BP神经网络
来源:互联网 发布:js 窗体大小改变事件 编辑:程序博客网 时间:2024/04/29 15:41
BP神经网络模型拓扑结构包括输入层(input)、隐层(hide layer)和输出层(output layer)。它的学习规则是使用最速下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。BP网络模型处理信息的基本原理是:输入信号Xi通过中间节点(隐层点)作用于输出节点,经过非线形变换,产生输出信号Yk,网络训练的每个样本包括输入向量X和期望输出量t,网络输出值Y与期望输出值t之间的偏差,通过调整输入节点与隐层节点的联接强度取值Wij和隐层节点与输出节点之间的联接强度Tjk以及阈值,使误差沿梯度方向下降,经过反复学习训练,确定与最小误差相对应的网络参数(权值和阈值),训练即告停止。此时经过训练的神经网络即能对类似样本的输入信息,自行处理输出误差最小的经过非线形转换的信息。
算法步骤
第一步:创建网络
第二步:随机初始化
第三步:重复下述过程直到收敛:
(1)对N个样本,从k=1到N
正向过程计算:计算中间层各神经单元的激活值、输出值,输出层各单元的的激活值、输出值
反向过程:依次从输出层到中间层,中间层到输入层计算校正误差
(2)修正权值
样本预处理
样本输入应当归一化处理,数据归一化,就是将数据映射到[0,1]或[-1,1]区间或更小的区间,尽量使输入向量不相关,以确保各权值的收敛速度大致相同。为什么要归一化处理?
<1>输入数据的单位不一样,有些数据的范围可能特别大,导致的结果是神经网络收敛慢、训练时间长。
<2>数据范围大的输入在模式分类中的作用可能会偏大,而数据范围小的输入作用就可能会偏小。
<3>由于神经网络输出层的激活函数的值域是有限制的,因此需要将网络训练的目标数据映射到激活函数的值域。例如神经网络的输出层若采用S形激活函数,由于S形函数的值域限制在(0,1),也就是说神经网络的输出只能限制在(0,1),所以训练数据的输出就要归一化到[0,1]区间。
<4>S形激活函数在(0,1)区间以外区域很平缓,区分度太小。例如S形函数f(X)在参数a=1时,f(100)与f(5)只相差0.0067。
归一化算法
一种简单而快速的归一化算法是线性转换算法。线性转换算法常见有两种形式:
<1>
y = ( x - min )/( max - min )
其中min为x的最小值,max为x的最大值,输入向量为x,归一化后的输出向量为y 。上式将数据归一化到 [ 0 , 1 ]区间,当激活函数采用S形函数时(值域为(0,1))时这条式子适用。
<2>
y = 2 * ( x - min ) / ( max - min ) - 1
这条公式将数据归一化到 [ -1 , 1 ] 区间。当激活函数采用双极S形函数(值域为(-1,1))时这条式子适用。
(3)Z-score标准化
Z-score标准化是基于原始数据的均值和标准差进行的数据标准化。将属性 的原始数据
的原始数据 通过Z-score标
通过Z-score标
准化成 。Z-score标准化适用于属性
。Z-score标准化适用于属性 的最大值或者最小值未知的情况,或有超出取值范围的离散数据的
的最大值或者最小值未知的情况,或有超出取值范围的离散数据的
情况。

其中 为均值,
为均值, 为标准差。
为标准差。
Z-score标准化得到的结果是所有数据都聚集在0附近,方差为1。
关于随机初始化
既保证各神经元得输入值较小,工作在激励函数斜率变化最大的区域,也防止某些权值的绝对值多次学习后不合理的无限增长。一般取初始值为(-1,1)之间的随机数。
不同初值可能会对性能造成影响,而事先又难以预测较好地初值,所以干脆使用随机值。不能将所有的参数用相同的值作为初始值,那样的话所有的隐藏单元会得到与输入值有关的、相同的函数,随机初始化的目的是使对称失效。
学习率的选取
权值在每次循环学习中的变化受到学习率的影响较大。学习率小,学习时间长,收敛速度慢,不过能保证网络的误差值可以达到最终的极小点。系统的稳定性在学习率较大时可能会较差。通常我们倾向于选取较小的学习速率,其选取范围一般为 0.001 到 0.10之间以保证系统的稳定性。
采用变步长法根据输出误差大小自动调整学习因子,来减少迭代次数和加快收敛速度。
h =h +a×(Ep(n)- Ep(n-1))/ Ep(n)a为调整步长,0~1之间取值
隐层节点数的优化
隐节点数的多少对网络性能的影响较大,当隐节点数太多时,会导致网络学习时间过长,甚至不能收敛;而当隐节点数过小时,网络的容错能力差。利用逐步回归分析法并进行参数的显著性检验来动态删除一些线形相关的隐节点,节点删除标准:当由该节点出发指向下一层节点的所有权值和阈值均落于死区(通常取±0.1、±0.05等区间)之中,则该节点可删除。最佳隐节点数L可参考下面公式计算:
L=(m+n)1/2+c
