SolrCloud原理
来源:互联网 发布:刷爱奇艺会员软件 编辑:程序博客网 时间:2024/06/06 01:00
SolrCloud 是基于 Solr 和 Zookeeper 的分布式搜索方案,是正在开发中的 Solr4.0 的核心组件之一,它的主要思想是使用 Zookeeper 作为集群的配置信息中心。
它有几个特色功能:①集中式的配置信息 ②自动容错 ③近实时搜索 ④查询时自动负载均衡。
下面看看 wiki 的文档:
1、SolrCloud
SolrCloud 是指 Solr 中一套新的潜在的分发能力。这种能力能够通过参数让你建立起一个高可用、
容错的 Solr 服务集群。当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud(solr 云)。
看看下面“启动”部分内容,快速的学会怎样启动一个集群。后面有 3 个快速简单的例子,它们展现怎样启动一个逐步越来越复杂的集群。检出例子之后,需要翻阅后面的部分了解更加细节的信息。
2、关于 SolrCores 和 Collections 的一点儿东西
对于单独运行的 Solr 实例,它有个东西叫 SolrCore(Solr.xml 中配置的),它是本质上独立的索引块。如果你打算多个索引块,你就创建多个 SolrCores。当同时部署SolrCloud 的时,独立的索引块可以跨越多个 Solr 实例。这意味着一个单独的索引块能由不同服务器设备上多个 SolrCore 的索引块组成。我们把组成一个逻辑索引块的所有 SolrCores 叫做一个独立索引块儿(collection)。一个独立索引块是本质上一个独立的跨越多个 SolrCore 索引块的索引块,同时索引块尽可能随着多余的设备进行缩放。如果你想把你的两个 SolrCore Solr 建立成 SolrCloud,你将有 2 个独立索引块,每个有多个独立里的 SolrCores 组成。
3、启动
下载 Solr4-Beta 或更高版本。
如果你还没了解,通过简单的 Solr 指南让自己熟悉 Solr。注意:在通过指南了解云特点前,重设所有的配置和移除指南的文档.复制带有预先存在的 Solr 索引的例子目录将导致文档计数关闭Solr 内嵌使用了Zookeeper 作为集群配置和协调运作的仓储。协调考虑作为一个包含所有 Solr 服务信息的分布式文件系统。
如果你想用一个其他的而不是 8983 作为 Solr 端口,去看下面’ Parameter Reference’部分下的关于solr.xml 注解
例 A:简单的 2 个 shard 集群
这个例子简单的创建了一个代表一个独立索引块的两个不同的 shards 的两个 solr 服务组成的集群。从我们将需要两个 solr 服务器,简单的复制例子目录副本作为第二个服务器时,要确保没有任何索引存在。
rm-r example/solr/collection1/data/*cp-r example example2下面的命令启动了一个 solr 服务同时引导了一个新的 solr 集群
cdexamplejava -Dbootstrap_confdir=./solr/collection1/conf-Dcollection.configName=myconf -DzkRun -DnumShards=2 -jar start.jar•-DzkRun 该参数将促使一个内嵌的 zookeeper 服务作为 Solr 服务的部分运行起来。
•-Dbootstrap_confdir=./solr/collection1/conf 当我们还没有 zookeeper 配置时,这个参数导致本地路径./solr/conf 作为“myconf”配置被加载.“myconf”来自下面的“collection.configName” 参数定义。
•-Dcollection.configName=myconf 设置用于新集合的配置名。省略这个参数将导致配置名字为默认的“configuration1”
•-DnumShards=2 我们打算将索引分割到逻辑分区的个数。
浏览 http://localhost:8983/solr/#/~cloud 地址,看看集群的状态。你从 zookeeper 浏览程序能看到 Solr 配置文件被加载成”myconf”,同时一个新的叫做”collection1”的文档集合被创建.collection1 下是碎片列表,这些碎片组成了那完整的集合。
现在我们想要启动我们的第二个服务器;因为我们没明确设置碎片 id,它将自动被设置成 shard2,启动第二个服务器,指向集群
cdexample2java -Djetty.port=7574 -DzkHost=localhost:9983 -jar start.jar•-Djetty.port=7574 只是一种用于让 Jetty servlet 容器使用不同端口的方法
•-DzkHost=localhost:9983 指向全体包含集群状态的 Zookeeper 服务.这个例子中,我们运行的是一个内嵌在第一个 solr 服务器中的独立的 Zookeeper 服务.默认情况下,一个内嵌的Zookeeper 服务运行在 9983 端口上。
如果你刷新浏览器,你现在在 collection1 下应该看到两个shard1 和 shard2。
接下来,索引一些文档。如果你想要快速完成一些,像 java 你能够使用 CloudSolrServer solrj 的实现和简单的用 Zookeeper 地址初始化它就可以了.或者也可以随便选择某个 solr 实例添加文档,这些文档自动的被导向属于他们的地方。
cdexampledocsjava -Durl=http://localhost:8983/solr/collection1/update-jar post.jar ipod_video.xmljava -Durl=http://localhost:8983/solr/collection1/update-jar post.jar monitor.xmljava -Durl=http://localhost:8983/solr/collection1/update-jar post.jar mem.xml现在,发起一个获得覆盖整个集合的分布式搜索服务搜索到的任何一个服务的结果的请求:
http://localhost:8983/solr/collection1/select?q=*:*如果在任一个点你希望重新加载或尝试不同的配置,你能通过关闭服务器后简单的删除solr/zoo_data 目录方式删除所有 zookeeper 的云状态。
例 B:简单的支持副本的两个碎片集群
有先前的例子,这个例子通过再创建 shard1 和 shard2 副本很容易创建起来。额外的 shard 副本用于高可用性和容错性,或用于提高集群的检索能能力。
首先,通过前一个例子, 我们已经有两个碎片和一些文档索引在里面了。然后简单的复制那两个服务:
cp-r example exampleBcp-r example2 example2B然后在不同的端口下启动这两个新的服务,每个都在各自的视窗下执行
cdexampleBjava -Djetty.port=8900 -DzkHost=localhost:9983 -jar start.jarcdexample2Bjava -Djetty.port=7500 -DzkHost=localhost:9983 -jar start.jar刷新 zookeeper 浏览页面,核实 4 个 solr 节点已经启动,并且每个 shard 有两个副本,因为我们已经告诉 Solr 我们想要 2 个逻辑碎片,启动的实例 3 和 4 自动的被负值为两个 shards 的副
