Scrapy研究探索2
来源:互联网 发布:java的日志框架 编辑:程序博客网 时间:2024/04/30 08:21
转载自:http://blog.csdn.net/u012150179/article/details/34441655
一. 核心架构
关于核心架构,在官方文档中阐述的非常清晰,地址:http://doc.scrapy.org/en/latest/topics/architecture.html。
英文有障碍可查看中文翻译文档,笔者也参与了Scraoy部分文档的翻译,我的翻译GitHub地址:https://github.com/younghz/scrapy_doc_chs。源repo地址:https://github.com/marchtea/scrapy_doc_chs。
下面就直接转载部分文档(地址:http://scrapy-chs.readthedocs.org/zh_CN/latest/topics/architecture.html):
概述
接下来的图表展现了Scrapy的架构,包括组件及在系统中发生的数据流的概览(绿色箭头所示)。 下面对每个组件都做了简单介绍,并给出了详细内容的链接。数据流如下所描述。
Scrapy architecture
组件
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
调度器(Scheduler)
调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
下载器(Downloader)
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。 每个spider负责处理一个特定(或一些)网站。 更多内容请看 Spiders 。
Item Pipeline
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。 更多内容查看 Item Pipeline 。
下载器中间件(Downloader middlewares)
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 下载器中间件(Downloader Middleware) 。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子(specific hook),处理spider的输入(response)和输出(items及requests)。 其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。更多内容请看 Spider中间件(Middleware) 。
数据流(Data flow)
Scrapy中的数据流由执行引擎控制,其过程如下:
1.引擎打开一个网站(open a domain),找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
2.引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
3.引擎向调度器请求下一个要爬取的URL。
4.调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
5.一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
6.引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
7.Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
8.引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
9.(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
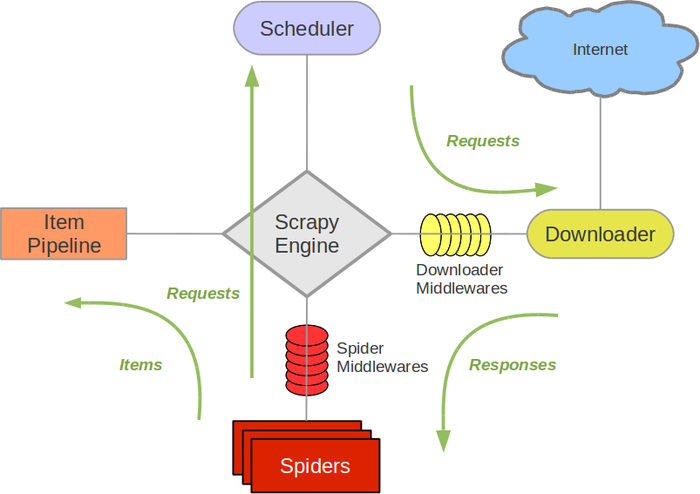
二. 数据流与代码运行分析
这里主要分析数据流部分并与代码结合起来。与上面的流程1-9对应。
(1)找spider——在spider文件夹下查找相关定义爬虫文件
(2)引擎获取URL——自定义spider中start_urls列表中获取
(3)...
(4)...
(5)通过(3)(4)(5)就在内部实现了根据URL生成request,下载器根据request生成response这个过程。即URL-》request-》reponse。
(6)...
(7)在自定义spider中调用默认的parse()方法或是制定的parse_*()方法处理接收到的reponse,处理的结果很重要:
第一个,抽取item值。
第二个,如果需要继续爬取,这里会返回request给引擎。(这是“自动”爬取多个网页的关键)。
(8)(9)引擎继续调度,直至无request。
进阶:
Scrapy架构呈现星型拓扑结构,“引擎”作为整个架构的核心协调、控制整个系统的运行。
- Scrapy研究探索2
- scrapy研究探索1
- Scrapy研究探索3
- Scrapy研究探索(一)——基础入门
- Scrapy研究探索(一)——基础入门
- Scrapy研究探索(三)——Scrapy核心架构与代码运行分析
- Scrapy研究探索(三)——Scrapy核心架构与代码运行分析
- scrapy研究探索(二)——爬w3school.com.cn
- Scrapy研究探索(四)——中文输出与中文保存
- Scrapy研究探索(六)——自动爬取网页之II(CrawlSpider)
- Scrapy研究探索(七)——如何防止被ban之策略大集合
- Scrapy研究探索(七)——如何防止被ban之策略大集合
- scrapy研究探索(二)——爬w3school.com.cn
- Scrapy研究探索(七)——如何防止被ban之策略大集合
- Scrapy研究探索(六)——自动爬取网页之II(CrawlSpider)
- scrapy研究探索(二)——爬w3school.com.cn
- Scrapy研究探索(四)——中文输出与中文保存
- Scrapy研究探索(六)——自动爬取网页之II(CrawlSpider)
- iOS中的崩溃类型
- 程序猿的简历一
- 使用Qt / C + +通过JNI调用Java代码
- spring 之自动代理
- 省市区 【构建对象】转换成json
- Scrapy研究探索2
- 使用Volley中遇到一些的问题
- [定义] Precision Recall F1 Accuracy
- ArcGIS Engine中 IGeometry和Json字符串的相互转换
- Object-C Runtime机制
- 程序猿的简历二
- 【源码剖析】tornado-memcached-sessions —— Tornado session 支持的实现(一)
- 常用保存状态指令
- Android中TextView自动换行问题


