Deep Learning L教程(六)
来源:互联网 发布:xampp mysql 密码 编辑:程序博客网 时间:2024/04/29 20:52
本文转自深度学习论坛
稀疏自编码器符号一览表
下面是我们在推导sparse autoencoder时使用的符号一览表:
符号含义 训练样本的输入特征,
训练样本的输入特征,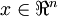 .
.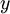 输出值/目标值. 这里 可以是向量. 在autoencoder中,
输出值/目标值. 这里 可以是向量. 在autoencoder中, .
.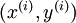 第
第  个训练样本
个训练样本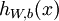 输入为 时的假设输出,其中包含参数
输入为 时的假设输出,其中包含参数 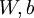 . 该输出应当与目标值 具有相同的维数.
. 该输出应当与目标值 具有相同的维数.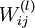 连接第
连接第 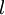 层
层  单元和第
单元和第 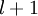 层 单元的参数.
层 单元的参数.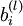 第 层 单元的偏置项. 也可以看作是连接第 层偏置单元和第 层 单元的参数.
第 层 单元的偏置项. 也可以看作是连接第 层偏置单元和第 层 单元的参数.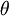 参数向量. 可以认为该向量是通过将参数 组合展开为一个长的列向量而得到.
参数向量. 可以认为该向量是通过将参数 组合展开为一个长的列向量而得到.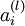 网络中第 层 单元的激活(输出)值.
网络中第 层 单元的激活(输出)值.另外,由于 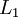 层是输入层,所以
层是输入层,所以 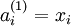 .
.
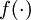 激活函数. 本文中我们使用
激活函数. 本文中我们使用 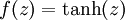 .
.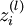 第 层 单元所有输入的加权和. 因此有
第 层 单元所有输入的加权和. 因此有 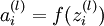 .
.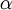 学习率
学习率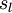 第 层的单元数目(不包含偏置单元).
第 层的单元数目(不包含偏置单元).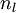 网络中的层数. 通常 层是输入层,
网络中的层数. 通常 层是输入层,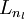 层是输出层.
层是输出层.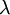 权重衰减系数.
权重衰减系数.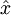 对于一个autoencoder,该符号表示其输出值;亦即输入值 的重构值. 与 含义相同.
对于一个autoencoder,该符号表示其输出值;亦即输入值 的重构值. 与 含义相同.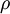 稀疏值,可以用它指定我们所需的稀疏程度
稀疏值,可以用它指定我们所需的稀疏程度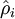 (sparse autoencoder中)隐藏单元 的平均激活值.
(sparse autoencoder中)隐藏单元 的平均激活值.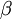 (sparse autoencoder目标函数中)稀疏值惩罚项的权重.
(sparse autoencoder目标函数中)稀疏值惩罚项的权重.中文译者
邵杰(jiesh@hotmail.com),许利杰(csxulijie@gmail.com),余凯(kai.yu.cool@gmail.com)
0 0
- Deep Learning L教程(六)
- Deep Learning L教程(二)
- Deep Learning L教程(三)
- Deep Learning L教程(四)
- Deep Learning L教程(五)
- Deep Learning L教程(矢量化编程)(一)
- Deep Learning L教程(斯坦福深度学习研究团队)(一)
- Deep Learning L教程(矢量化编程实现)(二)
- Deep Learning L教程(矢量化编程实现)(三)
- Udacity Deep Learning课程作业(六)
- Deep Learning:正则化(六)
- deep learning Softmax分类器(L-BFGS,CG,SD)
- Deep Learning 教程翻译
- Deep Learning 教程翻译
- Deep Learning:UFLDL教程
- Deep Learning 实战教程
- Deep Learning 教程翻译
- Deep Learning 教程翻译
- java语言中的Calendar
- A man speaks truth 3 out of 4 times. He throws a die and reports it to be a 6. What is the probabili
- Java 日期总结
- 高分辨率影像卫星之美国
- 【设计模式】C#基础知识积累
- Deep Learning L教程(六)
- ClassLoade学习记录
- 在Myeclipse2013、2014中去除Derby
- 内核编译之模块验证失败和手动模块签名
- 工作和技术深入的矛盾
- 向Android手机中插入一条短信 及联系人获取
- Remove Duplicates from Sorted Array
- Android 触摸事件传递流程解析
- 网球之费德勒


