台大机器学习基石笔记(二)——VC 维1
来源:互联网 发布:攻击地图源码 编辑:程序博客网 时间:2024/06/05 16:49
本文基于http://beader.me/的博客进行编写,有些的地方我做了简单修改,公式也重新敲了,加深一下理解。
上一篇讲到,learning的时候如果遇上bad sample,如果遇上bad sample我们就无法保证
- 能不能确保E_in(g)和E_out(g)很接近?(Hypothesis Set中方程的个数会不会太多,用来训练的数据量够不够大)
- 能不能使E_in(g)足够小?(Hypothesis Set中方程的个数会不会太少)
这里我们便遇到了一个两难的选择:
如果M很小,根据
ℙ[BAD]≤2Mexp(...) ,第1个问题,“很接近”,做的不错。但是对于第2个问题,由于选择性太少,很难找到Ein(g) 较小的g 。(想象一下如果数据是由一个二次方程所产生,而Hypothesis Set当中只有直线方程可以选)如果M很大,我们选择方程的时候更加自由(自由度),更有机会选到E_in很低的方程。但这个时候根据公式,我们遇到bad
sample的可能性也大大增加。
因此这篇笔记主要围绕公式中这个M展开:
有效的方程 (Effective Number of Hypotheses)
让我们来回忆下这个M是从哪里来的。记
但事实上bad event并不是完全独立的。想象
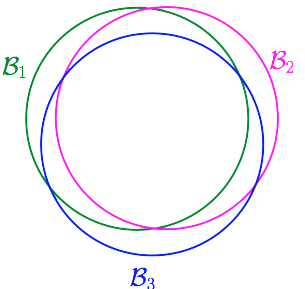
那么我们就会想,我们能不能把结果接近的那些方程看成一类,譬如有些方程他们的预测结果总是相同或是很接近的。
假设我们的算法要在平面上挑选一条直线方程作为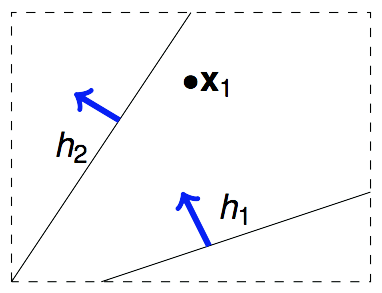
那如果我们手中有2个数据点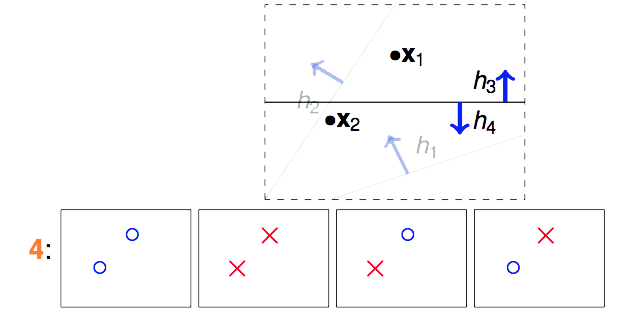
那如果我们手中有3个数据点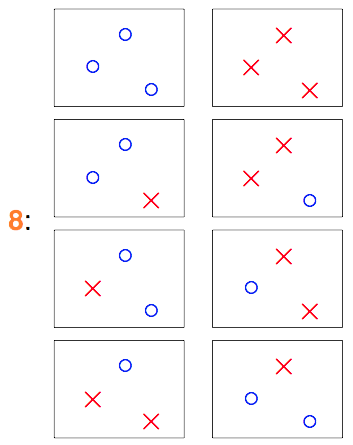
那如果我们手中有4个数据点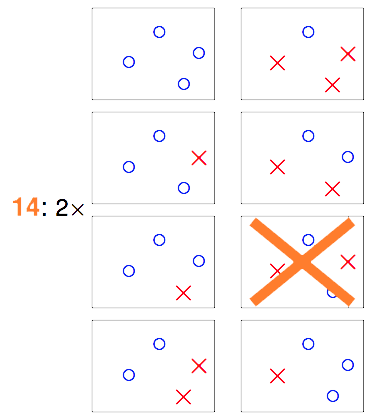
在这16种组合中,就有两种是“直线方程”没有办法产生的结果。因此如果是2维空间中的所有直线,表面上看是在无数条直线方程中去挑,但由于大部分直线方程所产生的结果是一模一样的,结果不一样的直线的类别对应上面的例子分别为2类、4类、8类和14类(Effective Number of Lines)。属于同一类的直线,他们将同时遇到或不遇到bad sample,由于之前那个union bound是基于独立性的假设下的,因此遭遇bad sample的概率明显被夸大了。所以,我们应该把不等式改写为:
作用于能够产生多少不同的结果? (Dichotomies)
从
因此我们前面要找的
=平面中能找出多少条不同类的直线
=
因为不一定所有排列组合都能成为dichotomy,所以不同的dichotomy的数量一定不会超过排列组合数
=
成长函数 (Growth Function)
那么,
上式又称为成长函数(growth function)。在
1.Positive Rays

输入空间为一维实数空间。大于threshold a的预测+1,否则预测-1。 for example: 当N=4时,Positive Rays作用于
不难去想,4个点,5个可能的切点,最多产生5种dichotomies。因此Positive Rays的成长函数为:
2.Positive Intervals

和前面的类似,只不过Positive Intervals有两个threshold,夹在两个threshold之间的预测为+1,其余预测为-1。 for example: 当N=4时,Positive Intervals作用于x_1~x_4,共能产生11种dichotomies。如下图: 
