浅析NUMA体系结构
来源:互联网 发布:linux如何修改只读文件 编辑:程序博客网 时间:2024/06/05 14:55
1. NUMA的几个概念(Node,socket,core,thread)
对于socket,core和thread会有不少文章介绍,这里简单说一下,具体参见下图:

一句话总结:socket就是主板上的CPU插槽; Core就是socket里独立的一组程序执行的硬件单元,比如寄存器,计算单元等; Thread:就是超线程hyperthread的概念,逻辑的执行单元,独立的执行上下文,但是共享core内的寄存器和计算单元。
NUMA体系结构中多了Node的概念,这个概念其实是用来解决core的分组的问题,具体参见下图来理解(图中的OS CPU可以理解thread,那么core就没有在图中画出),从图中可以看出每个Socket里有两个node,共有4个socket,每个socket 2个node,每个node中有8个thread,总共4(Socket)× 2(Node)× 8 (4core × 2 Thread) = 64个thread。
另外每个node有自己的内部CPU,总线和内存,同时还可以访问其他node内的内存,NUMA的最大的优势就是可以方便的增加CPU的数量,因为Node内有自己内部总线,所以增加CPU数量可以通过增加Node的数目来实现,如果单纯的增加CPU的数量,会对总线造成很大的压力,所以UMA结构不可能支持很多的核。
《此图出自:NUMA Best Practices for Dell PowerEdge 12th Generation Servers》
根据上面提到的,由于每个node内部有自己的CPU总线和内存,所以如果一个虚拟机的vCPU跨不同的Node的话,就会导致一个node中的CPU去访问另外一个node中的内存的情况,这就导致内存访问延迟的增加。在有些特殊场景下,比如NFV环境中,对性能有比较高的要求,就非常需要同一个虚拟机的vCPU尽量被分配到同一个Node中的pCPU上,所以在OpenStack的Kilo版本中增加了基于NUMA感知的虚拟机调度的特性。(OpenStack Kilo中NFV相关的功能具体参见:《OpenStack Kilo新特性解读和分析(1)》)
2. 如何查看机器的NUMA拓扑结构
比较常用的命令就是lscpu,具体输出如下:
- dylan@hp3000:~$ lscpu
- Architecture: x86_64
- CPU op-mode(s): 32-bit, 64-bit
- Byte Order: Little Endian
- CPU(s): 48 //共有48个逻辑CPU(threads)
- On-line CPU(s) list: 0-47
- Thread(s) per core: 2 //每个core有2个threads
- Core(s) per socket: 6 //每个socket有6个cores
- Socket(s): 4 //共有4个sockets
- NUMA node(s): 4 //共有4个NUMA nodes
- Vendor ID: GenuineIntel
- CPU family: 6
- Model: 45
- Stepping: 7
- CPU MHz: 1200.000
- BogoMIPS: 4790.83
- Virtualization: VT-x
- L1d cache: 32K //L1 data cache 32k
- L1i cache: 32K //L1 instruction cache 32k (牛x机器表现,冯诺依曼+哈弗体系结构)
- L2 cache: 256K
- L3 cache: 15360K
- NUMA node0 CPU(s): 0-5,24-29
- NUMA node1 CPU(s): 6-11,30-35
- NUMA node2 CPU(s): 12-17,36-41
- NUMA node3 CPU(s): 18-23,42-47
另外,也可以通过下面的网页设计脚本来打印出当前机器的socket,core和thread的数量。
- #!/bin/bash
- # Simple print cpu topology
- # Author: kodango
- function get_nr_processor()
- {
- grep '^processor' /proc/cpuinfo | wc -l
- }
- function get_nr_socket()
- {
- grep 'physical id' /proc/cpuinfo | awk -F: '{
- print $2 | "sort -un"}' | wc -l
- }
- function get_nr_siblings()
- {
- grep 'siblings' /proc/cpuinfo | awk -F: '{
- print $2 | "sort -un"}'
- }
- function get_nr_cores_of_socket()
- {
- grep 'cpu cores' /proc/cpuinfo | awk -F: '{
- print $2 | "sort -un"}'
- }
- echo '===== CPU Topology Table ====='
- echo
- echo '+--------------+---------+-----------+'
- echo '| Processor ID | Core ID | Socket ID |'
- echo '+--------------+---------+-----------+'
- while read line; do
- if [ -z "$line" ]; then
- printf '| %-12s | %-7s | %-9s |\n' $p_id $c_id $s_id
- echo '+--------------+---------+-----------+'
- continue
- fi
- if echo "$line" | grep -q "^processor"; then
- p_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
- fi
- if echo "$line" | grep -q "^core id"; then
- c_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
- fi
- if echo "$line" | grep -q "^physical id"; then
