java的xml学习[JDOM方式解析XML文档]
来源:互联网 发布:千里眼淘宝插件手机版 编辑:程序博客网 时间:2024/04/30 08:26
JDOM方式解析XML文档不是JAVA官方提供的,因此我们需要额外导入jar包,jdom的jar包的下载地址可以到JDOM的官方网站上下载。
下载后解压得到如下所示的文件:

我们通过以下的步骤将jar包导入到我们的项目中(在项目中点击右键Build Path->Add External Archives-jdom-2.0.5.jar):


以上步骤执行完成以后在我们的项目中会多一个Referenced Libraries,见下图:
此时我们需要的jar包已经导入了我们的项目中。接下来就可以开始编写程序了。
JDOM方式解析XML文件一般需要以下3个步骤:
1. 创建一个SAXBuilder对象;
2. 创建一个输入流,将XML文件加载到输入流;
3. 通过SAXBuilder的build(InputStream in)方法将输入流加载到SAXBuilder中。
以下是其简单实现:
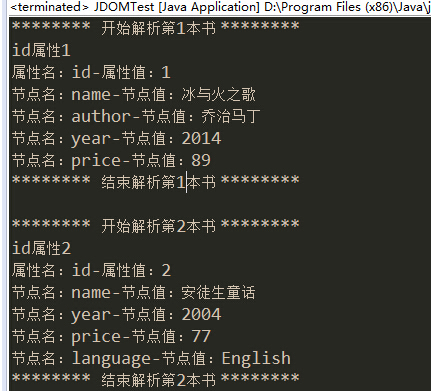
import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.IOException;import java.io.InputStream; import java.util.List; import org.jdom2.Attribute;import org.jdom2.Document;import org.jdom2.Element;import org.jdom2.JDOMException;import org.jdom2.input.SAXBuilder; public class JDOMTest { public static void main(String[] args) { // 1.创建一个SAXBuilder对象 SAXBuilder saxBuilder = new SAXBuilder(); InputStream in; try { // 2.创建一个输入流,将xml文件加载到输入流 in = new FileInputStream("books.xml"); // 3.通过SAXBuilder的build方法将输入流加载到SAXBuilder中 Document document = saxBuilder.build(in); // 4.通过Document对象获取xml文件的根节点 Element rootElement = document.getRootElement(); // 5.根据根节点获取子节点的List集合 List<Element> bookList = rootElement.getChildren(); // 使用循环对bookList进行遍历 for (Element book : bookList) { System.out.println("******** 开始解析第" + (bookList.indexOf(book) + 1) + "本书 ********"); // 解析book的属性 // 知道节点的属性名的时候获取属性值 System.out.println("id属性" + book.getAttributeValue("id")); // 不知道属性的个数和属性名的时候 List<Attribute> attrList = book.getAttributes(); // 遍历book的属性集合 for (Attribute attribute : attrList) { System.out.println("属性名:" + attribute.getName() + " -属性值:"+ attribute.getValue()); } // 对book节点的子节点的节点名和节点值进行遍历 List<Element> bookChilds = book.getChildren(); for (Element child : bookChilds) { System.out.println("节点名:" + child.getName() + "-节点 值:"+ child.getValue()); } System.out.println("******** 结束解析第" + (bookList.indexOf(book) + 1) + "本书 ********\n"); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (JDOMException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }}运行结果:
在JDOM中我们要想将XML文档中的数据保存至JAVA对象也是十分简单:当我们遍历每一个book标签的时候创建一个Book对象,当我们遇到属性节点或者只包含文本的简单元素节点的时候的时候,调用setter方法为Book对象赋值,结束遍历一本书的时候将其加入到ArrayList中即可:
import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.IOException;import java.io.InputStream; import java.util.ArrayList;import java.util.List; import org.jdom2.Attribute;import org.jdom2.Document;import org.jdom2.Element;import org.jdom2.JDOMException;import org.jdom2.input.SAXBuilder; import org.xml.parser.Book; public class JDOMTest { private static ArrayList<Book> booksList = new ArrayList<Book>(); public static void main(String[] args) { // 1.创建一个SAXBuilder对象 SAXBuilder saxBuilder = new SAXBuilder(); InputStream in; try { // 2.创建一个输入流,将xml文件加载到输入流 in = new FileInputStream("books1.xml"); // 3.通过SAXBuilder的build方法将输入流加载到SAXBuilder中 Document document = saxBuilder.build(in); // 4.通过Document对象获取xml文件的根节点 Element rootElement = document.getRootElement(); // 5.根据根节点获取子节点的List集合 List<Element> bookList = rootElement.getChildren(); // 使用循环对bookList进行遍历 for (Element book : bookList) { Book bookEntity = new Book(); // 不知道属性的个数和属性名的时候 List<Attribute> attrList = book.getAttributes(); // 遍历book的属性集合 for (Attribute attribute : attrList) { if ("id".equals(attribute.getName())) { bookEntity.setId(attribute.getValue()); } } // 对book节点的子节点的节点名和节点值进行遍历 List<Element> bookChilds = book.getChildren(); for (Element child : bookChilds) { if ("name".equals(child.getName())) { bookEntity.setName(child.getValue()); } else if ("author".equals(child.getName())) { bookEntity.setAuthor((child.getValue())); } else if ("year".equals(child.getName())) { bookEntity.setYear((child.getValue())); } else if ("price".equals(child.getName())) { bookEntity.setPrice(child.getValue()); } else if ("language".equals(child.getValue())) { bookEntity.setLanguage(child.getValue()); } } booksList.add(bookEntity); } System.out.println("ArrayList中一共有" + booksList.size() + "本书!"); for (Book b : booksList) { System.out.println(b); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (JDOMException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }}运行结果:

【关于解析过程中乱码的解决】
在javaIO中我们了解到乱码的产生一般是因为字符集的不匹配造成的。例如我们将XML文档的encoding属性改为不支持中文编码的iso-8859-1编码,再运行程序就会产生乱码:

针对乱码的解决方案通常有两种:
1. 将XML文件的编码(encoding属性)改为支持中文的某种编码,例如:GBK、UTF-8、GB2312;
2. 如果我们不便于修改XML文档的encoding属性,可以用InputstreamReader包装InputStream然后将其传入SAXBuilder的build(InputStream in)方法。实现如下:
将以上代码的步骤2、3改为如下代码:
// 2.创建一个输入流,将xml文件加载到输入流 in = new FileInputStream("books.xml"); InputStreamReader isr = new InputStreamReader(in,"utf-8");//用InputStreamReader包装InputStream并指定字符集 // 3.通过SAXBuilder的build方法将输入流加载到SAXBuilder中 Document document = saxBuilder.build(isr);【关于jar包的引用】
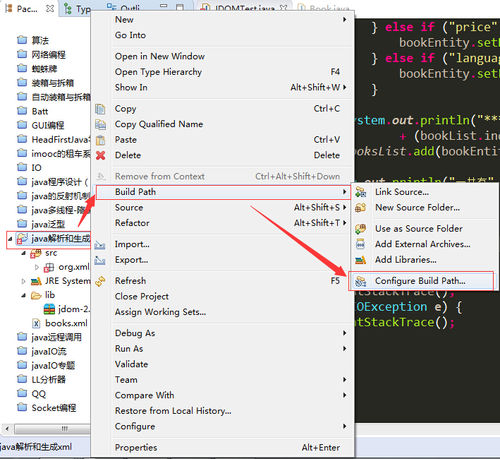
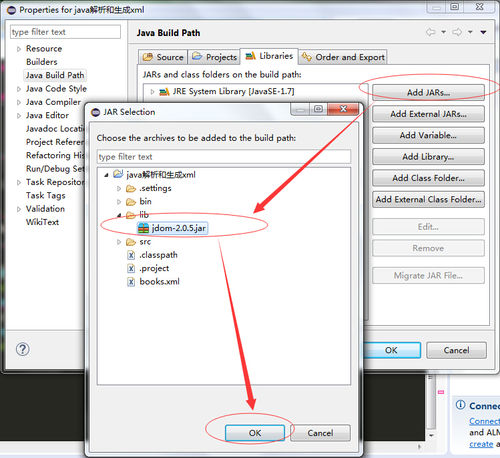
楼上的帖子中,上述jar包的导入实际上并没有真正将jar文件copy到我们的项目中(仅仅是在项目中添加了一个到jar文件的引用),这样可能带来一个问题:当我们在进行项目的导入导出的时候,由于jar文件并没有随之导入导出,我们将项目迁移至另一台电脑的时候就会因为缺少jar文件而导致代码出错。比较好的做法是:在项目中新建一个目录专门用于存放我们的jar文件,然后再将此jar文件Build Path,如下图所示:
或者使用下面的步骤一次完成:

- java的xml学习[JDOM方式解析XML文档]
- java的xml学习[DOM4J方式解析XML文档]
- jdom解析xml文档
- jdom解析xml文档
- JDOM解析XML文档
- Jdom解析XML文档
- jdom解析xml文档
- java解析xml的几种方式 JDOM解析
- java操作xml文档(三) JDOM方式
- Java之JDOM方式解析XML文件(学习笔记)
- JAVA 解析XML之JDOM、DOM4J方式
- 解析XML文档方式之三:jdom方式
- 解析XML的方式之JDOM
- java与xml之JDOM生成和解析XML文档
- java与xml之JDOM生成和解析XML文档
- java jdom 解析xml
- JAVA jdom 解析 xml
- JAVA JDom解析XML
- VC++ 声音处理
- 关于IOS开发是用xib/storyboard还是纯代码开发
- unix环境高级编程——库函数的缓冲区
- 使用Python的元类实现AOP监控类方法调用过程
- RFID作业(第三次)
- java的xml学习[JDOM方式解析XML文档]
- leetCode | Add Two Numbers
- STM32Fxx系列CAN总线配置总结
- Java获取本机ip的方法
- LeetCode(034) Search For a Range (Java)
- Linux下使用Shell脚本实现ftp的自动上传下
- 即时通信之Bmob开发11
- 二分查找法
- Android Settings(系统设置)源码分析(一)


