ACM总结之精度
来源:互联网 发布:个人下载网站源码 编辑:程序博客网 时间:2024/05/21 10:45
计算几何头疼的地方一般在于代码量大和精度问题,代码量问题只要平时注意积累模板一般就不成问题了。精度问题则不好说,有时候一个精度问题就可能成为一道题的瓶颈,简直“画龙点睛”。这些年的题目基本是朝着越来越不卡精度的方向发展了,但是也不乏一些%^&%题#$%$^,另外有些常识不管题目卡不卡,都是应该知道的。今天我就开膛回顾下见过且还有印象的精度问题,由于本人见识和记忆均有限,望各位大神瞄过后不吝补充。另外,为了弥补我匮乏的文思,我可能乱扯些不太相关或者尽人皆知的东西凑数。那么,现在开始。
计算几何的精度问题说到底其实是浮点数的精度问题,但我觉得“计算几何”比“浮点数”更能吸引眼球,所以选了这个标题。
1.浮点数为啥会有精度问题:
浮点数(以C/C++为准),一般用的较多的是float, double。
占字节数
数值范围
十进制精度位数
float
4
-3.4e-38~3.4e38
6~7
double
8
-1.7e-308~1.7e308
14~15
如果内存不是很紧张或者精度要求不是很低,一般选用double。14位的精度(是有效数字位,不是小数点后的位数)通常够用了。注意,问题来了,数据精度位数达到了14位,但有些浮点运算的结果精度并达不到这么高,可能准确的结果只有10~12位左右。那低几位呢?自然就是不可预料的数字了。这给我们带来这样的问题:即使是理论上相同的值,由于是经过不同的运算过程得到的,他们在低几位有可能(一般来说都是)是不同的。这种现象看似没太大的影响,却会一种运算产生致命的影响: ==。恩,就是判断相等。注意,C/C++中浮点数的==需要完全一样才能返回true。来看下面这个例子:
#include<stdio.h>
#include<math.h>
int main()
{
double a = asin(sqrt(2.0) / 2) * 4.0;
double b = acos(-1.0);
printf(" a = %.20lf\n", a);
printf(" b = %.20lf\n", b);
printf(" a - b = %.20lf\n", a - b);
printf("a == b = %d\n", a == b);
return 0;
}
输出:
a = 3.14159265358979360000
b = 3.14159265358979310000
a - b = 0.00000000000000044409
a == b = 0
我们解决的办法是引进eps,来辅助判断浮点数的相等。
2. eps
eps缩写自epsilon,表示一个小量,但这个小量又要确保远大于浮点运算结果的不确定量。eps最常见的取值是1e-8左右。引入eps后,我们判断两浮点数a、b相等的方式如下:
定义三出口函数如下: int sgn(double a){return a < -eps ? -1 : a < eps ? 0 : 1;}
则各种判断大小的运算都应做如下修正:(sgn(x),x>0,return 1;x=0,return 0;x<0,return -1)
传统意义
修正写法1
修正写法2
a == b
sgn(a - b) == 0
fabs(a – b) < eps
a != b
sgn(a - b) != 0
fabs(a – b) > eps
a < b
sgn(a - b) < 0
a – b < -eps
a <= b
sgn(a - b) <= 0
a – b < eps
a > b
sgn(a - b) > 0
a – b > eps
a >= b
sgn(a - b) >= 0
a – b > -eps
这样,我们才能把相差非常近的浮点数判为相等;同时把确实相差较大(差值大于eps)的数判为不相等。
PS: 养成好习惯,尽量不要再对浮点数做==判断。例如,我的修正写法2里就没有出现==。
3. eps带来的函数越界
如果sqrt(a), asin(a), acos(a) 中的a是你自己算出来并传进来的,那就得小心了。
如果a本来应该是0的,由于浮点误差,可能实际是一个绝对值很小的负数(比如1e-12),这样sqrt(a)应得0的,直接因a不在定义域而出错。
类似地,如果a本来应该是±1,则asin(a)、acos(a)也有可能出错。
因此,对于此种函数,必需事先对a进行校正。
4. 输出陷阱I
这一节和下一节一样,都是因为题目要求输出浮点数,导致的问题。而且都和四舍五入有关。
说到四舍五入,就再扯一下相关内容,据我所知有三种常见的方法:
1. printf(“%.3lf”, a); //保留a的三位小数,按照第四位四舍五入
2. (int)a; //将a靠进0取整
3. ceil(a); floor(a); //顾名思义,向上取证、向下取整。需要注意的是,这两个函数都返回double,而非int
其中第一种很常见于输出(nonsense…)。
现在考虑一种情况,题目要求输出保留两位小数。有个case的正确答案的精确值是0.005,按理应该输出0.01,但你的结果可能是0.005000000001(恭喜),也有可能是0.004999999999(悲剧),如果按照printf(“%.2lf”, a)输出,那你的遭遇将和括号里的字相同。