- s_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
- fi
- done < /proc/cpuinfo
- echo
- awk -F: '{
- if ($1 ~ /processor/) {
- gsub(/ /,"",$2);
- p_id=$2;
- } else if ($1 ~ /physical id/){
- gsub(/ /,"",$2);
- s_id=$2;
- arr[s_id]=arr[s_id] " " p_id
- }
- }
- END{
- for (i in arr)
- printf "Socket %s:%s\n", i, arr[i];
- }' /proc/cpuinfo
- echo
- echo '===== CPU Info Summary ====='
- echo
- nr_processor=`get_nr_processor`
- echo "Logical processors: $nr_processor"
- nr_socket=`get_nr_socket`
- echo "Physical socket: $nr_socket"
- nr_siblings=`get_nr_siblings`
- echo "Siblings in one socket: $nr_siblings"
- nr_cores=`get_nr_cores_of_socket`
- echo "Cores in one socket: $nr_cores"
- let nr_cores*=nr_socket
- echo "Cores in total: $nr_cores"
- if [ "$nr_cores" = "$nr_processor" ]; then
- echo "Hyper-Threading: off"
- else
- echo "Hyper-Threading: on"
- fi
- echo
- echo '===== END ====='
email: ustc.dylan@gmail.com
微博:@Marshal-Liu
PC硬件结构近5年的最大变化是多核CPU在PC上的普及,多核最常用的SMP微架构:
- 多个CPU之间是平等的,无主从关系(对比IBM Cell)网络公司;
- 多个CPU平等的访问系统内存,也就是说内存是统一结构、统一寻址的(UMA,Uniform Memory Architecture);
- CPU到CPU的访问必须通过系统总线。
结构如图所示:
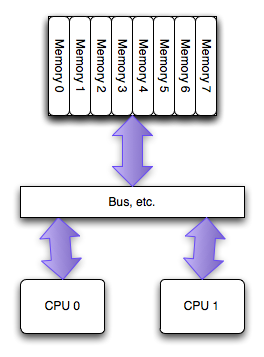 SMP的问题主要在CPU和内存之间的通信延迟较大、通信带宽受限于系统总线带宽,同时总线带宽会成为整个系统的瓶颈。
SMP的问题主要在CPU和内存之间的通信延迟较大、通信带宽受限于系统总线带宽,同时总线带宽会成为整个系统的瓶颈。
由此应运而生了NUMA架构:
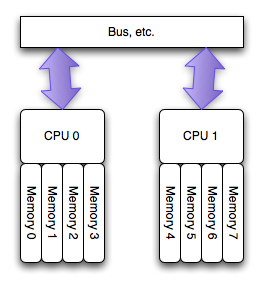 NUMA(Non-Uniform Memory Access)是起源于AMD Opteron的微架构,同时被Intel Nehalem采用(英特尔志强E5500以上的CPU和桌面的i3、i5、i7均基于此架构)。这也应该是继AMD64后AMD对CPU架构的又一项重要改进。
NUMA(Non-Uniform Memory Access)是起源于AMD Opteron的微架构,同时被Intel Nehalem采用(英特尔志强E5500以上的CPU和桌面的i3、i5、i7均基于此架构)。这也应该是继AMD64后AMD对CPU架构的又一项重要改进。
在这个架构中,每个处理器有其可以直接访问其自身的“本地”内存池,使CPU和这块儿内存之间拥有更小的延迟和更大的带宽。而且整个内存仍然可做为一个整体,可以接受来自任何CPU的访问。简言之就是CPU访问自己领地内的内存延迟最小独占带宽,访问其他的内存区域稍慢并且共享带宽。
GNU/Linux如何管理NUMA:
- probe硬件,了解物理CPU数量,内存大小等;
- 根据物理CPU的数量(不是core)分配node,一个物理CPU对应一个node;
- 把属于一个node的内存模块和其node相联系;
- 测试各个CPU到各个内存区域的通信延迟;
在一台16GB内存,双Xeon E5620 CPU Dell R710用numactl得到以下信息:
# numactl --hardware
available: 2 nodes (0-1)
node 0 size: 8080 MB
node 0 free: 5643 MB
node 1 size: 8051 MB
node 1 free: 2294 MB
node distances:
node 0 1
0: 10 20
1: 20 10
- 第一列node0和node1就是对应物理CPU0和CPU1;
- size就是指在此节点NUMA分配的内存总数;
- free是指此节点NUMA的内存空闲数量;
- node distances就是指node到各个内存节点之间的距离,默认情况10是指本地内存,21是指跨区域访问。
因为就近内存访问的快速性,所以默认情况下一个CPU只访问其所属区域的内存空间。此时造成的问题是在大内存占用的一些应用时会有CPU近线内存不够的情况,可以使用如下方式把CPU对内存区域的访问变为round robin方式。此时需要通过以下方式修改:
# echo 0 > /proc/sys/vm/zone_reclaim_mode
# numactl --interleave=all
memcached、redis、monodb等应该做以上的优化修改。
另外,如果有时间,下一篇会总结一下自己对于此问题的思考:如果自己实现一个内存池,并发挥NUMA架构的最大效能,如何设计?
参考自:
http://en.wikipedia.org/wiki/Non-Uniform_Memory_Access
Ulrich Drepper, Memory part 4: NUMA support http://lwn.net/Articles/254445/
http://www.kernel.org/doc/Documentation/sysctl/vm.txt
就目前而言,CPU主频速度的迅速提升以及CPU数量的高速增长,并没有能够促使CPU在访问内存时的速度有所长进。
尽管L3 Cache的提出解决了部分问题,不过,CPU访问内存速度慢的现象并未有所改观,瓶颈依然存在。
为了更有效的解决CPU访问内存的速度问题,工业界引入了NUMA概念
首先介绍一下 NUMA 的架构,如下图:

每个 NUMA 节点(硬件 NUMA 或软件 NUMA)都有一个用于处理网络 I/O 的相关 I/O 完成端口,这有助于跨多个端口分布网络 I/O 处理
上述结构中展现出两个NUMA结点,每个NUMA结点有一些CPU, 一个内部总线,和自己的内存,甚至可以有自己的IO。每个CPU有离自己最近的内存可以直接访问。
所以,使用NUMA架构,系统的性能会更佳。值得注意的是,在NUMA结构下,可以比较方便的增加CPU的数目。
而在非NUMA架构下,增加CPU会导致系统总线负载很重,性能提升不明显。
虽然每个CPU也可以访问其他NUMA结点上的内存,但付出的代价则是导致网站运营速度更慢,这是要尽量避免的。
应用软件如果没有意识到这种结构,在NUMA机器上,有时候性能会更差,这是因为,他们经常会不自觉的去访问远端内存,从而导致整体性能下降。
通常而言,NUMA架构也有硬件和软件之分。
一、硬件NUMA
硬件NUMA是在硬件层面上得以支持。如何才能知道本机是否有硬件NUMA呢? 最好的办法是问硬件供应商了。
但如果想知道机器中有多少个NUMA结点,那就可以在SQL Server Management Studio下用如下的查询,看能返回几个NUMA结点
1 SELECT DISTINCT memory_node_id FROM sys.dm_os_memory_clerks
或者,可以查看SQL Server的错误日志,如下面的错误日志表明,系统有两个NUMA结点

从 SQL Server 2000 SP3 以后,SQL Server开始支持NUMA架构,内存访问会尽量使用离CPU最近的内存,以提高性能。
二、软件NUMA
如果硬件本身不支持NUMA,还可以在软件层面上设置NUMA,如机器有4个CPU, 设成两个NUMA NODE
一个NODE占用CPU 0x11 (二进制编码),另外一个NODE占用CPU 0x1100 (二进制编码)。
那么,可以在注册表上做如下修改,以SQL Server 2008为例:

