学习稀疏编码-day1
来源:互联网 发布:淘宝付费免费推广 编辑:程序博客网 时间:2024/05/16 08:35
1.稀疏编码(稀疏表示)基本概念
稀疏编码是一种无监督的学习。
目标:找到一组基向量 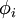 ,使得输入的向量X (x是n维的)能够用来表示。
,使得输入的向量X (x是n维的)能够用来表示。
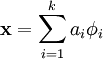
虽然PCA已经能够找出一组基向量,但是稀疏编码找的是一种超完备的基向量(K〉n),由而造成ai的值是不唯一确定的。所以需要另外加评价标准“稀疏性”,来解决因为超完备而退化。
这里的稀疏性针对的是系数ai是要稀疏的,只有很少的非0元素或者很少的远大于0的元素
我们把有 m 个输入向量的稀疏编码代价函数定义为:
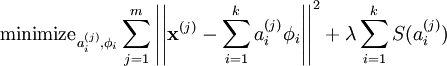
此处 S(.) 是一个稀疏代价函数,由它来对远大于零的 ai 进行“惩罚”。我们可以把稀疏编码目标函式的第一项解释为一个重构项,这一项迫使稀疏编码算法能为输入向量 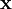 提供一个高拟合度的线性表达式,而公式第二项即“稀疏惩罚”项,它使 的表达式变得“稀疏”。常量 λ 是一个变换量,由它来控制这两项式子的相对重要性。
提供一个高拟合度的线性表达式,而公式第二项即“稀疏惩罚”项,它使 的表达式变得“稀疏”。常量 λ 是一个变换量,由它来控制这两项式子的相对重要性。
使用稀疏编码算法学习基向量集的方法,是由两个独立的优化过程组合起来的。第一个是逐个使用训练样本 来优化系数 ai ,第二个是一次性处理多个样本对基向量 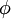 进行优化。
进行优化。
稀疏编码是有一个明显的局限性的,这就是即使已经学习得到一组基向量,如果为了对新的数据样本进行“编码”,我们必须再次执行优化过程来得到所需的系数。这个显著的“实时”消耗意味着,即使是在测试中,实现稀疏编码也需要高昂的计算成本,尤其是与典型的前馈结构算法相比。

0 0
- 学习稀疏编码-day1
- 字典学习和稀疏编码
- [转]字典学习/稀疏编码
- 深度学习模型---稀疏编码
- 稀疏编码学习总结(一)
- 深度学习之五:稀疏编码
- 深度学习(十二)稀疏自编码
- 深度学习模型、方法之稀疏编码
- 【机器学习】tensorflow: 稀疏自编码
- 关于稀疏编码和字典学习
- 深度学习:稀疏自编码MATLAB
- 稀疏编码
- 稀疏编码
- 稀疏编码
- 稀疏编码
- 稀疏编码
- 稀疏编码
- 稀疏编码
- 嵌入式面试题
- android权限大全
- Anroid 异常:is not valid; is your activity runnin
- cmd-----sql
- checkbox的attr(checked)一直为undefined问题
- 学习稀疏编码-day1
- jQuery源码分析-11 DOM遍历-Traversing-3个核心函数
- cocos2dx3.2 android 编译失败问题
- html包含css 和js
- 自定义控件三部曲之动画篇(一)——alpha、scale、translate、rotate、set的xml属性及用法
- Cocos2D-X弹出对话框的实现与封装
- 使用PowerShell更新SharePoint 2010 UserProfile Service的Property value
- 算法学习之选择排序算法(java)
- R语言 错误 Error in .jcall("RJavaTools", "Ljava/lang/Object;", "invokeMethod