本。
现在,向任何一个服务器发送请求来查询这个集群
http://localhost:7500/solr/collection1/select?q=*:*多次发送这个请求,来研究 solr 服务的日志。你应该能够发现 Solr 实现跨副本的负载均衡请求,用不同的服务满足每一个请求。 浏览器发送请求的服务器里有一个顶层请求的日志描述,也会有被合并起来生成完成响应的子请求的日志描述。
为了证明故障切换的可用性,在任何一个服务器(除了运行 Zookeeper 的服务器)运行窗口下按下CTRL-C。一旦那个服务实例停止运行,就向剩余运行的服务器的任何一个发送另一个查询请求,你应该仍然看到完整的结果。
SolrCloud 能够持续提供完整查询服务直到最后一个维护每一个碎片的服务器当机.你能通过明确地关闭各个实例和查询结果来证明这种高可用性。如果你关掉维护某一个碎片的所有服务器,请求其他服务器时将会返回 503 错误结果。要想从依然运行的碎片服务中返回可用的正确文档,需要添加shards.tolerant=true 查询参数。
SolrCloud 用多主服务+监控者服务实现。这意味着某写节点或副本扮演一种特殊角色。你不需要担忧你关掉的是主服务或是集群监控,如果你关掉它们中的一个,故障切换功能将自动选出新的主服务或新的监控服务,新的服务将无缝接管各自的工作。任何 Solr 实例都能被升级为这些角色中的某个角色。
例 C:支持副本和完整 zookeeper 服务的两个碎片集群
例 B 的问题是可以 有足够多的服务器保证任何一个损坏的服务器的信息幸存下来,但确只有一个包含集群状态的 zookeeper 服务器。如果那台 zookeeper 服务器损坏,分布式查询将仍然工作在上次zookeeper 保存的集群状态下,可能没有机会改变集群的状态了。
在 a zookeeper ensemble(zookeeper 集群)中运行多个 zookeeper 服务器保证 zookeeper 服务的高可用性。每个 zookeeper 服务器需要知道集群中其他服务器,且这些服务器中的一个主服务器需要提供服务。例如: 3 台组成的 zookeeper 集群允许任一个故障,而后通过剩余 2 个协商一个主服务继续提供服务。5 台的需要允许一次 2 个服务器故障。
对于用于生产服务时,推荐运行一个额外的 zookeeper 集群而不是运行内嵌在 Solr 里面的 zookeeper服务。在这里你能阅读更多关于建立 zookeeper 集群的知识。对于这个例子,为了简单点我们将用内嵌的 zookeeper 服务。
首先停止 4 个服务器并清理 zookeeper 数据
rm-r example*/solr/zoo_data我们将分别在 8983,7574,8900,7500 端口运行服务。默认的方式是在主机端口+1000 运行内嵌的 zookeeper 服务,所以如果我们用前 3 个服务器运行内嵌 zookeeper,地址分别是 localhost:9983,localhost:8574,localhost:9900。
为了方便,我们上传第一个服务器 solr 配置到集群。你将注意到第一个服务器阻塞了,直到你启动了第二个服务器。这是因为 zookeeper 需要达到足够的服务器数目才允许操作。
cdexamplejava -Dbootstrap_confdir=./solr/collection1/conf-Dcollection.configName=myconf -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -DnumShards=2 -jar start.jarcdexample2java -Djetty.port=7574 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jarcdexampleBjava -Djetty.port=8900 -DzkRun -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jarcdexample2Bjava -Djetty.port=7500 -DzkHost=localhost:9983,localhost:8574,localhost:9900 -jar start.jar现在我们已经运行起由 3 个内嵌 zookeeper 服务组成的集群,尽管某个服务丢失依然保持工作。通过 CTRL+C 杀掉例 B 的服务器然后刷新浏览器看 zookeeper 状态可以断定 zookeeper 服务仍然工作。注意:当运行在多个 host 上时,在每个需要设置对应的 hostname,-DzkRun=hostname:port,-DzkHosts 使用准确的 host 名字和端口,默认的 localhost 将不能工作。
4、ZooKeeper
为了容错和高可用多个 zookeeper 服务器一起运行,这种模式叫做 an ensemble。对于生产环境,推荐额外运行 zookeeper ensemble 来代替 solr 内嵌的 zookeeper 服务。关于下载和运行 ensemble的更多信息访问 Apache ZooKeeper 。 更特殊的是,试着启动和管理 zookeeper。它的运行实际上非常简单。你能容银让 Solr 运行 Zookeeper,但是记住一个 zookeeper 集群不容易进行动态修改。除非将来支持动态修改,否则最好在回滚重启时进行修改。与 Solr 分开处理通常是最可取的。
当 Solr 运行内嵌 zookeeper 服务时,默认使用 solr 端口+1000 作为客户端口,另外,solr 端口+1 作为 zookeeper 服务端口,solr 端口+2 作为主服务选举端口。所以第一个例子中,Solr 运行在 8983端口,内嵌 zookeeper 使用 9983 作为客户端端口,9984 和 9985 作为服务端口。
鉴于确保 Zookeeper 搭建起来是非常快速的,要记住几点:Solr 不强烈要求使用 Zookeeper,很多情况优化可能不是必须的。另外,当添加更多的 Zookeeper 节点对读数据性能会有帮助,但也轻微的降低了写的性能。再有,当集群处于稳定运行时,solr 与 Zookeeper 没有太多的交互。如果你需要优化 zookeeper,这里有几个有益的要点:
1.ZooKeeper在专用的机器上运行效果最好。ZooKeeper 提供的是一种及时服务,专用设备有助于确保及时服务的响应。当然,专用机器并不是必须的。
2.ZooKeeper在事务日志和快照在不同的硬盘驱动器上工作效果最好
3.如果配置支持 solr 的 Zookeeper,各自使用独立的硬盘驱动器有助于性能。
5、通过集合 api 管理集合
你可以通过集合 API 管理集合。在这个 API 壳下,一般使用 CoreAdmin API 异步管理每台服务器上的 SolrCores,对于如果你自己处理使独立的 CoreAdmin API 通过替换 action 参数就能调用每个服务器来说,这无疑是一个必不可少好东西。
①创建接口
http://localhost:8983/solr/admin/collections?action=CREATE&name=mycollection&numShards=3&replicationFactor=4相关参数:
name:将被创建的集合的名字
numShards:集合创建时需要创建逻辑碎片的个数