软件NUMA只是对CPU进行分组,并不会改变内存。因此对于内存来讲,还是只有一个结点,所以两个NUMA结点,访问的都是同一块内存。
而增加软件NUMA结点的好处在于,SQL Server会针对每一个软件NUMA结点,多一个LazyWriter的线程,
如果系统在LazyWriter上是性能瓶颈的话,引入Software NUMA则可以有效提升性能。
在服务器属性这个地方设置的只是软件NUMA,要机器真正支持硬件NUMA才是真正的NUMA

面对连接层面的NUMA
SQL Server 不仅仅在引擎上支持NUMA,在连接层面上也支持NUMA。
如果没有在连接层面上对NUMA进行设置的话,那么每一个连接进来,SQL Server会根据round-robin方式,选择NODE 进行处理。
在NODE内部,SQL Server会选择CPU负载最低的一个CPU进行处理。而这种方法的网站优化缺点是,有可能某一个NODE内的所有CPU都很忙,
但是另外一个NODE内的所有CPU都很空,从而导致资源不均衡。这种情况下,使用NUMA架构时网站推广性能反而会下降,还不如使用非NUMA架构,
系统能均衡分配CPU资源。
如下图所示,采用round-robin方式,可能NUMA NODE 0会非常繁忙,而NUMA NODE 1会非常空闲,系统资源不能充分利用。
重要的连接可能会被分配到NODE 0,导致不能得到及时处理,性能受到影响。

对此,可以在连接层面上进行设置。对于重要的操作,使用端口1450,该端口会绑定NUMA结点0、1,、2,
而对于不重要的网络优化操作(可能需要耗费大量资源,但不重要的),则使用网络推广端口1433,该网络营销端口会绑定NUMA结点3,
如此,不重要的操作不会对重要的操作在性能上有所影响

如何设置端口对NUMA结点的绑定?可以在侦听的设计公司端口后面加NUMA结点信息。如有八个NUMA结点,如果要使用NUMA结点0, 2, 5 那么根据MASK方式,
相应的数值是0x25,或37

在SQL Server的网络设置中,相应的网络侦听端口后面,我们可以加MASK数值,如下,
这样,端口63409进来的连接,会跟NUMA结点0, 2, 5 进行绑定。