m-输入节点数;n-输出节点数;c-介于1~10的常数。
算法推导
参数的求取
(1)正向传播时
中间层各神经元的激活值Sj

Wij是输入层到中间层的连接权,θj是中间层的阈值,θj在学习过程中也会不断被修正,p是中间层单元数。
中间层各神经元的输出值(采用S型函数)

输出层t个神经元的激活值Ot

Wjt是中间层到输出层的权值,θt是输出层各单元的阈值
输出层各神经元的输出值(采用S型函数)

(2)反向传播时
直接引用ufldl tutorial里的反向传导,讲得很清楚。
假设我们有一个固定样本集 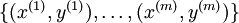 ,它包含
,它包含 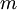 个样例。我们可以用批量梯度下降法来求解神经网络。具体来讲,对于单个样例
个样例。我们可以用批量梯度下降法来求解神经网络。具体来讲,对于单个样例 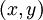 ,其代价函数为:
,其代价函数为:
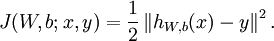
这是一个(二分之一的)方差代价函数。给定一个包含 个样例的数据集,我们可以定义整体代价函数为:
![\begin{align}J(W,b)&= \left[ \frac{1}{m} \sum_{i=1}^m J(W,b;x^{(i)},y^{(i)}) \right] + \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2 \\&= \left[ \frac{1}{m} \sum_{i=1}^m \left( \frac{1}{2} \left\| h_{W,b}(x^{(i)}) - y^{(i)} \right\|^2 \right) \right] + \frac{\lambda}{2} \sum_{l=1}^{n_l-1} \; \sum_{i=1}^{s_l} \; \sum_{j=1}^{s_{l+1}} \left( W^{(l)}_{ji} \right)^2\end{align}](http://deeplearning.stanford.edu/wiki/images/math/4/5/3/4539f5f00edca977011089b902670513.png)
以上公式中的第一项 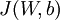 是一个均方差项。第二项是一个规则化项(也叫权重衰减项),其目的是减小权重的幅度,防止过度拟合。
是一个均方差项。第二项是一个规则化项(也叫权重衰减项),其目的是减小权重的幅度,防止过度拟合。
[注:通常权重衰减的计算并不使用偏置项 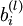 ,比如我们在 的定义中就没有使用。一般来说,将偏置项包含在权重衰减项中只会对最终的神经网络产生很小的影响。如果你在斯坦福选修过CS229(机器学习)课程,或者在YouTube上看过课程视频,你会发现这个权重衰减实际上是课上提到的贝叶斯规则化方法的变种。在贝叶斯规则化方法中,我们将高斯先验概率引入到参数中计算MAP(极大后验)估计(而不是极大似然估计)。]
,比如我们在 的定义中就没有使用。一般来说,将偏置项包含在权重衰减项中只会对最终的神经网络产生很小的影响。如果你在斯坦福选修过CS229(机器学习)课程,或者在YouTube上看过课程视频,你会发现这个权重衰减实际上是课上提到的贝叶斯规则化方法的变种。在贝叶斯规则化方法中,我们将高斯先验概率引入到参数中计算MAP(极大后验)估计(而不是极大似然估计)。]
权重衰减参数 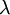 用于控制公式中两项的相对重要性。在此重申一下这两个复杂函数的含义:
用于控制公式中两项的相对重要性。在此重申一下这两个复杂函数的含义: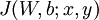 是针对单个样例计算得到的方差代价函数; 是整体样本代价函数,它包含权重衰减项。
是针对单个样例计算得到的方差代价函数; 是整体样本代价函数,它包含权重衰减项。
以上的代价函数经常被用于分类和回归问题。在分类问题中,我们用 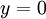 或
或 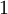 ,来代表两种类型的标签(回想一下,这是因为 sigmoid激活函数的值域为