解决办法是,如果a为正,则输出a+eps, 否则输出a-eps
典型案例: POJ2826
5. 输出陷阱II
ICPC题目输出有个不成文的规定(有时也成文),不要输出: -0.000
那我们首先要弄清,什么时候按printf(“%.3lf\n”, a)输出会出现这个结果。
直接给出结果好了:a∈(-0.000499999……, -0.000……1)
所以,如果你发现a落在这个范围内,请直接输出0.000。更保险的做法是用sprintf直接判断输出结果是不是-0.000再予处理。
典型案例:UVA746
6. 范围越界
这个严格来说不属于精度范畴了,不过凑数还是可以的。请注意,虽然double可以表示的数的范围很大,却不是不穷大,上面说过最大是1e308。所以有些时候你得小心了,比如做连乘的时候,必要的时候要换成对数的和。
典型案例:HDU3558
7. 关于set<T>
有时候我们可能会有这种需求,对浮点数进行 插入、查询是否插入过 的操作。手写hash表是一个方法(hash函数一样要小心设计),但set不是更方便吗。但set好像是按==来判重的呀?貌似行不通呢。经观察,set不是通过==来判断相等的,是通过<来进行的,具体说来,只要a<b 和 b<a 都不成立,就认为a和b相等,可以发现,
如果将小于定义成: bool operator < (const Dat dat)const{return val < dat.val - eps;}就可以解决问题了。 (基本类型不能重载运算符,所以封装了下)
8. 输入值波动过大
这种情况不常见,不过可以帮助你更熟悉eps。假如一道题输入说,给一个浮点数a, 1e-20 < a < 1e20。那你还敢用1e-8做eps么?合理的做法是把eps按照输入规模缩放到合适大小。
典型案例: HUSTOJ 1361
9. 一些建议
容易产生较大浮点误差的函数有asin、 acos。欢迎尽量使用atan2。
另外,如果数据明确说明是整数,而且范围不大的话,使用int或者long long代替double都是极佳选择,因为就不存在浮点误差了(尽管我几乎从来都只用double --!)
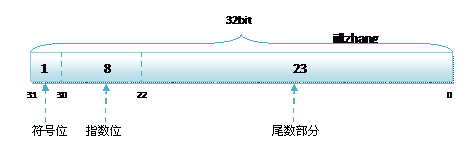
C语言和C#语言中,对于浮点类型的数据采用单精度类型(float)和双精度类型(double)来存储,float数据占用32bit, double数据占用64bit,我们在声明一个变量float f= 2.25f的时候,是如何分配内存的呢?如果胡乱分配,那世界岂不是乱套了么,其实不论是float还是double在存储方式上都是遵从IEEE的规范 的,float遵从的是IEEE R32.24 ,而double 遵从的是R64.53。
无论是单精度还是双精度在存储中都分为三个部分:
- 符号位(Sign) : 0代表正,1代表为负
- 指数位(Exponent):用于存储科学计数法中的指数数据,并且采用移位存储
- 尾数部分(Mantissa):尾数部分
其中float的存储方式如下图所示:
而双精度的存储方式为:

R32.24和R64.53的存储方式都是用科学计数法来存储数据的,比如8.25用十进制的科学计数法表示就为:8.25*![]() ,而120.5可以表示为:1.205*
,而120.5可以表示为:1.205*![]() , 这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数 法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用 二进制的科学计数法表示1000.01可以表示为1.0001*
, 这些小学的知识就不用多说了吧。而我们傻蛋计算机根本不认识十进制的数据,他只认识0,1,所以在计算机存储中,首先要将上面的数更改为二进制的科学计数 法表示,8.25用二进制表示可表示为1000.01,我靠,不会连这都不会转换吧?那我估计要没辙了。120.5用二进制表示为:1110110.1用 二进制的科学计数法表示1000.01可以表示为1.0001*![]() ,1110110.1可以表示为1.1101101*
,1110110.1可以表示为1.1101101*![]() ,任何一个数都的科学计数法表示都为1.xxx*
,任何一个数都的科学计数法表示都为1.xxx*![]() , 尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了 24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点, 24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以 指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。
