多维标度分析
来源:互联网 发布:eclipse如何写java 编辑:程序博客网 时间:2024/04/28 20:13
多维标度法(Multidimensional Scaling)是一种多维标度法是一类多元统计分析方法的总称,包含各种各样的模型和手段,其目的是通过各种途径把高维的研究对象转化成低维情形进行定位、分析和归类,同时又保留对象间的原始关系。同时也是一种可视化方法,实践中通常利用2D或3D的MDS 结果观察(投影后)点的分布和聚集来研究数据的性质。
具体地说,多维标度法是以多绍研究对象之间某种亲近关系为依据(如距离、相似系数,亲疏程度的分类情况等),合理地将研究对象(样品或变量)在低维空间中给出标度或位置,以便全面而又直观地再现原始各研究对象之间的关系,同时在此基础上也可按对象点之间距离的远近实现对样品的分类,多维标度法能弥补聚类分析的不足之处,因为聚类分析将相似的样品归类,最后得到一个反映样品亲疏关系的谱系图。聚类分析比较简便易行,但是,聚类分析的缺点是将一些高维的样品强行纳入一个一维的谱系分类中,常常使原始样品之间的关系简单化,甚至有时失真。而多维标度法是将几个高维研究对象,在近似的意义下,从高维约简到一个较低维的空间内,并且寻求一个最佳的空间维数和空间位置如2维或3维)而仍保持各研究对象数据的原始关系。
简单来说,MDS要处理的问题是:由n个指标(变量)反应的实体(entity),仅知它们之间的某种距离(相异度)或相似度,如何在较低维的流形中推测实体间的原始距离,以反映这n个实体的真实结构关系。也就是说,MDS利用的是成对样本间相似性,目的是利用这个信息去构建合适的低维空间,是的样本在此空间的距离和在高维空间中的样本间的相似性尽可能的保持一致。
MDS不是一个单独的方法,而是有相似思想的不同算法的集合。常用的MDS为距离标度(distance scaling),可以分为度量标度(包括经典标度和最小二乘标度等)和非度量标度。所谓计量数据,就是按间隔尺度或比例尺度测定的数据,也叫做定量数据;所谓非计量数据,就是按名义尺度或顺序尺度确定的数据,也叫做定性数据;因此多维标度法也分为计量的多维标度法和非计量的多维标度法。影响多维标度过程选择的另一因素,涉及分析过程是在单一个体水平进行还是在集合水平进行。空间图的解释能力、转折标准、统计方法及相关的知识常可帮助我们确定空间的维数。拟合度和紧缩值均可用来度量空间团对数据的拟合程度。
2、多维标度法的实施步骤
同具它的多元统计分析方法一样,对所研究的问题做出准确的界定、仍然是我们进行多维标度分析的首要好处,由于其中将应用各种类型的数据,我们就必须决定一种获得救据的适宜方式。并选择用于数据分析的具体过程。另外,还要确定空间的维数。通常,维数多,包含的信息量就大,而维数少,更为方便数据分析。因此,需要确定既能包含大部分重要信息,又方便数据分析的较为适当的维数。在确定了空间的维数以后,需要准确命名那些构筑空间的坐标轴,并对整个空间结构做出解释,最后一步的工作是砰估所用方法的可靠性和有效性。
3. 具体算法
MDS方法有5个关键的要素,分别为主体、客体、准则、准则权重、主体权重。具体定义为:
1)客体:被评估的对象。可以认为是待分类的几种类别,数量M。
2)主体:评估客体的单位。就是训练数据。N个
3)准则:根据研究目的自行定义,用以评估客体优劣的标准。K个
4)准则权重:主体衡量准则重要性后,对每个准则分别赋予权重值。P个
5)主体权重:研究者权衡准则重要性后,对主体赋予权重值。N个
对于要分析的数据包括I个物体,定义一个距离函数的集合,其中δi,j是第i个和第j个对象之间的距离。于是有

MDS算法的目的就是根据这个Δ,寻找I个向量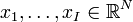 ,使
,使 ,对于i,j属于I。这里这个||.||是向量的范数,在经典的MDS,该规范是欧氏距离,但广义的讲,这个规范可以是任意函数。
,对于i,j属于I。这里这个||.||是向量的范数,在经典的MDS,该规范是欧氏距离,但广义的讲,这个规范可以是任意函数。
也就是说,MDS试图找到一个子空间Rn,I个物体嵌入在这个子空间中,而彼此的相似度被尽可能的保留。如果这个子空间的维数N选择为2或者3,可以画出向量xj获得一个I个物体相似性的一个可视化的结果。注意向量xj不是唯一的:对于欧式距离,可以被任意旋转和变换,因为这些变换不会改变样本间的距离。
有很多途径可以得到向量xj。通常MDS可以被看做是一个优化问题,寻找(x1,...xI)被看成是最小化目标函数,例如