replicationFactor:每个文档副本数。replicationFactor(复制因子)为 3 意思是每个逻辑碎片将有 3 份副本。注:Solr4.0 中,replicationFactor 是 additional * 副本数 ,而不是副本总数
maxShardsPerNode:一个创建操作将展开创建 numShards*replicationFactor 碎片副本遍布在你的 Solr 节点上,公平分布,同一个碎片的两个副本不会在同一个 Solr 节点上。如果创建操作完成时 Solr 损坏,该操作不会创建出新集合的任何部分。该参数用来防止在同一个 Solr 节点创建太多副本,默认参数 1.如果它的值与整体集合中 numShards*replicationFactor 副本数分布到正常活跃的Solr 节点的数不符,将不能创建任何东西
createNodeSet:如果不提供该参数,创建操作将创建碎片副本展开分布到所有活跃的 Solr 节点上。提供该参数改变用于创建碎片副本的节点集合。参数值的格式是:"<node-name1>,<node-name2>,...,<node-nameN>",
例如:createNodeSet=localhost:8983_solr,localhost:8984_solr,localhost:8985_solr
collection.configName:用于新集合的配置文件的名称。如果不提供该参数将使用集合名称作为配置文件的名称。
Solr4.2
相关参数:name:将被创建的集合别名的名字
collections:逗号分隔的一个或多个集合别名的列表
②删除接口
http://localhost:8983/solr/admin/collections?action=DELETE&name=mycollection相关参数:
<strong>name</strong>:将被删除的集合的名字③重新加载接口
http://localhost:8983/solr/admin/collections?action=RELOAD&name=mycollection相关参数:name:将被重载的集合的名字
④分割碎片接口
http://localhost:8983/solr/admin/collections?action=SPLITSHARD&collection=<collection_name>&shard=shardIdSolr4.3
相关参数:collection:集合的名字
shard:将被分割的碎片 ID
这个命令不能用于使用自定义哈希的集群,因为这样的集群没有一个明确的哈希范围。 它只用于具有plain 或 compositeid 路由的集群。
该命令将分割给定的碎片索引对应的那个碎片成两个新碎片。通过将碎片范围划分成两个相等的分区和根据新碎片范围分割出它在父碎片(被分的碎片)中的文档。新碎片将被命名为 appending_0 和_1。例如:shard=shard1 被分割,新的碎片将被命名为 shard1_0 和 shard1_1。一旦新碎片被创建,它们就被激活同时父碎片(被分的碎片)被暂停因此将没有新的请求到父碎片(被分的碎片)。
该特征达到了无缝分割和无故障时间的要求。原来的碎片数据不会被删除。使用新 API 命令重载碎片用户自己决定。
该特性发布始于 Solr4.3,由于 4.3 发布版本发现了一些 bugs,所以要使用该特性推荐等待 4.3.1。
6、集合别名
别名允许你创建独立的指向一个或多个真是集合的虚拟集合,你能够在运行时修改别名。
①创建别名
http://localhost:8983/solr/admin/collections?action=CREATEALIAS&name=alias&collections=collection1,collection2,…创建或修改别名。用于发送修改的别名应该只映射一个独立的集合。读的别名能映射一个或多个集合。
②移除存在的别名
http://localhost:8983/solr/admin/collections?action=DELETEALIAS&name=alias移除存在的别名
7、经 CoreAdmin 创建 cores
经过 CoreAdmin 可以创建新的 Solrcores 和使新的 Solrcores 与一个集合关联,创建时附加云相关参数
•collection 这个 core 所属的集合的名字。默认 core 的名字
•shard 这个 core 代表的碎片的 id(可选-通常自动设置一个碎片 id)
•numShards 集合碎片个数。该参数只在集合第一个 core 创建时有用
•collection.<param>=<value> 集合创建时设置属性值,用 collection.configName=<configname>指明新集合的配置文件
curl 'http://localhost:8983/solr/admin/cores?action=CREATE&name=mycore&collection=collection1&shard=shard2'8、分布式请求
查询一个集合的所有碎片(注意:那个集合已经隐含在 URL 中了)
http://localhost:8983/solr/collection1/select?查询一个兼容集合的所有碎片,明确详述如下:
http://localhost:8983/solr/collection1/select?collection=collection1_recent查询多个兼容集合的所有碎片
http://localhost:8983/solr/collection1/select?collection=collection1_NY,collection1_NJ,collection1_CT查询集合的某些碎片。例子中,用户已经按日期对索引进行分割了,每月创建一个新的碎片
http://localhost:8983/solr/collection1/select?shards=shard_200812,shard_200912,shard_201001明确指明以想要查询碎片的地址
http://localhost:8983/solr/collection1/select?shards=localhost:8983/solr,localhost:7574/solr明确指明以想要查询碎片的地址,同时为负载均衡和故障切换给出可选的地址
http://localhost:8983/solr/collection1/select?shards=localhost:8983/solr|localhost:8900/solr,localhost:7574/solr|localhost:7500/solr9、必须的配置
所有必须的配置已经安装在 Solr 的例子中。下面是如果你正在迁移旧的配置文件你需要添加什么,或不应该删除什么
10、schema.xml
字段_version_是必须定义的
<field name="_version_" type="long" indexed="true" stored="true" multiValued="false"/>11、solrconfig.xml
必要有一个更新日志的定义,这个应该被定义在 updateHandler 标签中
<!-- Enables a transaction log, currently used for real-time get."dir" - the target directory for transaction logs, defaults to thesolr data directory. --><updateLog> <strname="dir">${solr.data.dir:}</str></updateLog>必须有一个复制处理调用的定义
