java的xml学习[DOM4J方式解析XML文档]
来源:互联网 发布:矩阵a 4 1 2 编辑:程序博客网 时间:2024/04/29 06:34
使用这种方式解析XML文档可以分为两步:
1. 创建一个SAXReader对象reader;
2. 通过reader对象的read方法加载xml文件,获取Document对象。
首先从其dom4j官方网站下载dom4j-1.6.1.zip,解压得到如下文件:
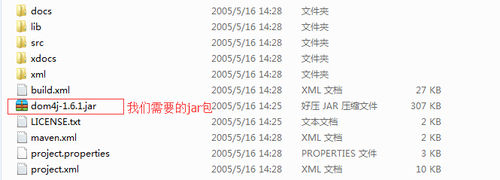
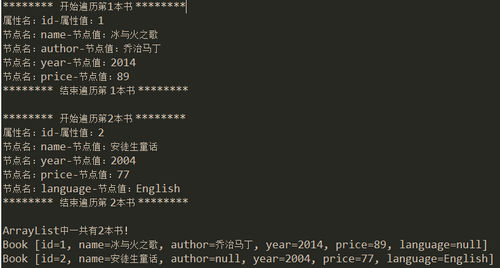
在我们的项目中建立一个lib目录,将dom4j-1.6.1.jar拷贝至该目录,按照前面的方法Build Path。实现如下(解析的时候将XML文档中的数据输出到控制台并保存book对象到ArrayList中):
import java.io.File;import java.util.ArrayList;import java.util.Iterator;import java.util.List; import org.dom4j.Attribute;import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.Element;import org.dom4j.io.SAXReader;import org.xml.parser.Book; public class DOM4JTest { private static int bookIndex = 0; private static Book b = null; private static ArrayList<Book> bookList = new ArrayList<Book>(); public static void main(String[] args) { dom4jParser(); } public static void dom4jParser() { // 1.创建一个SAXReader对象reader SAXReader reader = new SAXReader(); try { // 2.通过reader对象的read方法加载xml文件,获取Document对象 Document document = reader.read(new File("books.xml")); Element bookStore = document.getRootElement();// 通过document对象获取根节点bookstore // 获取根节点的子节点的相关信息 Iterator iterator = bookStore.elementIterator();// 通过Element对象的elementIterator方法获取迭代器 // 遍历迭代器,获取bookstore中的节点(book) while (iterator.hasNext()) { bookIndex++; System.out .println("******** 开始遍历第" + bookIndex + "本书 ********"); b = new Book(); Element book = (Element) iterator.next(); // 获取book的属性名和属性值 List<Attribute> bookAttrs = book.attributes(); for (Attribute attribute : bookAttrs) { System.out.println("属性名:" + attribute.getName() + "-属性值:" + attribute.getValue()); if ("id".equals(attribute.getName())) { b.setId(attribute.getValue()); } } // 获取book的子节点 Iterator it = book.elementIterator(); while (it.hasNext()) { Element bookChild = (Element) it.next(); System.out.println("节点名:" + bookChild.getName() + "-节点值:" + bookChild.getStringValue()); if ("name".equals(bookChild.getName())) { b.setName(bookChild.getStringValue()); } else if ("author".equals(bookChild.getName())) { b.setAuthor(bookChild.getStringValue()); } else if ("year".equals(bookChild.getName())) { b.setYear(bookChild.getStringValue()); } else if ("price".equals(bookChild.getName())) { b.setPrice(bookChild.getStringValue()); } else if ("language".equals(bookChild.getName())) { b.setLanguage(bookChild.getStringValue()); } } bookList.add(b); // 将book对象添加到bookList集合中 System.out.println("******** 结束遍历第 " + bookIndex + "本书 ********\n"); } // 输出ArrayList中的book System.out.println("ArrayList中一共有" + bookList.size() + "本书!"); for (Book book : bookList) { System.out.println(book); } } catch (DocumentException e) { e.printStackTrace(); } }}运行结果:
【4种XML解析方式的比较】