同样不难去想,4个点,5个可能的切点选两个作为threshold,加上两个threshold重合产生的一种,因此Positive Intervals的成长函数为:
3.Convex Sets
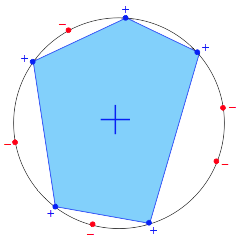
任选k个点,在这k个点组成的convex多边形包围内的所有点都预测+1,否则预测-1。前面我们说到成长函数描述的是“最多”能产生的dichotomy种数,因此如果我们这N个input摆成一个圈,则这N个点的任意一种排列组合都能成为一个dichotomy。因此Convex Sets的成长函数为:
坏掉的散弹枪 (Shatter & Break)
当
这个shatter的意思似乎不太好理解,这是林老师在讨论区中的回复:
“大家對 break point 的討論很好,不過注意到 shatter 的原意是「打碎」,在此指「
我(原作者)从打游戏过关的角度去理解,shatter作打碎理解:
“
对于给定的成长函数
不难根据成长函数得出Positive Rays成长函数的break point为2,Positive Intervals成长函数的break point为3,Convex Sets不管N多大都可以去shatter掉那N个点,因此它的成长函数没有break point。2D Perceptrons的break point为4,因为在N=3时,它都能够shatter,产生23=8种dichotomies,当N=4时,它不能够shatter,最多只能产生
其实我认为就是:能包括全部可能性。
拿什么来镇镇成长函数 (Restriction of Break Point)
有些
先用例子来看看,当我们完全不知道
举例说明,假设我们不知道某个
从k=2我们可以知道,任意2个数据点都不能被shatter。还记得shatter的概念吗?意思就是我产生的dichotomies不能完全包含任何2个数据点所有的排列组合。让我们从1个dichotomy开始。
1 dichotomy 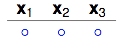
2 dichotomies 
3 dichotomies 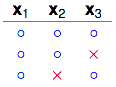
注意看
4 dichotomies 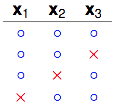
看右边两列,x_2和x_3被shatter了。但之前说了k=2,即任意2个点不能被shatter,因此不可能产生这4种dichotomies。那我们换一个dichotomy试试看。
4 dichotomies
换了一个dichotomy之后就行了,右边2列只包含了
5个dichotomies的情形这里就不再画出来了,很容易看出不管增加怎样的dichotomy进去,都会有两个点被shatter掉。因此这里“最多最多”只能有4种dichotomies。因此N=3,k=2时的upper bound是4。我们用
美妙的地方马上就要到了,虽然很多时候我们无法直接得到成长函数
前面我们已知了
- k=1时,1个点(2种排列组合)都没有办法shatter,因此B(?,1)恒等于1。
- k>N时,一定能shatter掉N个点,因此它产生的dichotomies的种类等于这N个点所有的排列组合数2N。
- k=N时,从2N个排列组合中移除掉一个,剩下的都可以作为dichotomies,因此它产生的dichotomies的数量“最多最多”可以是
2N−1 。
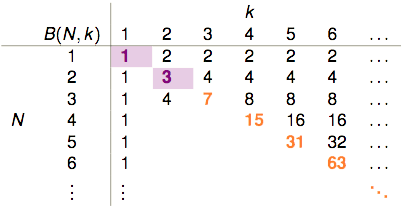
表格剩余的部分该如何填补?B(4,3)是否与B(3,?)有关呢?