<requestHandlername="/replication"class="solr.ReplicationHandler"startup="lazy"/>必须有一个获取实际时间处理的调用的定义
<requestHandlername="/get"class="solr.RealTimeGetHandler"><lstname="defaults"> <strname="omitHeader">true</str></lst></requestHandler>必须有管理句柄的定义
<requestHandlername="/admin/"class="solr.admin.AdminHandlers"/>DistributedUpdateProcessor 是默认更新链的部分也会被自动注入自定义更新链。
<updateRequestProcessorChainname="sample"> <processorclass="solr.LogUpdateProcessorFactory"/> <processorclass="solr.DistributedUpdateProcessorFactory"/> <processorclass="my.package.UpdateFactory"/> <processorclass="solr.RunUpdateProcessorFactory"/></updateRequestProcessorChain>如果不想让它自动注入到你的链中(说明你想使用 SolrCloud 功能,但想自己分发修改)那么在你的链
中指明下面的更新处理工厂: NoOpDistributingUpdateProcessorFactory
12、solr.xml
必须保留 admin path 作为默认 core
<coresadminPath="/admin/cores"/>13、可变集群
当你在一个集合中启动 SolrCore 时通过 numShards 参数可以控制集群的规模。 这个参数一般自动赋给关联每个实例的碎片。启动 numShards 个实例后所有的 SolrCores 都被均匀的加入每个碎片作为副本。
向集合添加 SolrCores 保证其启动是很简单的,你随时都可以进行这样的操作。新的 SolrCore 在激活前会把它的数据同步到碎片中的副本上。
如果你要在几台机器上启动集群,不仅添加副本需要花时间扩展成集群也需要时间,那么,你可以选择通过每部机器负责几个碎片的方式启动(使用多 SolrCores),然后通过对碎片启动副本的形式迁移碎片到新的设备上,最终移除原来设备上的碎片。
Solr4.3 具备新的 API 接口, SPLITSHARD,分割已存在的碎片成两份新的碎片,相关介绍前面讲过。
14、近实时搜索
如果你希望启用近实时搜索,你可能需要修改放在ZooKeeper中的solrconfig.xml文件,添加启动软件自动提交配置,或者通过向集群发送软提交。详见看近实时搜索。
15、参数参考介绍
A.集群参数
B.Solr 云实例参数
参数在 solr.xml 中设置,实例的运行与系统环境变量也有关。重要事项:hostPort 是每个 Solr 实例运行的端口,zookeeper 通过该端口通知集群的状态(剩余等),默认值是 8983。solr.xml 例子用的是 jetty.port 环境变量,所以如果你不想用 8983,那么你启动 Solr前设置 jetty.port 变量,或修改 solr.xml 文件。
C.云实例中 Zookeeper 参数
zkRun默认值 localhost:solrPort+1000配置该参数让 Solr 运行起内嵌的 Zookeeper 服务。参数设置了 Zookeeper 所在的服务器地址。这个值会出现在 zkHost 参数中,我们能够知道都有哪些 zk 服务器。简单模式可以使用默认值;注意:这个值必须是 zkHost 中的一个;另外,多服务器版的不能使用默认的 localhost。zkHost默认值 没有ZooKeeper host 地址——你的ZooKeeper集群一般节点地址使用逗号分割zkClientTimeout默认值 15000session 没有过期前提下,不和ZooKeeper交互的最长间隔zkClientTimeout 参数在 solr.xml 设置,也可以通过系统参数设置。
D.云核参数
shardshard 的ID,默认基于numShards自动分配允许你指定SolrCores里的shard的Id碎片 id 可以在每个 core 元素的属性中配置
16、把配置文件给 ZooKeeper
A.配置启动引导参数
第一次启动 Solr,有两种使用系统参数加载初始化 Zookeeper 配置文件的方法。记住,只用于第一次启动或覆盖配置文件时。每次启动都要带着系统参数,系统参数会覆盖配置文件中名字相同的值。
1.看 solr.xml 文件,找到每个 SolrCore 加载的 conf 目录。 ‘config set’ (配置集)的名字就是 SolrCore的集合的名字,集合使用与它名字相同的配置集合。
2.通过给的配置文件名字从指定目录下加载配置集。尽管没有指定集合到配置集的关联,如果只有一个配置集,集合将自动链接到这个配置集。bootstrap_confdir无默认值如果你通过 -bootstrap_confdir=<目录≶ 启动,指定的配置目录文件将会被提交到ZooKeeper,设置配置名可以用下面的参数:collection.configNamecollection.configName默认值 configuration1通过bootstrap_confdir设置配置集的名称
B.命令行工具
CLI 工具也可以配置 Zookeeper。 它与上面两种方法一样。 它提供一些命令,能够配置集到集合关联,创建 Zookeeper 路径或移除,还能从 zookeeper 下载配置文件到本地。
usage: ZkCLI-c,--collection <arg> for linkconfig: name of the collection-cmd <arg> cmd to run: bootstrap, upconfig, downconfig,linkconfig, makepath, clear-d,--confdir <arg> for upconfig: a directory of configuration files-h,--help bring up this help page-n,--confname <arg> for upconfig, linkconfig: name of the config set-r,--runzk <arg> run zk internally by passing the solr run port -only for clusters on one machine (tests, dev)-s,--solrhome <arg> for bootstrap, runzk: solrhome location-z,--zkhost <arg> ZooKeeper host addressC.例子
