概率估计
来源:互联网 发布:女生适合网络还是软件 编辑:程序博客网 时间:2024/04/30 15:31
最大似然估计
最大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。简单而言,假设我们要统计全国人口的身高,首先假设这个身高服从服从正态分布,但是该分布的均值与方差未知。我们没有人力与物力去统计全国每个人的身高,但是可以通过采样,获取部分人的身高,然后通过最大似然估计来获取上述假设中的正态分布的均值与方差。
最大似然估计中采样需满足一个很重要的假设,就是所有的采样都是独立同分布的。下面我们具体描述一下最大似然估计:
首先,假设 为独立同分布的采样,θ为模型参数,f为我们所使用的模型,遵循我们上述的独立同分布假设。参数为θ的模型f产生上述采样可表示为
为独立同分布的采样,θ为模型参数,f为我们所使用的模型,遵循我们上述的独立同分布假设。参数为θ的模型f产生上述采样可表示为

回到上面的“模型已定,参数未知”的说法,此时,我们已知的为 ,未知为θ,故似然定义为:
,未知为θ,故似然定义为:
 (1)
(1)
在实际应用中常用的是两边取对数,得到公式如下:

其中 称为对数似然,而
称为对数似然,而 称为平均对数似然。而我们平时所称的最大似然为最大的对数平均似然,即:
称为平均对数似然。而我们平时所称的最大似然为最大的对数平均似然,即:
 (2)
(2)
因此,求总体参数的极大似然估计值θ的问题就是求似然函数Inθ 的最大值问题.这可通过解下面的方程其导数来解决。
最大似然估计的一般求解过程:
(1) 写出似然函数;
(2) 对似然函数取对数,并整理;
(3) 求导数 ;
(4) 解似然方程
最大后验估计(MAP)
最大后验估计是根据经验数据获得对难以观察的量的点估计。与最大似然估计类似,但是最大的不同时,最大后验估计的融入了要估计量的先验分布在其中。故最大后验估计可以看做规则化的最大似然估计。
对最大似然估计,假设x为独立同分布的采样,θ为模型参数,f为我们所使用的模型。那么最大似然估计可以表示为:

现在,假设θ的先验分布为g。
通过贝叶斯理论
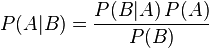
其中P(A|B)是在B发生的情况下A发生的可能性。
对于θ的后验分布如下式所示:

最后验分布的目标为:

注:最大后验估计可以看做贝叶斯估计的一种特定形式。
举例来说:
假设有五个袋子,各袋中都有无限量的饼干(樱桃口味或柠檬口味),已知五个袋子中两种口味的比例分别是
樱桃 100%
樱桃 75% + 柠檬 25%
樱桃 50% + 柠檬 50%
樱桃 25% + 柠檬 75%
柠檬 100%
如果只有如上所述条件,那问从同一个袋子中连续拿到2个柠檬饼干,那么这个袋子最有可能是上述五个的哪一个?
我们首先采用最大似然估计来解这个问题,写出似然函数。假设从袋子中能拿出柠檬饼干的概率为p(我们通过这个概率p来确定是从哪个袋子中拿出来的),则似然函数可以写作

由于p的取值是一个离散值,即上面描述中的0,25%,50%,75%,1。我们只需要评估一下这五个值哪个值使得似然函数最大即可,得到为袋子5。这里便是最大似然估计的结果。
上述最大似然估计有一个问题,就是没有考虑到模型本身的概率分布,下面我们扩展这个饼干的问题。
假设拿到袋子1或5的机率都是0.1,拿到2或4的机率都是0.2,拿到3的机率是0.4,那同样上述问题的答案呢?这个时候就变MAP了。我们根据公式

写出我们的MAP函数。

根据题意的描述可知,p的取值分别为0,25%,50%,75%,1,g的取值分别为0.1,0.2,0.4,0.2,0.1.分别计算出MAP函数的结果为:0,0.0125,0.125,0.28125,0.1.由上可知,通过MAP估计可得结果是从第四个袋子中取得的最高。
上述都是离散的变量,那么连续的变量呢?假设 为独立同分布的
为独立同分布的 ,μ有一个先验的概率分布为
,μ有一个先验的概率分布为 。那么我们想根据来找到μ的最大后验概率。根据前面的描述,写出MAP函数为:
。那么我们想根据来找到μ的最大后验概率。根据前面的描述,写出MAP函数为:

此时我们在两边取对数可知。所求上式的最大值可以等同于求

的最小值。求导可得所求的μ为

以上便是对于连续变量的MAP求解的过程。
在MAP中我们应注意的是:
MAP与MLE最大区别是MAP中加入了模型参数本身的概率分布,或者说。MLE中认为模型参数本身的概率的是均匀的,即该概率为一个固定值。
- 概率估计
- 概率密度估计简介
- 概率密度估计简介
- 利用LIBSVM估计概率
- 概率密度估计简介
- 概率密度函数估计
- 概率密度估计
- 概率密度函数估计简介
- 基数估计:线性概率计数器
- Parzen window概率密度估计
- 核概率密度估计介绍
- 概率密度函数估计简介
- Perzen窗概率密度估计
- Parzen window概率密度估计
- MATLAB概率密度函数估计
- 极大似然估计 最大后验概率估计
- 最大似然估计和最大后验概率估计
- Parzen窗法概率密度函数估计
- eclipse spring和Hibernate插件安装
- memcpy和bcopy区别
- java MessageDigest加密 md5 sha
- 闪存逐鹿——NVMe引领闪存新时代
- 第9章 接口 —— 《Thinking in Java》学习笔记
- 概率估计
- Android Camera代码位置
- MFC修改button的颜色、背景、边框、对话框标题
- php封装mysql操作类
- HDU 4026 Unlock the Cell Phone(动态规划)
- 从大局着眼,从小事着手
- 大数据处理学习之 垃圾邮件判定1
- 01_hibernate快速预览demo
- Get URL parameters & values with jQuery