可以利用一些数值优化的方法得到这个最优解。
基本的MDS算法:设X[1],…,X[n]为p维空间上的n个点,其两两距离(相异度)为δ[i,j]。相异度可以是定量的(如物理距离或比例),此时对应度量标度(metric scaling),也可以是定性的(如感觉或偏好的排序),此时对应非度量标度(nonmetric scaling)。
度量标度要寻找t维空间上(t<p)的一个n点结构Y[1],…,Y[n],这称为MDS的一个解,其内点距离为d[i,j],使得δ[i,j]和d[i,j]近似相等。即存在一个单调函数f,使d[i,j]≈f(δ[i,j])。
寻找函数f的方法是极小化压力函数:

这样得到的解称为最小二乘标度。
当采用欧氏距离且f为恒等函数时,经典标度可视为最小二乘标度的一个特殊情况。但一般情形下两者并不相同,经典标度常用的解法是特征值分解。当采用中心化的内积计算邻近矩阵时,经典标度和主成分是相等的。
最小二乘标度的一个变种,选取一种特殊权重的加权最小二乘标度,称为sammon mapping。
它强调保护较小的距离,在判别内点结构聚集的时候更有用。
非度量标度只使用次序。它要寻找一个保持单调性的函数f,使得投影之后的内点距离d[i,j]保持原p维空间各点的相异度的排序。因此,压力函数要做相应的变化:常用的解法是保序回归(isotonic regression)。
在优化算法上,传统的MDS优化都是基于梯度的算法。较新的优化方法也逐步采用,比如
SMACOF,采用优化控制不等式的majorixation algorithm来最小化压力函数。
4.MDS和其他方法的联系。在统计上,MDS和主成分分析,对应分析和典型相关分析具有内在的一致性,可以统一在Gifi System 这一框架下。
从算法的角度,MDS和MDS方法和自组织映射(SOM)以及主曲线主曲面方法有着相似的目标,同时它也启发了非线性流形学习。
5. Matlab实现
Multidimensional Scaling作为一种经典的数据降维方法,在matlab的toolbox中(Statistics)已得到很好地实现,函数的名称为mdscale,具体实现代码见mdscale.m文件。
几个关键函数为
pdist:计算对象之间的两两距离。
D=pdist(X,distance). 其中X为m*n的矩阵。m为不同的观察值,n为不同的变量。则D为m(m-1)/2的列向量。其中distance默认是酉氏距离,也可以是其中各种常见类型的距离:seuclidean,cityblock,minkowski,chebychev,mahalanobis,cosine,correlation,spearman,hamming,jaccard,或自定义的距离类型。
squareform(D):可以借助于该函数将D转变为方阵,比如 squareform(y) = X 或squareform(X) = y.则
y = 1 2 3 4 5 6
X = [0 1 2 3; 1 0 4 5; 2 4 0 6; 3 5 6 0]
cmdscale:经典MDS
mdscale:非经典MDS
Y1 = mdscale(D, 2, ‘criterion’,'metricstress’);
其中2表示维度,metricstress表示一种降维准则。
Y2 = mdscale(D,2, ‘criterion’,'sammon’);
non-metric MDS试图通过点与点之间距离的单调映射(monotonic transformation)来近似原有的距离。实际应用中,较大的点间距离对应着较大的非相似性,反之亦然。很多情况下,这样就足以表现研究对象之间的相互关系。
依然是应用mdscale函数,将dissimilarities矩阵作为输入,映射到二维空间,并使用Kruskal的non-metric stress准则函数,也是mdscale的默认值:
[Y,stress,disparities] = mdscale(dissimilarities,2);
- 多维标度分析
- 多维标度分析
- 用java写MDS多维标度分析(multidimensional scaling )
- MATLAB中的多维标度变换
- 多维标度法(MDS)的Python实现
- 多维交叉分析
- 多维交叉分析
- 多维尺度分析 MDS
- 多维偏好分析
- MDS多维尺度分析
- 【多维分析系列】拥抱大数据多维分析查询
- OLAP的多维数据分析
- OLAP及其多维数据分析
- Pentaho Mondrian OLAP多维分析
- 可视化与多维数据分析
- 网站多维度指标分析
- 标度差值图像
- 使用MDX实现多维关联分析
- 阅读笔记:《浪潮之巅》上册
- 海通PEHUB技术支持
- 数据结构课程设计
- <数据结构> ——迟来的课程设计__04
- 云南旅游最美景点20强最新排名
- 多维标度分析
- 继承
- Java注解教程和自定义注解
- 机器学习-决策树
- 安卓数据存储之sharedpreferences
- eclipse c++ : `pthread_create 未定义
- 数据结构课程设计
- 清除UITableView底部多余的分割线
- 扩展ExpandableListView,支持浮动标题