其中DOM是W3C官方提供的解析方式,是一种文档驱动的解析方式,将XML文件整个加载到内存,形成一颗文档树(Document Tree)。是一种官方的标准,仅仅是在Java中使用,在其他编程语言,例如Javascript、ASP.NET中也有相关的对XML DOM的支持。SAX解析是一种最快的解析方式,广泛应用于资源有限的环境,例如:Android提供SAX方式解析XML文档;DOM4J方式是非常优秀的Java XML API,java的SSH框架中Hibernate就是使用这种方式解析的XML,是比较推荐的一种解析方式。
下面通过一段代码来测试4种方式解析XML的性能差异:
首先新建一个JUnit:在项目中右键Build Path->Add Libraries->JUint->next->JUnit4-finish。
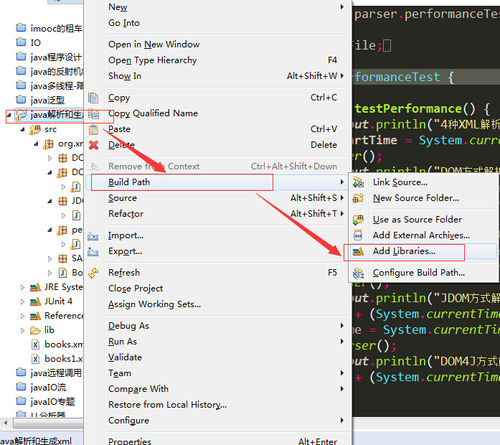
完成后会出现如下:
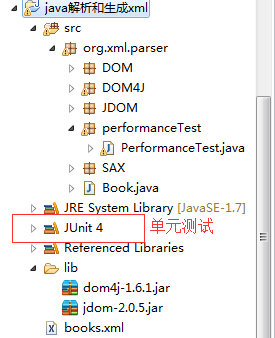
将以上4种解析XML文件的方式整合到一个类中(这里要注意一点,因为org.dom4j.Document与org.w3c.dom.Document等等他们是相同的类但是属于不同的包,我们不可能将两个一起导入,所以有一些需要使用完成的类名【包名.类名的形式】),我们在每种方法解析开始的时候获取系统的时间(long类型的毫秒数),在每种方法解析结束的时候再获取系统时间,就可以得到该方法解析所花费的时间(注意:在本测试程序中针对每一种解析方式,我们仅仅读取XML文件中的数据并保存至Java对象,为了便于区分各种解析方式的差异,我们将books.xml拓展至12,3267行(2.59MB))。测试方法需要使用@Test Annotation(@Test表示这个方法是JUnit测试时候会运行的)
import java.io.File;import java.io.FileInputStream;import java.io.FileNotFoundException;import java.io.IOException;import java.io.InputStream;import java.util.ArrayList;import java.util.Iterator;import java.util.List; import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.parsers.ParserConfigurationException;import javax.xml.parsers.SAXParser;import javax.xml.parsers.SAXParserFactory; import org.dom4j.DocumentException;import org.dom4j.io.SAXReader;import org.jdom2.Attribute;import org.jdom2.Element;import org.jdom2.JDOMException;import org.jdom2.input.SAXBuilder;import org.junit.Test;import org.w3c.dom.Document;import org.w3c.dom.NamedNodeMap;import org.w3c.dom.Node;import org.w3c.dom.NodeList;import org.xml.parser.Book;import org.xml.parser.SAX.SAXParserHandler;import org.xml.sax.SAXException; public class PerformanceTest { @Test public void testPerformance() { System.out.println("4种XML解析方式的性能比较(针对books.xml解析):"); long startTime = System.currentTimeMillis(); domParser(); System.out.println("DOM方式解析耗时:\t" + (System.currentTimeMillis() - startTime) + "ms"); startTime = System.currentTimeMillis(); saxParser(); System.out.println("SAX方式解析耗时:\t" + (System.currentTimeMillis() - startTime) + "ms"); startTime = System.currentTimeMillis(); jdomParser(); System.out.println("JDOM方式解析耗时:\t" + (System.currentTimeMillis() - startTime) + "ms"); startTime = System.currentTimeMillis(); dom4jParser(); System.out.println("DOM4J方式解析耗时:\t" + (System.currentTimeMillis() - startTime) + "ms"); } public static void domParser() { Book book = null; ArrayList<Book> books = new ArrayList<Book>(); DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance(); try { DocumentBuilder db = dbf.newDocumentBuilder(); Document document = db.parse("books.xml"); NodeList bookList = document.getElementsByTagName("book"); for (int i = 0; i < bookList.getLength(); i++) { book = new Book(); Node bookNode = (Node) bookList.item(i); NamedNodeMap attributes = bookNode.getAttributes(); // 