, 尾数部分就可以表示为xxxx,第一位都是1嘛,干嘛还要表示呀?可以将小数点前面的1省略,所以23bit的尾数部分,可以表示的精度却变成了 24bit,道理就是在这里,那24bit能精确到小数点后几位呢,我们知道9的二进制表示为1001,所以4bit能精确十进制中的1位小数点, 24bit就能使float能精确到小数点后6位,而对于指数部分,因为指数可正可负,8位的指数位能表示的指数范围就应该为:-127-128了,所以 指数部分的存储采用移位存储,存储的数据为元数据+127,下面就看看8.25和120.5在内存中真正的存储方式。
首先看下8.25,用二进制的科学计数法表示为:1.0001*![]()
按照上面的存储方式,符号位为:0,表示为正,指数位为:3+127=130 ,位数部分为,故8.25的存储方式如下图所示:

而单精度浮点数120.5的存储方式如下图所示:
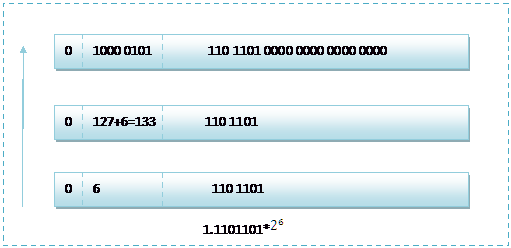
那么如果给出内存中一段数据,并且告诉你是单精度存储的话,你如何知道该数据的十进制数值呢?其实就是对上面的反推过程,比如给出如下内存 数据:0100001011101101000000000000,首先我们现将该数据分段,0 10000 0101 110 1101 0000 0000 0000 0000,在内存中的存储就为下图所示:
![]()
根据我们的计算方式,可以计算出,这样一组数据表示为:1.1101101*![]() =120.5
=120.5
而双精度浮点数的存储和单精度的存储大同小异,不同的是指数部分和尾数部分的位数。所以这里不再详细的介绍双精度的存储方式了,只将120.5的最后存储方式图给出,大家可以仔细想想为何是这样子的
![]()
下面我就这个基础知识点来解决一个我们的一个疑惑,请看下面一段程序,注意观察输出结果
float f = 2.2f;
double d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
f = 2.25f;
d = (double)f;
Console.WriteLine(d.ToString("0.0000000000000"));
可能输出的结果让大家疑惑不解,单精度的2.2转换为双精度后,精确到小数点后13位后变为了2.2000000476837,而单精度的 2.25转换为双精度后,变为了2.2500000000000,为何2.2在转换后的数值更改了而2.25却没有更改呢?很奇怪吧?其实通过上面关于两 种存储结果的介绍,我们已经大概能找到答案。首先我们看看2.25的单精度存储方式,很简单 0 1000 0001 001 0000 0000 0000 0000 0000,而2.25的双精度表示为:0 100 0000 0001 0010 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000,这样2.25在进行强制转换的时候,数值是不会变的,而我们再看看2.2呢,2.2用科学计数法表示应该为:将十进制的小数转换为二进制的小数 的方法为将小数*2,取整数部分,所以0.282=0.4,所以二进制小数第一位为0.4的整数部分0,0.4×2=0.8,第二位为0,0.8*2= 1.6,第三位为1,0.6×2 = 1.2,第四位为1,0.2*2=0.4,第五位为0,这样永远也不可能乘到=1.0,得到的二进制是一个无限循环的排列 00110011001100110011... ,对于单精度数据来说,尾数只能表示24bit的精度,所以2.2的float存储为:
![]()
但是这样存储方式,换算成十进制的值,却不会是2.2的,应为十进制在转换为二进制的时候可能会不准确,如2.2,而double类型的数 据也存在同样的问题,所以在浮点数表示中会产生些许的误差,在单精度转换为双精度的时候,也会存在误差的问题,对于能够用二进制表示的十进制数据,如 2.25,这个误差就会不存在,所以会出现上面比较奇怪的输出结果。
- ACM总结之精度
- ACM之博弈论总结
- ACM double精度问题
- JAVA问题总结之6--强制转换损失精度分析
- Double 精度问题总结
- java浮点精度总结
- acm集训之暑期社会实践总结
- ACM学习总结之A+B问题
- ACM 计算几何中的精度问题
- ACM中浮点数精度问题
- ACM中的浮点数精度处理
- ACM中浮点数精度处理
- ACM中的浮点数精度处理
- float 精度之坑
- ACM 总结
- ACM总结
- ACM总结
- acm总结
- 黑马程序员_Java基础
- OGRE之跳出漫长的编译等待
- JavaScript学习 jquery13 其他事件
- 一 认识lucene
- 表单样式美化(1)-----输入框Text,密码框Password,文本域Textarea样式美化
- ACM总结之精度
- 机房收费系统之导出为Excel
- suse11下oracle_rac安装准备
- WPF名称空间
- IOS:Objective-C字面量
- 构造函数为什么不能为虚函数 & 基类的析构函数为什么要为虚函数
- 初步接触angular.js---一些基本概念的理解
- iOS: 枚举类型 enum,NS_ENUM,NS_OPTIONS
- 12. 分配排序