# try uploading a conf dirjava -classpath example/solr-webapp/WEB-INF/lib/* org.apache.solr.cloud.ZkCLI -cmd upconfig -zkhost 127.0.0.1:9983 -confdir example/solr/collection1/conf -confname conf1# try linking a collection to a conf setjava -classpath example/solr-webapp/WEB-INF/lib/* org.apache.solr.cloud.ZkCLI -cmd linkconfig -zkhost 127.0.0.1:9983 -collection collection1 -confname conf1# try bootstrapping all the conf dirs in solr.xmljava -classpath example/solr-webapp/WEB-INF/lib/* org.apache.solr.cloud.ZkCLI -cmd bootstrap -zkhost 127.0.0.1:9983 -solrhome example/solrD.脚本
如果你不想使用jettry容器,example/cloud-scripts 目录下有系统脚本文件,它帮你处理了 classpath 和 class name,命令变成为:
sh zkcli.sh -cmd linkconfig -zkhost 127.0.0.1:9983 -collection collection1 -confname conf117、ZooKeeper chroot
如果其他应用已经在用 Zookeeper,你想保持原应用的管理方式,又或者有多个分开的 solrcloud 集群共用一个 zookeeper,你可以用 zookeeper 的‘chroot’选项,来自Zookeeper Session。An optional "chroot" suffix may also be appended to the connection string. This will run the client commands while interpreting all paths relative to this root (similar to the unix chroot command). If used the example would look like: "127.0.0.1:4545/app/a" or "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002/app/a" where the client would be rooted at "/app/a" and all paths would be relative to this root - ie getting/setting/etc... "/foo/bar" would result in operations being run on "/app/a/foo/bar" (from the server perspective).
要使用这个特点,zkHost 参数用上”chroot”后缀,而后简单启动 solr
java -DzkHost=localhost:9983/foo/bar-jar start.jar或者
java -DzkHost=zoo1:9983,zoo2:9983,zoo3:9983/foo/bar-jar start.jar提示:Solr4.0启动时你需要预先创建ZooKeeper路径,Solr4.1以后再使用eitherbootstrap_conf 或 boostrap_confdir 的路径是自动初始化的了。
18、已知的局限性
很少 Solr 搜索框架不支持分布式搜索的。有些情况下,一个框架无法支持分布式,不过,那只是时间和努力的问题。不支持标准分布式搜索的搜索框架,它的 SolrCloud 同样不支持。通过 distrib=false控制是否使用分布式。
组群特点只能是在同一个存储碎片上的组群。必须自定义碎片特征才能使用组群特点。
如果要更新支持 SolrCloud 的 Solr4.0 到 4.1,注意 name_node 参数的定义方式已经改变了。这导致一种情况发生,由于 name_node 用 ip 地址代替了服务器的名字,使 SolrCloud 无法感知到这个name_node。你可以通过 solr.xml 配置 ip 到服务器名的关联解决问题。
19、术语
Collection:A single search index.Shard:A logical section of a single collection (also called Slice). Sometimes people will talk about “Shard” in a physical sense (a manifestation of a logical shard)Replica:A physical manifestation of a logical Shard, implemented as a single Lucene index on a SolrCoreLeader:One Replica of every Shard will be designated as a Leader to coordinate indexing for that ShardSolrCore:Encapsulates a single physical index. One or more make up logical shards (or slices) which make up a collection.Node:A single instance of Solr. A single Solr instance can have multiple SolrCores that can be part of any number of collections.Cluster:All of the nodes you are using to host SolrCores.相关文档:
目录[-]




Apache SolrCloud安装
SolrCloud通过ZooKeeper集群来进行协调,使一个索引进行分片,各个分片可以分布在不同的物理节点上,多个物理分片组成一个完成的索引Collection。SolrCloud自动支持Solr Replication,可以同时对分片进行复制,冗余存储。下面,我们基于Solr最新的4.4.0版本进行安装配置SolrCloud集群。
1. 安装环境
我使用的安装程序各版本如下:
- Solr: Apache Solr-4.4.0
- Tomcat: Apache Tomcat 6.0.36
- ZooKeeper: Apache ZooKeeper 3.4.5
各个目录说明:
- 所有的程序安装在/opt目录下,你可以依照你的实际情况下修改安装目录。
- ZooKeeper的数据目录在:
/data/zookeeper/data - solrhome设置在:
/usr/local/solrhome
2. 规划SolrCloud
- 单一SolrCloud数据集合:primary
- ZooKeeper集群:3台
- SolrCloud实例:3节点
- 索引分片:3
- 复制因子:2
手动将3个索引分片(Shard)的复本(Replica)分布在3个SolrCloud节点上
三个节点:
- 192.168.56.121
- 192.168.56.122
- 192.168.56.123
3. 安装ZooKeeper集群
由于需要用到ZooKeeper,故我们先安装好ZooKeeper集群
首先,在第一个节点上将zookeeper-3.4.5.tar.gz解压到/opt目录:
$ tar zxvf zookeeper-3.4.5.tar.gz -C /opt/创建zookeeper配置文件zookeeper-3.4.5/conf/zoo.cfg,内容如下:
tickTime=2000initLimit=10syncLimit=5dataDir=/data/zookeeper/dataclientPort=2181server.1=192.168.56.121:2888:3888server.2=192.168.56.122:2888:3888server.3=192.168.56.123:2888:3888zookeeper的数据目录指定在/data/zookeeper/data,你也可以使用其他目录,通过下面命令进行创建该目录:
$ mkdir /data/zookeeper/data -p然后,初始化myid,三个节点编号依次为1,2,3,在其余节点上分别执行命令(注意修改编号)。
$ echo "1" >/data/zookeeper/data/myid然后,在第二个和第三个节点上依次重复上面的操作。这样第一个节点中myid内容为1,第二个节点为2,第三个节点为3。
最后,启动ZooKeeper集群,在每个节点上分别启动ZooKeeper服务:
$ cd /opt$ sh zookeeper-3.4.5/bin/zkServer.sh start可以查看ZooKeeper集群的状态,保证集群启动没有问题:
[root@192.168.56.121 opt]# sh zookeeper-3.4.5/bin/zkServer.sh statusJMX enabled by defaultUsing config: /opt/zookeeper-3.4.5/bin/../conf/zoo.cfgMode: follower4. 安装Solr
你可以参考《Apache Solr介绍及安装》
简单来说,执行以下命令:
$ unzip apache-tomcat-6.0.36.zip -d /opt$ unzip solr-4.4.0.zip -d /opt$ cd /opt$ chmod +x apache-tomcat-6.0.36/bin/*.sh$ cp solr-4.4.0/example/webapps/solr.war apache-tomcat-6.0.36/webapps/$ cp solr-4.4.0/example/lib/ext/* apache-tomcat-6.0.36/webapps/solr/WEB-INF/lib/$ cp solr-4.4.0/example/resources/log4j.properties apache-tomcat-6.0.36/lib/在其他节点上重复以上操作完成所有节点的solr的安装。
5. 设置SolrCloud配置文件
安装ZooKeeper集群之前,请确保每台机器上配置/etc/hosts文件,使每个节点都能通过机器名访问。
1、 创建一个SolrCloud目录,并将solr的lib文件拷贝到这个目录:
$ mkdir -p /usr/local/solrcloud/solr-lib/$ cp apache-tomcat-6.0.36/webapps/solr/WEB-INF/lib/* /usr/local/solrcloud/solr-lib/2、 通过bootstrap设置solrhome:
$ java -classpath .:/usr/local/solrcloud/solr-lib/* org.apache.solr.cloud.ZkCLI -zkhost 192.168.56.121:2181,192.168.56.122:2181,192.168.56.123:2181 -cmd bootstrap -solrhome /usr/local/solrhome SolrCloud集群的所有的配置存储在ZooKeeper。 一旦SolrCloud节点启动时配置了-Dbootstrap_confdir参数, 该节点的配置信息将发送到ZooKeeper上存储。基它节点启动时会应用ZooKeeper上的配置信息,这样当我们改动配置时就不用一个个机子去更改了。
3、SolrCloud是通过ZooKeeper集群来保证配置文件的变更及时同步到各个节点上,所以,需要将配置文件上传到ZooKeeper集群中:
$ java -classpath .:/usr/local/solrcloud/solr-lib/* org.apache.solr.cloud.ZkCLI -zkhost 192.168.56.121:2181,192.168.56.122:2181,192.168.56.123:2181 -cmd upconfig -confdir /usr/local/solrcloud/conf/primary/conf -confname primaryconf说明:
- zkhost指定ZooKeeper地址,逗号分割
/usr/local/solrhome/primary/conf目录下存在schema.xml和solrconfig.xml两个配置文件,你可以修改为你自己的目录。- primaryconf为在ZooKeeper上的配置文件名称。
4、把配置文件和目标collection联系起来:
$ java -classpath .:/usr/local/solrcloud/solr-lib/* org.apache.solr.cloud.ZkCLI -zkhost 192.168.56.121:2181,192.168.56.122:2181,192.168.56.123:2181 -cmd linkconfig -collection primary -confname primaryconf说明:
- 创建的collection叫做primary,并指定和primaryconf连接
5、查看ZooKeeper上状态
在任意一个节点的/opt目录下执行如下命令:
$ zookeeper-3.4.5/bin/zkCli.sh [zk: localhost:2181(CONNECTED) 0] ls /[configs, zookeeper, clusterstate.json, aliases.json, live_nodes, overseer, collections, overseer_elect][zk: localhost:2181(CONNECTED) 1] ls /configs[primaryconf][zk: localhost:2181(CONNECTED) 1] ls /collections[primary]查看/configs和/collections目录均有值,说明配置文件已经上传到ZooKeeper上了,接下来启动solr。
6. Tomcat配置与启动
1、修改每个节点上的tomcat配置文件,在环境变量中添加zkHost变量
编辑apache-tomcat-6.0.36/bin/catalina.sh,添加如下代码:
JAVA_OPTS='-Djetty.port=8080 -Dsolr.solr.home=/usr/local/solrhome -DzkHost=192.168.56.122:2181,192.168.56.122:2181,192.168.56.123:2181'在/usr/local/solrhome/目录创建solr.xml:
<?xml version="1.0" encoding="UTF-8" ?><solr persistent="true" sharedLib="lib"> <cores adminPath="/admin/cores" zkClientTimeout="${zkClientTimeout:15000}" hostPort="${jetty.port:8080}" hostContext="${hostContext:solr}"></cores></solr>说明:
-Djetty.port:配置solr使用的端口,默认为8983,这里我们使用的是tomcat,端口为8080-Dsolr.solr.home:配置solr/home-zkHost: 配置zookeeper集群地址,多个地址逗号分隔
最后,在/opt目录下启动tomcat:
$ sh apache-tomcat-6.0.36/bin/startup.sh通过http://192.168.56.121:8080/solr/进行访问,界面如图提示`There are no SolrCores running. `,这是因为配置文件尚未配置solrcore。

7. 创建Collection、Shard和Replication
手动创建Collection及初始Shard
直接通过REST接口来创建Collection,你也可以通过浏览器访问下面地址,如下所示:
$ curl 'http://192.168.56.121:8080/solr/admin/collections?action=CREATE&name=primary&numShards=3&replicationFactor=1'如果成功,会输出如下响应内容:
<response><lst name="responseHeader"> <int name="status">0</int> <int name="QTime">2649</int></lst><lst name="success"> <lst> <lst name="responseHeader"> <int name="status">0</int> <int name="QTime">2521</int> </lst> <str name="core">primary_shard2_replica1</str> <str name="saved">/usr/local/solrhome/solr.xml</str> </lst> <lst> <lst name="responseHeader"> <int name="status">0</int> <int name="QTime">2561</int> </lst> <str name="core">primary_shard3_replica1</str> <str name="saved">/usr/local/solrhome/solr.xml</str> </lst> <lst> <lst name="responseHeader"> <int name="status">0</int> <int name="QTime">2607</int> </lst> <str name="core">primary_shard1_replica1</str> <str name="saved">/usr/local/solrhome/solr.xml</str> </lst></lst></response>上面链接中的几个参数的含义,说明如下:
- name 待创建Collection的名称
- numShards 分片的数量
- replicationFactor 复制副本的数量
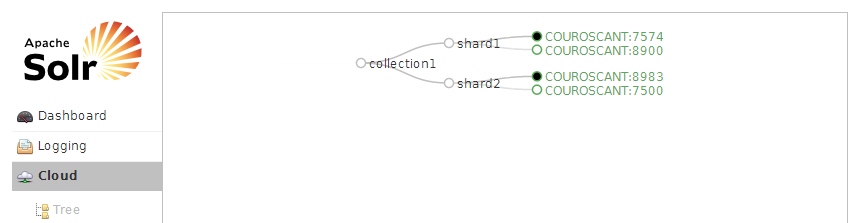
可以通过Web管理页面,访问http://192.168.56.121:8888/solr/#/~cloud,查看SolrCloud集群的分片信息,如图所示:

实际上,我们从192.168.56.121节点可以看到,SOLR的配置文件内容,已经发生了变化,如下所示:
<?xml version="1.0" encoding="UTF-8" ?><solr persistent="true" sharedLib="lib"> <cores adminPath="/admin/cores" zkClientTimeout="20000" hostPort="${jetty.port:8080}" hostContext="${hostContext:solr}"> <core shard="shard2" instanceDir="primary_shard2_replica1/" name="primary_shard2_replica1" collection="primary"/> </cores></solr>同时,你还可以看另外两个节点上的solr.xml文件的变化。
手动创建Replication
下面对已经创建的初始分片进行复制。 shard1已经在192.168.56.123上,我们复制分片到192.168.56.121和192.168.56.122上,执行如下命令:
$ curl 'http://192.168.56.121:8080/solr/admin/cores?action=CREATE&collection=primary&name=primary_shard1_replica_2&shard=shard1'$ curl 'http://192.168.56.122:8080/solr/admin/cores?action=CREATE&collection=primary&name=primary_shard1_replica_3&shard=shard1'最后的结果是,192.168.56.123上的shard1,在192.168.56.121节点上有1个副本,名称为primary_shard1_replica_2,在192.168.56.122节点上有一个副本,名称为primary_shard1_replica_3。也可以通过查看192.168.56.121和192.168.56.122上的目录变化,如下所示:
$ ll /usr/local/solrhome/total 16drwxr-xr-x 3 root root 4096 Mar 10 17:11 primary_shard1_replica2drwxr-xr-x 3 root root 4096 Mar 10 17:02 primary_shard2_replica1-rw-r--r-- 1 root root 444 Mar 10 17:16 solr.xml你还可以对shard2和shard3添加副本。
我们再次从192.168.56.121节点可以看到,SOLR的配置文件内容,又发生了变化,如下所示:
<?xml version="1.0" encoding="UTF-8" ?><solr persistent="true" sharedLib="lib"> <cores adminPath="/admin/cores" zkClientTimeout="20000" hostPort="${jetty.port:8080}" hostContext="${hostContext:solr}"> <core shard="shard2" instanceDir="primary_shard2_replica1/" name="primary_shard2_replica1" collection="primary"/> <core shard="shard1" instanceDir="primary_shard1_replica2/" name="primary_shard1_replica_2" collection="primary"/> </cores></solr>到此为止,我们已经基于3个节点,配置完成了SolrCloud集群。最后效果如下:

8. 其他说明
8.1 SolrCloud的一些必要配置
schema.xml
必须定义_version_字段:
<field name="_version_" type="long" indexed="true" stored="true" multiValued="false"/>solrconfig.xml
updateHandler节点下需要定义updateLog:
<!-- Enables a transaction log, currently used for real-time get. "dir" - the target directory for transaction logs, defaults to the solr data directory. --> <updateLog> <str name="dir">${solr.data.dir:}</str> <!-- if you want to take control of the synchronization you may specify the syncLevel as one of the following where ''flush'' is the default. fsync will reduce throughput. <str name="syncLevel">flush|fsync|none</str> --> </updateLog>需要定义一个replication handler,名称为/replication:
<requestHandler name="/replication" class="solr.ReplicationHandler" startup="lazy" />需要定义一个realtime get handler,名称为/get:
<requestHandler name="/get" class="solr.RealTimeGetHandler"> <lst name="defaults"> <str name="omitHeader">true</str> </lst> </requestHandler>需要定义admin handlers:
<requestHandler name="/admin/" class="solr.admin.AdminHandlers" />需要定义updateRequestProcessorChain:
<updateRequestProcessorChain name="sample"> <processor class="solr.LogUpdateProcessorFactory" /> <processor class="solr.DistributedUpdateProcessorFactory"/> <processor class="solr.RunUpdateProcessorFactory" /> </updateRequestProcessorChain>solr.xml
cores节点需要定义adminPath属性:
<cores adminPath="/admin/cores"8.2 SolrCloud分布式检索时忽略宕机的Shard
<lst name=”error”> <str name=”msg”>no servers hosting shard:</str> <int name=”code”>503</int></lst>加入下面参数,只从存活的shards获取数据:
shards.tolerant=true 如:http://192.168.56.121:8080/solr/primary_shard2_replica1/select?q=*%3A*&wt=xml&indent=true&shards.tolerant=true
没有打此参数,如果集群内有挂掉的shard,将显示:
no servers hosting shard8.3 自动创建Collection及初始Shard
自动创建Collection及初始Shard,不需要通过zookeeper手动上传配置文件并关联collection。
1、在第一个节点修改tomcat启动参数
JAVA_OPTS='-Djetty.port=8080 -Dsolr.solr.home=/usr/local/solrhome -DzkHost=192.168.56.122:2181,192.168.56.122:2181,192.168.56.123:2181 -DnumShards=3 -Dbootstrap_confdir=/usr/local/solrhome/primary/conf -Dcollection.configName=primaryconf '然后启动tomcat。这个步骤上传了集群的相关配置信息(/usr/local/solrhome/primary/conf)到ZooKeeper中去,所以启动下一个节点时不用再指定配置文件了。
2、在第二个和第三个节点修改tomcat启动参数
JAVA_OPTS='-Djetty.port=8080 -Dsolr.solr.home=/usr/local/solrhome -DzkHost=192.168.56.122:2181,192.168.56.122:2181,192.168.56.123:2181 -DnumShards=3'然后启动tomcat。
这样就会创建3个shard分别分布在三个节点上,如果你在增加一个节点,这节点会附加到一个shard上成为一个replica,而不会创建新的shard。
9. 总结
本文记录了如何zookeeper、SolrCloud的安装和配置过程,solrcore是通过restapi进行手动创建,然后又对自动创建Collection及初始Shard进行了说明。
10. 参考文章
- [1] SolrCloud 4.3.1+Tomcat 7安装配置实践
- [2] SolrCloud Wiki
- [3] SolrCloud使用教程、原理介绍
- SolrCloud原理
- SolrCloud原理
- SolrCloud原理介绍
- SolrCloud原理介绍
- SolrCloud原理介绍 [
- SolrCloud原理介绍
- solrCloud的原理
- SolrCloud原理介绍
- SolrCloud原理介绍
- SolrCloud使用教程、原理介绍
- SolrCloud使用教程、原理介绍
- SolrCloud使用教程、原理介绍
- solrCloud..
- solrcloud
- SolrCloud
- SolrCloud
- solrCloud
- solrcloud
- HTML与XHTML区别比较
- 慎用create table as select,一定要注意默认值的问题---大一临时表方法
- PHP intval bcmul 方法变了
- Android开发之FastJson概述与简单使用
- 执行了getHibernateTemplate.save(user)后,控制台有hql语句输出,显示已经将数据存到数据库了,也没有抛出异常,但是去oracle数据库查的时候,压根就没有数据。。。。请问
- SolrCloud原理
- MyMFC(7-9)对话框 CPropSheet
- 11个实用的CSS学习工具
- 输出口和操作
- 有关linux系统登录出现启动会话失败
- [C++]数据结构:散列表(哈希表)、散列函数构造、处理散列冲突
- Android监听自身被卸载与反馈
- Jar 命令中Manifest.mf文件详解
- 360wifi设置接收wifi教程