,来代表两种类型的标签(回想一下,这是因为 sigmoid激活函数的值域为 ![\textstyle [0,1]](http://deeplearning.stanford.edu/wiki/images/math/8/4/2/84235d31ac83fe764546463aba7acc0e.png) ;如果我们使用双曲正切型激活函数,那么应该选用
;如果我们使用双曲正切型激活函数,那么应该选用 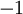 和
和 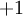 作为标签)。对于回归问题,我们首先要变换输出值域(译者注:也就是
作为标签)。对于回归问题,我们首先要变换输出值域(译者注:也就是 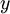 ),以保证其范围为 (同样地,如果我们使用双曲正切型激活函数,要使输出值域为
),以保证其范围为 (同样地,如果我们使用双曲正切型激活函数,要使输出值域为 ![\textstyle [-1,1]](http://deeplearning.stanford.edu/wiki/images/math/8/5/a/85a1c5a07f21a9eebbfb1dca380f8d38.png) )。
)。
我们的目标是针对参数 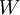 和
和 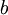 来求其函数 的最小值。为了求解神经网络,我们需要将每一个参数
来求其函数 的最小值。为了求解神经网络,我们需要将每一个参数 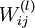 和 初始化为一个很小的、接近零的随机值(比如说,使用正态分布
和 初始化为一个很小的、接近零的随机值(比如说,使用正态分布 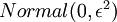 生成的随机值,其中
生成的随机值,其中 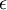 设置为
设置为 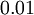 ),之后对目标函数使用诸如批量梯度下降法的最优化算法。因为 是一个非凸函数,梯度下降法很可能会收敛到局部最优解;但是在实际应用中,梯度下降法通常能得到令人满意的结果。最后,需要再次强调的是,要将参数进行随机初始化,而不是全部置为
),之后对目标函数使用诸如批量梯度下降法的最优化算法。因为 是一个非凸函数,梯度下降法很可能会收敛到局部最优解;但是在实际应用中,梯度下降法通常能得到令人满意的结果。最后,需要再次强调的是,要将参数进行随机初始化,而不是全部置为 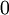 。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有
。如果所有参数都用相同的值作为初始值,那么所有隐藏层单元最终会得到与输入值有关的、相同的函数(也就是说,对于所有  ,
,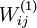 都会取相同的值,那么对于任何输入
都会取相同的值,那么对于任何输入  都会有:
都会有: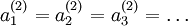 )。随机初始化的目的是使对称失效。
)。随机初始化的目的是使对称失效。
梯度下降法中每一次迭代都按照如下公式对参数 和 进行更新:
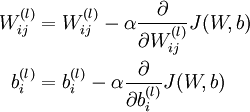
其中 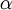 是学习速率。其中关键步骤是计算偏导数。我们现在来讲一下反向传播算法,它是计算偏导数的一种有效方法。
是学习速率。其中关键步骤是计算偏导数。我们现在来讲一下反向传播算法,它是计算偏导数的一种有效方法。
我们首先来讲一下如何使用反向传播算法来计算 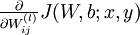 和
和 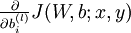 ,这两项是单个样例 的代价函数 的偏导数。一旦我们求出该偏导数,就可以推导出整体代价函数 的偏导数:
,这两项是单个样例 的代价函数 的偏导数。一旦我们求出该偏导数,就可以推导出整体代价函数 的偏导数:
![\begin{align}\frac{\partial}{\partial W_{ij}^{(l)}} J(W,b) &=\left[ \frac{1}{m} \sum_{i=1}^m \frac{\partial}{\partial W_{ij}^{(l)}} J(W,b; x^{(i)}, y^{(i)}) \right] + \lambda W_{ij}^{(l)} \\\frac{\partial}{\partial b_{i}^{(l)}} J(W,b) &=\frac{1}{m}\sum_{i=1}^m \frac{\partial}{\partial b_{i}^{(l)}} J(W,b; x^{(i)}, y^{(i)})\end{align}](http://deeplearning.stanford.edu/wiki/images/math/9/3/3/93367cceb154c392aa7f3e0f5684a495.png)
以上两行公式稍有不同,第一行比第二行多出一项,是因为权重衰减是作用于 而不是 。
反向传播算法的思路如下:给定一个样例 ,我们首先进行“前向传导”运算,计算出网络中所有的激活值,包括 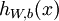 的输出值。之后,针对第
的输出值。之后,针对第  层的每一个节点 ,我们计算出其“残差”
层的每一个节点 ,我们计算出其“残差” 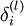 ,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为
,该残差表明了该节点对最终输出值的残差产生了多少影响。对于最终的输出节点,我们可以直接算出网络产生的激活值与实际值之间的差距,我们将这个差距定义为 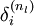 (第
(第 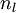 层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第
层表示输出层)。对于隐藏单元我们如何处理呢?我们将基于节点(译者注:第 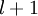 层节点)残差的加权平均值计算 ,这些节点以
层节点)残差的加权平均值计算 ,这些节点以 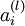 作为输入。下面将给出反向传导算法的细节:
作为输入。下面将给出反向传导算法的细节:
- 进行前馈传导计算,利用前向传导公式,得到
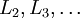 直到输出层
直到输出层 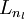 的激活值。
的激活值。 - 对于第 层(输出层)的每个输出单元 ,我们根据以下公式计算残差:
- 对
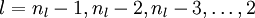 的各个层,第 层的第 个节点的残差计算方法如下:
的各个层,第 层的第 个节点的残差计算方法如下: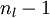 与的关系替换为与的关系,就可以得到:
与的关系替换为与的关系,就可以得到: - 计算我们需要的偏导数,计算方法如下:
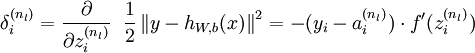
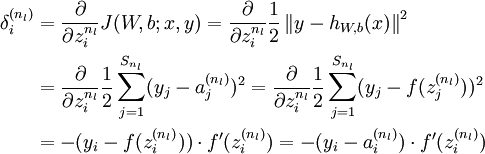
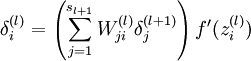
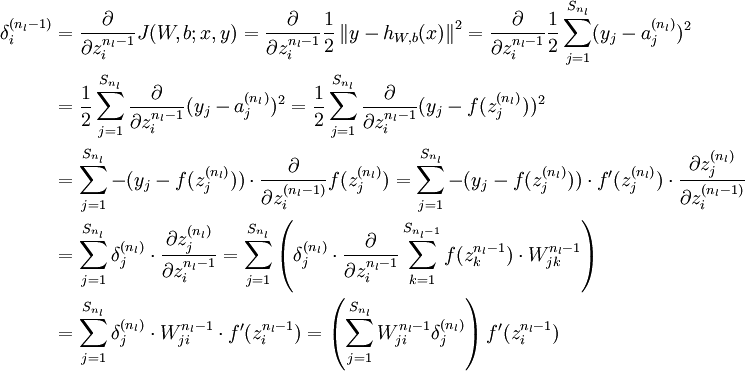
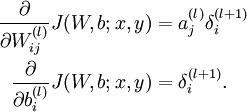
最后,我们用矩阵-向量表示法重写以上算法。我们使用“ ” 表示向量乘积运算符(在Matlab或Octave里用“.*”表示,也称作阿达马乘积)。若
” 表示向量乘积运算符(在Matlab或Octave里用“.*”表示,也称作阿达马乘积)。若 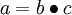 ,则
,则 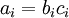 。在上一个教程中我们扩展了
。在上一个教程中我们扩展了 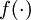 的定义,使其包含向量运算,这里我们也对偏导数
的定义,使其包含向量运算,这里我们也对偏导数 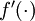 也做了同样的处理(于是又有
也做了同样的处理(于是又有 ![\textstyle f'([z_1, z_2, z_3]) = [f'(z_1), f'(z_2), f'(z_3)]](http://deeplearning.stanford.edu/wiki/images/math/c/7/5/c7515c53b59e670ceee277e06c1229cb.png) )。
)。
