到同一个数组项。链表项采用的是前端插入方式 */ void transfer(Entry[] newTable) { Entry[] src = table; int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { Entry<K,V> e = src[j]; if (e !=null) { src[j] = null; do { Entry<K,V> next = e.next; int i =indexFor(e.hash, newCapacity); e.next =newTable[i]; newTable[i] = e; e = next; } while (e !=null); } } } //V get(Object key):获取key所对应的value值。 public V get(Object key) { if (key ==null) return getForNullKey(); int hash =hash(key.hashCode()); for (Entry<K,V> e =table[indexFor(hash,table.length)]; e !=null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) return e.value; } returnnull; } 如果key为null,get方法与put方法对应,对null值也有特殊处理,即直接到table[0]中去找key为null对应的value。
如果key不为null,则定位key所在数组项,然后遍历链表,如果存在key,则返回对应的value值,否则返回null。
2.5)一些问题
2.5.1)为什么HashMap初始大小要是2的指数次幂?(转)
看下图,左边两组是数组长度为16(2的4次方),右边两组是数组长度为15。两组的hashcode均为8和9,但是很明显,当它们和1110“与”的时候,产生了相同的结果,也就是说它们会定位到数组中的同一个位置上去,这就产生了碰撞,8和9会被放到同一个链表上,那么查询的时候就需要遍历这个链表,得到8或者9,这样就降低了查询的效率。同时,我们也可以发现,当数组长度为15的时候,hashcode的值会与14(1110)进行“与”,那么最后一位永远是0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!
所以说,当数组长度为2的n次幂的时候,不同的key算得得index相同的几率较小,那么数据在数组上分布就比较均匀,也就是说碰撞的几率小,相对的,查询的时候就不用遍历某个位置上的链表,这样查询效率也就较高了。
说到这里,我们再回头看一下hashmap中默认的数组大小是多少,查看源代码可以得知是16,为什么是16,而不是15,也不是20呢,看到上面annegu的解释之后我们就清楚了吧,显然是因为16是2的整数次幂的原因,在小数据量的情况下16比15和20更能减少key之间的碰撞,而加快查询的效率。
所以,在存储大容量数据的时候,最好预先指定hashmap的size为2的整数次幂次方。就算不指定的话,也会以大于且最接近指定值大小的2次幂来初始化的。

2.5.2)哈希函数的巧妙之处在哪里?(转)
static int hash(int h) {
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
假设key.hashCode()的值为:0x7FFFFFFF,table.length为默认值16。上面算法执行如下:
得到i=15

其中h^(h>>>7)^(h>>>4)结果中的位运行标识是把h>>>7换成 h>>>8来看。
即最后h^(h>>>8)^(h>>>4)运算后hashCode值每位数值如下:
8=8
7=7^8
6=6^7^8
5=5^8^7^6
4=4^7^6^5^8
3=3^8^6^5^8^4^7
2=2^7^5^4^7^3^8^6
1=1^6^4^3^8^6^2^7^5
结果中的1、2、3三位出现重复位^运算
3=3^8^6^5^8^4^7 -> 3^6^5^4^7
2=2^7^5^4^7^3^8^6 -> 2^5^4^3^8^6
1=1^6^4^3^8^6^2^7^5 -> 1^4^3^8^2^7^5
算法中是采用(h>>>7)而不是(h>>>8)的算法,应该是考虑1、2、3三位出现重复位^运算的情况。使得最低位上原hashCode的8位都参与了^运算,所以在table.length为默认值16的情况下面,hashCode任意位的变化基本都能反应到最终hash table 定位算法中,这种情况下只有原hashCode第3位高1位变化不会反应到结果中,即:0x7FFFF7FF的i=15。
2.5.3) HashMap的性能参数:
HashMap 包含如下几个构造器:
HashMap():构建一个初始容量为 16,负载因子为 0.75 的 HashMap。
HashMap(int initialCapacity):构建一个初始容量为 initialCapacity,负载因子为 0.75 的 HashMap。
HashMap(int initialCapacity, float loadFactor):以指定初始容量、指定的负载因子创建一个 HashMap。
HashMap的基础构造器HashMap(int initialCapacity, float loadFactor)带有两个参数,它们是初始容量initialCapacity和加载因子loadFactor。
initialCapacity:HashMap的最大容量,即为底层数组的长度。
loadFactor:负载因子loadFactor定义为:散列表的实际元素数目(n)/ 散列表的容量(m)。
负载因子衡量的是一个散列表的空间的使用程度,负载因子越大表示散列表的装填程度越高,反之愈小。对于使用链表法的散列表来说,查找一个元素的平均时间是O(1+a),因此如果负载因子越大,对空间的利用更充分,然而后果是查找效率的降低;如果负载因子太小,那么散列表的数据将过于稀疏,对空间造成严重浪费。
HashMap的实现中,通过threshold字段来判断HashMap的最大容量:
threshold = (int)(capacity * loadFactor);
结合负载因子的定义公式可知,threshold就是在此loadFactor和capacity对应下允许的最大元素数目,超过这个数目就重新resize,以降低实际的负载因子。默认的的负载因子0.75是对空间和时间效率的一个平衡选择。当容量超出此最大容量时, resize后的HashMap容量是容量的两倍:
if (size++ >= threshold)
resize(2 * table.length);
hash碰撞和HashMap的退化hash碰撞在HashMap中的表现为: 不同的key, 计算出相同的index. 如果对所有的key调用indexFor方法的返回值都是相同的, 那么HashMap就退化为链表, 这对性能的影响也是非常大的. 几个月前的闹得沸沸扬扬的hash碰撞攻击就是基于这样的原理.常用的web框架都会将请求中的参数保存在HashMap(或HashTable)中, 如果客户端根据Web应用框架采用的Hash函数来通过某种Hash攻击的方式获得大量的碰撞, 那么HashMap就会退化为链表, 服务器有可能处理一次请求要花上十几分钟甚至几个小时的时间...