应该在配置管理器那里设置,我的是SQL2005

综上所述,NUMA概念的引入,将大大地提升硬件的可扩展性和处理能力。
SQL Server 从硬件NUMA、软件NUMA及连接上分别对NUMA这个体系架构做了优化支持,因此,在NUMA架构下,SQL Server拥有更佳的建设网站性能和更好的网站设计公司扩展。
SQL Server 如何支持 NUMA
文章地址:http://msdn.microsoft.com/zh-cn/library/ms180954(v=SQL.105).aspx
这里我摘抄一些重要部分算了
公共 CPU 的网站设计分组
SQL Server 对计划程序进行分组,以根据 Windows 所显示的硬件 NUMA 边界将这些计划程序映射到 CPU 的分组。
例如,16 路逻辑单元有 4 个 NUMA 节点,每个节点有 4 个 CPU。这使得在节点上处理任务时,该组计划程序具有更多的本地内存。
使用 SQL Server,您可以进一步将网站建设公司与硬件 NUMA 节点关联的 CPU 细分为多个 CPU 节点。这称为软件 NUMA。
通常,您将细分做网站CPU 以跨建网站 CPU 节点对工作进行分区。
名词解释:
16 路逻辑单元:说的是16个逻辑CPU,什么是逻辑CPU,比如酷睿I3cpu 双核四线程,那么四线程实际上就是四个逻辑CPU
四个逻辑CPU是指在同一个时间点,可以同时运算的计算单元,运行四个线程,处理四个任务在同一个时间点
计划程序:就是SQLOS里面的 scheduler,详细可以看我这篇文章 SQLSERVER独特的任务调度算法"SQLOS"
继续摘抄:--------------------------------------------------------------------------------------------------------------------
每个 NUMA 节点(硬件 NUMA 或软件 NUMA)都有一个用于处理网络 I/O 的相关 I/O 完成端口,这有助于跨多个端口分布网络 I/O 处理。
当某个客户端连接到 SQL Server 时,将绑定到其中一个节点。此客户端的所有批处理请求都将在该节点上处理
上面这句话是对上面哪两个图的很好解释
软件 NUMA 针对计算机中的所有 SQL Server 实例定义一次,因此,多个数据库引擎实例都能看到同样的软件 NUMA 节点。
然后,每个数据库引擎实例都使用 affinity mask 选项选择相应的 CPU。接着,每个实例都使用与这些 CPU 关联的任何软件 NUMA 节点
这句话说的就是服务器属性里面的CPU掩码
Windows 在启动后,从硬件 NODE 0 为操作系统分配内存。
因此,硬件 NODE 0 可用于其他应用程序的本地内存少于其他节点。
当需要缓存一个大型文件时,此问题尤为突出。当 SQL Server 在具有多个 NUMA 节点的计算机中启动时,它将尝试在 NODE 0 以外的 NUMA 节点上启动
如何将连接分配到 NUMA 节点
TCP 和 VIA 都可以将连接关联到一个或多个特定 NUMA 节点。当未进行关联,或使用 Named Pipes 或 Shared Memory 进行连接时,连接将采用循环方式分布到 NUMA 节点。在 NUMA 节点内,连接按照该节点上负载最小的计划程序运行。由于新连接的分配具有循环性,因此,例如:网站建设,APP开发,网页制作,网站制作,网站制作公司企业网站建设的网站中可以设置的。当某个节点空闲时,另一个节点中的所有 CPU 可能都处于繁忙状态。如果您的 CPU 非常少(如 2 个),
并且看到由于具有长时间运行的批处理(如大容量加载)而导致庞大的计划不均衡,则在这种情况下,关闭 NUMA 可能会提高性能。
这句话同样也是上面两个分配连接的截图的补充解释
SQL Server 版本限制
从 SQL Server 2000 到 Service Pack 3,都不包括对 NUMA 的特别支持;
但是,Service Pack 4 有一些有限的 NUMA 优化。SQL Server 2005 有了大量重要的改进
,因此,我们极力鼓励 NUMA 用户升级到 SQL Server 2005 以充分利用 NUMA 体系结构
我的个人理解
SQLSERVER2008支持硬件NUMA,SQLSERVER2005只支持软件NUMA
假如一台电脑有两个物理NUMA节点(当然前提是电脑要支持NUMA),那么内存可以分成两份
SQL2008可以直接访问这两份内存
SQL2005 只能访问同一份内存
(引用一下宋大侠的一些图片)
NUMA节点的概念
逻辑CPU:代表多少个线程
core:代表多少个核心
numa node:numa节点
socket:socket通讯
例如:酷睿I3 双核四线程,那么逻辑CPU(logical cpu)有4个,core有2个

SQL Server OS在SMP硬件 直接访问同一个内存 方向 是自下向上

SQL Server OS在NUMA硬件 将一份物理内存分成两份 方向 是自下向上

- 浅析NUMA体系结构
- NUMA体系结构详解
- NUMA体系结构详解
- NUMA体系结构详解
- NUMA体系结构简述
- SMP、NUMA、MPP体系结构介绍
- SMP、NUMA、MPP体系结构介绍
- SMP、NUMA、MPP体系结构介绍
- SMP,NUMA,MPP体系结构介绍
- SMP、NUMA、MPP体系结构介绍
- SMP、NUMA、MPP体系结构介绍
- SMP、NUMA、MPP体系结构介绍
- SMP、NUMA、MPP体系结构介绍
- SMP、NUMA、MPP体系结构介绍
- SMP、NUMA、MPP体系结构介绍
- SMP、NUMA、MPP体系结构介绍
- SMP、NUMA、MPP体系结构介绍
- SMP、NUMA、MPP体系结构介绍
- 二元属性的邻近性度量
- PHP Cookie与Session的使用与区别
- nodejs自学资料
- C 语言 json 库的基本用法
- 【Rayeager PX2分享】最简单helloworld驱动编写
- 浅析NUMA体系结构
- HTML CSS + DIV实现整体布局
- 【JAVA】使用 iText XMLWorker实现HTML转PDF
- Android系统介绍
- 关于stdClass
- Android与IOS的后台与推送对比
- 方法重写一定要注意的
- Linux系统上nginx+tomcat分布式的安装与配置
- EXC2618N LED矩阵驱动程序