那么,反向传播算法可表示为以下几个步骤:
- 进行前馈传导计算,利用前向传导公式,得到 直到输出层 的激活值。
- 对输出层(第 层),计算:
- 对于 的各层,计算:
- 计算最终需要的偏导数值:
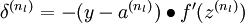
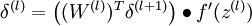
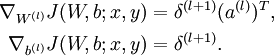
实现中应注意:在以上的第2步和第3步中,我们需要为每一个 值计算其 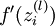 。假设
。假设 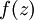 是sigmoid函数,并且我们已经在前向传导运算中得到了 。那么,使用我们早先推导出的
是sigmoid函数,并且我们已经在前向传导运算中得到了 。那么,使用我们早先推导出的 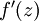 表达式,就可以计算得到
表达式,就可以计算得到 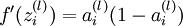 。
。
最后,我们将对梯度下降算法做个全面总结。在下面的伪代码中,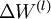 是一个与矩阵
是一个与矩阵 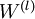 维度相同的矩阵,
维度相同的矩阵,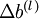 是一个与
是一个与 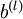 维度相同的向量。注意这里“”是一个矩阵,而不是“
维度相同的向量。注意这里“”是一个矩阵,而不是“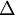 与 相乘”。下面,我们实现批量梯度下降法中的一次迭代:
与 相乘”。下面,我们实现批量梯度下降法中的一次迭代:
- 对于所有 ,令
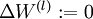 ,
, 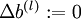 (设置为全零矩阵或全零向量)
(设置为全零矩阵或全零向量) - 对于
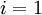 到 ,
到 ,- 使用反向传播算法计算
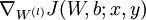 和
和 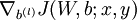 。
。 - 计算
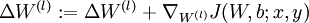 。
。 - 计算
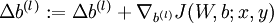 。
。
- 使用反向传播算法计算
- 更新权重参数:
![\begin{align}W^{(l)} &= W^{(l)} - \alpha \left[ \left(\frac{1}{m} \Delta W^{(l)} \right) + \lambda W^{(l)}\right] \\b^{(l)} &= b^{(l)} - \alpha \left[\frac{1}{m} \Delta b^{(l)}\right]\end{align}](http://deeplearning.stanford.edu/wiki/images/math/0/f/7/0f7430e97ec4df1bfc56357d1485405f.png)
现在,我们可以重复梯度下降法的迭代步骤来减小代价函数 的值,进而求解我们的神经网络。
算法优化
利用GA遗传算法搜索参数
由于BP算法采用的是剃度下降法,因而易陷于局部最小并且训练时间较长。用基于生物免疫机制地既能全局搜索又能避免未成熟收敛的免疫遗传算法GA取代传统BP算法来克服此缺点。
动量BP算法
标准BP算法在调整权值时,只是按t时刻误差的梯度方向调整,而没有考虑t时刻以前的梯度方向,从而使训练过程发生振荡,收敛缓慢,为了提高网络训练速度,可在调整公式中增加一动量项。该方法是在反向传播法的基础上在每一个权值的变化上加上一项正比于前次权值变化量的值,并根据反向传播法来产生新的权值变化。它的实质就是改变学习率η来提高网络性能,其网络连接权的迭代关系式由传统BP算法

变为

其中α为动量因子,0<α<1。动量项的作用在于记忆上一时刻的连接权的变化方向(即变化量的值),这样就可以用较大的学习速率系数η以提高学习速度。附加动量项利用其“惯性效应”来抑制网络训练中可能出现的振荡,起到了缓冲平滑的作用。
momentum的作用是什么?