遍历book节点的属性 for (int j = 0; j < attributes.getLength(); j++) { Node attribute = attributes.item(j); if ("id".equals(attribute.getNodeName())) { book.setId(attribute.getNodeValue()); } } // 解析book节点的子节点 NodeList childNodes = bookNode.getChildNodes(); // 遍历childNodes获取每个节点的节点名和节点值 for (int j = 0; j < childNodes.getLength(); j++) { // 区分textNode和elementNode if (childNodes.item(j).getNodeType() == Node.ELEMENT_NODE) { if ("name".equals(childNodes.item(j).getNodeName())) { book.setName(childNodes.item(j).getFirstChild() .getNodeValue()); } else if ("author".equals(childNodes.item(j) .getNodeName())) { book.setAuthor(childNodes.item(j).getTextContent()); } else if ("year".equals(childNodes.item(j) .getNodeName())) { book.setYear(childNodes.item(j).getTextContent()); } else if ("price".equals(childNodes.item(j) .getNodeName())) { book.setPrice(childNodes.item(j).getTextContent()); } else if ("language".equals(childNodes.item(j) .getNodeName())) { book.setLanguage(childNodes.item(j) .getTextContent()); } } } books.add(book);// 结束一本书的遍历的时候将其加入ArrayList中 } } catch (ParserConfigurationException e) { e.printStackTrace(); } catch (SAXException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } public static void saxParser() { // 1.获取一个SAXParserFactory的实例 SAXParserFactory factory = SAXParserFactory.newInstance(); try { // 2.通过factory获取SAXParser实例 SAXParser parser = factory.newSAXParser(); // 3.创建一个SAXParserHandler对象 SAXParserHandler handler = new SAXParserHandler(); // 4.通过SAXParser对象的parse(String uri,DefaultHandler dh)方法解析xml文件 parser.parse("books.xml", handler); /* 将XML文件中的数据保存在Book对象中并将对象添加到ArrayList中,遍历ArrayList */ ArrayList<Book> books = handler.getBookList(); } catch (ParserConfigurationException e) { e.printStackTrace(); } catch (SAXException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } public static void jdomParser() { ArrayList<Book> booksList = new ArrayList<Book>(); // 1.创建一个SAXBuilder对象 SAXBuilder saxBuilder = new SAXBuilder(); InputStream in; try { // 2.创建一个输入流,将xml文件加载到输入流 in = new FileInputStream("books.xml"); // 3.通过SAXBuilder的build方法将输入流加载到SAXBuilder中 org.jdom2.Document document = saxBuilder.build(in); // 4.通过Document对象获取xml文件的根节点 Element rootElement = document.getRootElement(); // 5.根据根节点获取子节点的List集合 List<Element> bookList = rootElement.getChildren(); // 使用循环对bookList进行遍历 for (Element book : bookList) { Book bookEntity = new Book(); // 不知道属性的个数和属性名的时候 List<Attribute> attrList = book.getAttributes(); // 遍历book的属性集合 for (Attribute attribute : attrList) { if ("id".equals(attribute.getName())) { bookEntity.setId(attribute.getValue()); } } // 对book节点的子节点的节点名和节点值进行遍历 List<Element> bookChilds = book.getChildren(); for (Element child : bookChilds) { if ("name".equals(child.getName())) { bookEntity.setName(child.getValue()); } else if ("author".equals(child.getName())) { bookEntity.setAuthor((child.getValue())); } else if ("year".equals(child.getName())) { bookEntity.setYear((child.getValue())); } else if ("price".equals(child.getName())) { bookEntity.setPrice(child.getValue()); } else if ("language".equals(child.getValue())) { bookEntity.setLanguage(child.getValue()); } } booksList.add(bookEntity); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (JDOMException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } } public static void dom4jParser() { ArrayList<Book> bookList = new ArrayList<Book>(); Book b = null; // 1.创建一个SAXReader对象reader SAXReader reader = new SAXReader(); try { // 2.通过reader对象的read方法加载xml文件,获取Document对象 org.dom4j.Document document = reader.read(new File("books.xml")); org.dom4j.Element bookStore = document.getRootElement(); // 获取根节点的子节点的相关信息 Iterator iterator = bookStore.elementIterator(); // 遍历迭代器,获取bookstore中的节点(book) while (iterator.hasNext()) { b = new Book(); org.dom4j.Element book = (org.dom4j.Element) iterator.next(); // 获取book的属性名和属性值 List<org.dom4j.Attribute> bookAttrs = book.attributes(); for (org.dom4j.Attribute attribute : bookAttrs) { if ("id".equals(attribute.getName())) { b.setId(attribute.getValue()); } } // 获取book的子节点 Iterator it = book.elementIterator(); while (it.hasNext()) { org.dom4j.Element bookChild = (org.dom4j.Element) it.next(); if ("name".equals(bookChild.getName())) { b.setName(bookChild.getStringValue()); } else if ("author".equals(bookChild.getName())) { b.setAuthor(bookChild.getStringValue()); } else if ("year".equals(bookChild.getName())) { b.setYear(bookChild.getStringValue()); } else if ("price".equals(bookChild.getName())) { b.setPrice(bookChild.getStringValue()); } else if ("language".equals(bookChild.getName())) { b.setLanguage(bookChild.getStringValue()); } } bookList.add(b); // 将book对象添加到bookList集合中 } } catch (DocumentException e) { e.printStackTrace(); } }}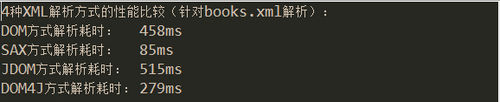
SAX解析的性能是最高的,然后是DOM4J解析,最后是DOM解析和JDOM解析,在实际应用中我们一般采用DOM4J的方式进行XML的解析。
- java的xml学习[DOM4J方式解析XML文档]
- JAVA DOM4j解析XML文档
- java的xml学习[JDOM方式解析XML文档]
- XML学习06-Java中Dom4J方式解析XML文件
- 【XML解析】(4)Java下使用DOM4J解析方式对XML文档进行解析
- Dom4j解析XML文档
- dom4j解析xml文档
- DOM4J解析XML文档
- dom4j解析xml文档
- DOM4J解析XML文档
- DOM4J解析XML文档
- Dom4J解析XML文档
- Dom4J解析xml文档
- dom4j解析XML文档
- DOM4J解析XML文档
- dom4j解析xml文档
- DOM4J解析xml文档
- Dom4j解析XML文档
- Java 静态内部类
- #298 (div.2) B. Covered Path
- Android中常用的设计模式
- ios GCD详解
- ADF中组件无法显示问题
- java的xml学习[DOM4J方式解析XML文档]
- Android sdk content loader 0%的解决方案
- python 统计pvuv 一
- 【C#、SQL】C#+SQL 2008 存储和读取多幅图片
- 分页jsvs
- Linux命令CURL用法
- myeclips引入js时出现错误提示
- B+树与B*树小结
- webrtc peerconnection的依赖项目