2.5.4) Fail-Fast机制:
我们知道java.util.HashMap不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将抛出ConcurrentModificationException,这就是所谓fail-fast策略。
这一策略在源码中的实现是通过modCount域,modCount顾名思义就是修改次数,对HashMap内容的修改都将增加这个值,那么在迭代器初始化过程中会将这个值赋给迭代器的expectedModCount。
HashIterator() {
expectedModCount = modCount;
if (size > 0) { // advance to first entry
Entry[] t = table;
while (index < t.length && (next = t[index++]) == null)
;
}
}
在迭代过程中,判断modCount跟expectedModCount是否相等,如果不相等就表示已经有其他线程修改了Map:
注意到modCount声明为volatile,保证线程之间修改的可见性。
final Entry<K,V> nextEntry() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
在HashMap的API中指出:
由所有HashMap类的“collection 视图方法”所返回的迭代器都是快速失败的:在迭代器创建之后,如果从结构上对映射进行修改,除非通过迭代器本身的 remove 方法,其他任何时间任何方式的修改,迭代器都将抛出 ConcurrentModificationException。因此,面对并发的修改,迭代器很快就会完全失败,而不冒在将来不确定的时间发生任意不确定行为的风险。
注意,迭代器的快速失败行为不能得到保证,一般来说,存在非同步的并发修改时,不可能作出任何坚决的保证。快速失败迭代器尽最大努力抛出 ConcurrentModificationException。因此,编写依赖于此异常的程序的做法是错误的,正确做法是:迭代器的快速失败行为应该仅用于检测程序错误。
4.参考资料
深入理解hashmap
HashMap的hash方法分析
转载自:http://blog.csdn.net/sgbfblog/article/details/7580510
HashMap全部源码详解:http://blog.csdn.net/dyllove98/article/details/9207601
java8与java6实现HashMap的区别:http://coderbee.net/index.php/java/20131018/519
HashMap源码分析的步骤:http://ciding.iteye.com/blog/1320547
另外参考:
http://410063005.iteye.com/blog/1677023
http://blog.csdn.net/jzhf2012/article/details/8540670
http://alex09.iteye.com/blog/539545
- JAVA类库分析之HashMap
- java 类库分析之HashMap
- Java集合类之HashMap源码分析
- java源码分析之HashMap
- Java源码分析之HashMap
- java源码分析之HashMap
- Java源码分析之HashMap
- JAVA之HashMap源码分析
- Java源码分析之HashMap
- java源码分析之HashMap
- JAVA源码分析之HashMap
- java HashMap类分析
- java集合类深入分析之HashSet, HashMap篇
- java集合类深入分析之HashSet, HashMap篇
- java集合类深入分析之HashSet, HashMap篇
- java集合类深入分析之HashSet, HashMap篇
- java集合类深入分析之HashSet, HashMap
- Java HashMap 分析之二:Hash code
- 排位赛第二场E题以及排位赛第三场题解
- hdu 4857 逃生 (拓扑排序+保证最小在前面)
- UDK——VS开发环境配置:nFringe 与 UnrealScriptIDE
- 为RT-Thread实现一个傻瓜式的工程向导工具(二)
- UItableView编辑的使用edit, UItableView的一些常用方法
- java 类库分析之HashMap
- RGB图像旋转90度编程完成-视频处理基础(3)
- 解决相册图片旋转的问题
- 虚函数重载的相关问题
- node之版本升级和管理
- linux 内存管理系列2
- 比较大小-类模板
- Android常用类库说明
- Spring3.0与Quartz的整合实现定时任务调度