学习率可变
该方法被认为是一种最简单最有效的方法。在BP算法中,连接权的调整决定于学习速率和梯度,但是,在基本BP算法中,学习速率是不变的。实际上学习速率对收敛速度的影响也很大,通过对它的在线调整,可以大大提高收敛速度。
学习速率的调整原则上是使它在每一步保持尽可能大的值,而又不致使学习过程失去稳定性。学习速率可以根据误差变化的信息和误差函数对连接权梯度变化的信息进行启发式调整,也可以根据误差函数对学习速率的梯度直接进行调整。
对于批处理可以根据总误差变化的信息进行启发式调整,其规则是:
(1)若总误差E减小,则学习率增加。
(2)若总误差E增加,则学习率减小。当新误差与老误差之比超过一定值(例如1.04),则学习率快速下降(例如将实际值乘以因子b=0.7).
上述规则可用如下迭代方程来描述:

其中参数的典型值为:a=1.05,b=0.7,k=1.04。上述方法可以在学习过程的每一步进行学习率的调整。
共轭梯度法
用共轭梯度法替代梯度下降法。与梯度下降法不同,基于数值优化的算法不仅利用了目标函数的一阶导数信息,而且往往利用了目标函数的二阶导数信息。具体可参见我博客关于共轭梯度法的介绍。
BP神经网络的优点
(1)并行分布处理方法:结构上的并行,使得网络的各节点可以同时进行类似的处理过程。
(2)非线性映射能力:在建模过程中遇到的许多问题均具有高度的非线性。而 BP网络能以任意精度对任一非线性连续函数逼近,具有较强的建模能力。
(3)容错性:全局的学习训练或识别不会因为少量局部的神经元的影响而失去作用。系统在发生局部损伤时仍可以继续正常工作。当网络中的某一个节点或者某几个节点受到破坏后,由于信息在几乎整个网络中被分布式存放,信息仍然可以被存取。
(4)自学习、自适应性:每两个神经元之间的连接矩阵能够被改变,通过学习可以在输入信号中提取特征,这些特征人类可能无法直接理解,将这些特征通过写入网络的连接矩阵与偏置进行记忆,使得网络系统可以更加一般的进行使用,网络的学习也可以是逐个样本逐次学习的在线学习方式。
(5)泛化能力:可以充分逼近任意复杂的非线性关系,学习好的网络模型实际使用时仍可以达到较好的效果。
BP神经网络的缺点
主要表现在学习过程的不定性上,具体如下:
(1)学习时间较长,遇到部分问题时,可能需要运行几个小时甚至更久。
(2)容易陷入局部极小值。
(3)完全无法学习,激活函数由于权值调整过大而进入饱和区域,最终网络权值的调节陷入停滞。
(4)喜新厌旧。训练过程中,学习新样本时有一定可能将旧样本遗忘掉
下面是用tensorflow做的一个简单bp神经网络分类demo
import tensorflow as tfimport numpy as npimport matplotlib.pyplot as plt#train_dataN = 300 # number of points per classD = 2 # dimensionalityK = 3 # number of classesX = np.zeros((N*K,D)) # data matrix (each row = single example)Y = np.zeros(N*K, dtype='uint8') # class labelsfor j in xrange(K): ix = range(N*j,N*(j+1)) r = np.linspace(0.0,1,N) # radius t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2 # theta X[ix] = np.c_[r*np.sin(t), r*np.cos(t)] Y[ix] = j#test_dataNN=100X_test = np.zeros((NN*K,D)) # data matrix (each row = single example)Y_test = np.zeros(NN*K, dtype='uint8') # class labelsfor j in xrange(K): ix = range(NN*j,NN*(j+1)) r = np.linspace(0.0,1,NN) # radius t = np.linspace(j*4,(j+1)*4,NN) + np.random.randn(NN)*0.2 # theta X_test[ix] = np.c_[r*np.sin(t), r*np.cos(t)] Y_test[ix] = j# lets visualize the data:plt.scatter(X[:, 0], X[:, 1], c=Y, s=40, cmap=plt.cm.Spectral)plt.show()plt.scatter(X_test[:, 0], X_test[:, 1], c=Y_test, s=40, cmap=plt.cm.Spectral)plt.show()def dense_to_one_hot(labels_dense, num_classes=3): """Convert class labels from scalars to one-hot vectors.""" num_labels = labels_dense.shape[0] index_offset = np.arange(num_labels) * num_classes labels_one_hot = np.zeros((num_labels, num_classes)) labels_one_hot.flat[index_offset + labels_dense.ravel()] = 1 return labels_one_hotY=dense_to_one_hot(Y,3)Y_test=dense_to_one_hot(Y_test,3)# Parameterslearning_rate = 0.001training_epochs = 500display_step = 1# Network Parametersn_hidden_1 = 100 # 1st layer num featuresn_input = 2n_classes = 3 #total classes# tf Graph inputx = tf.placeholder("float", [None, n_input])y = tf.placeholder("float", [None, n_classes])# Create modeldef multilayer_perceptron(_X, _weights, _biases): layer_1 = tf.nn.relu(tf.add(tf.matmul(_X, _weights['h1']), _biases['b1'])) #Hidden layer with RELU activation return tf.matmul(layer_1, _weights['out']) + _biases['out']# Store layers weight & biasweights = { 'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])), 'out': tf.Variable(tf.random_normal([n_hidden_1, n_classes]))}biases = { 'b1': tf.Variable(tf.random_normal([n_hidden_1])), 'out': tf.Variable(tf.random_normal([n_classes]))}# Construct modelpred = multilayer_perceptron(x, weights, biases)# Define loss and optimizercost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(pred, y)) # Softmax lossoptimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost) # Adam Optimizer# Initializing the variablesinit = tf.initialize_all_variables()# Launch the graphwith tf.Session() as sess: sess.run(init) # Training cycle for epoch in range(training_epochs): avg_cost = 0. # Fit training using batch data sess.run(optimizer, feed_dict={x: X, y: Y}) # Compute average loss avg_cost += sess.run(cost, feed_dict={x: X, y: Y}) # Display logs per epoch step if epoch % display_step == 0: print "Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost) print "Optimization Finished!" # Test model correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1)) # Calculate accuracy accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) print "Accuracy:", accuracy.eval({x: X_test, y:Y_test})
bp网络增量式学习
bp网络增量式学习时数据归一化的处理
参考资料:http://blog.csdn.net/celerychen2009/article/details/8964753
L2正则化方法
神经网络和深度学习-学习总结
神经网络和深度学习简史(一)
深度学习和神经网络简史(二)
神经网络和深度学习简史(三):强化学习与递归神经网络
神经网络和深度学习简史(四):深度学习终迎伟大复兴
- BP神经网络
- BP神经网络
- BP 神经网络
- bp神经网络
- BP神经网络
- BP神经网络
- BP神经网络
- BP神经网络
- BP神经网络
- bp神经网络
- BP神经网络
- BP神经网络
- BP神经网络
- BP神经网络
- BP神经网络
- BP神经网络
- BP神经网络
- BP神经网络
- 局域网之远程连接
- 牛市要赶早
- bat批处理文件问题
- Hints详解
- Pav Metro Store OpenCart 自适应主题模板 ABC-0215
- BP神经网络
- eval解析JSON中的注意点
- protocol buffer newBuilder速度慢问题
- ogg 日志维护
- python中文输出问题
- DatePicker及TimePicker的使用
- PHP中的函数
- 利用java自带的base64实现加密、解密
- 黑马程序员——Objective-C——三大特性