此时某某实验室帮老师抛硬币的研究生要上场了,他穷举了所有可能的dichotomies,发现B(4,3)=11,以下是他的研究成果: 
我们把这份结果做个排序: 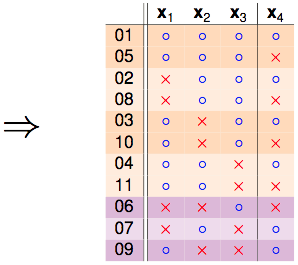
发现秘密了没有,橙色的部分是成对出现的,只有紫色的部分是单独出现的:
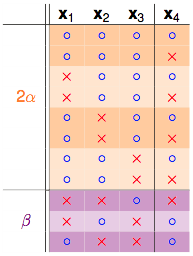
1.果拿掉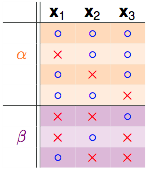 如
如
α+β部分可以成为这3个点的dichotomies,因为k=3,所以任3个点不能够被shatter,因此有::
2.再来看剩下一个α的部分: 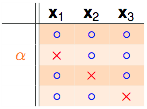
注意α是之前成对存在的部分,并且α部分不可以shatter掉任意2个点,因为如果α部分的dichotomies可以shatter掉任意2个点,他每一行都再搭配
综合上面两个不等式,我们可以得到:
这样就能够把前面那张表给填完整:
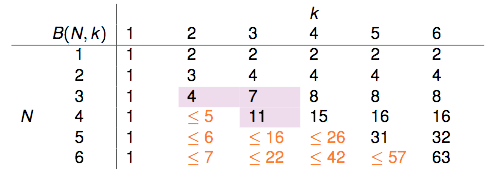
用数学归纳法可以证明:
当k=1时不等式恒成立,因此只要讨论k≥2的情形。N=1时,不等式成立,假设
因此当
成长函数的上界
By the way,右手边(RHS)实际上是一个最高次项为k-1次的多项式。以2D Perceptrons为例,它的break point k=4,则它的成长函数会被B(N,4)给bound住:
总结
上一篇说的learning的可行性,讲到,如果遇上bad sample,
但实际上我们很难确切知道各种{H}的成长函数m_{H(N)}究竟长什么样子,我们只好通过break point去寻找成长函数的upper bound。不过这当中仍然有些情况没有考虑到,将在下一篇笔记中继续说明。
- 台大机器学习基石笔记(二)——VC 维1
- 台大机器学习基石笔记(三)——VC 维2
- 台大机器学习基石笔记(四)——VC 维3
- 台大机器学习基石笔记(一)——机器学习可行性
- 台大机器学习基石学习笔记
- 台大-林轩田老师-机器学习基石学习笔记1
- 台大-林轩田老师-机器学习基石学习笔记2
- 台大-林轩田老师-机器学习基石学习笔记3
- 台大-林轩田老师-机器学习基石学习笔记4
- 台大-林轩田老师-机器学习基石学习笔记5
- 台大-林轩田老师-机器学习基石学习笔记6
- 台大-林轩田老师-机器学习基石学习笔记7
- 台大-林轩田老师-机器学习基石学习笔记8
- 台大-林轩田老师-机器学习基石学习笔记9
- 台大-林轩田老师-机器学习基石学习笔记10
- 台大-林轩田老师-机器学习基石学习笔记11
- 机器学习基石学习笔记3 VC Dimension(1)
- 台大机器学习听课笔记---基石 9-1 Linear Regression
- ROWNUM 与 ROW_NUMBER()OVER() 的区别
- C#使用Log4Net记录日志
- C#设计模式学习之【单例模式】
- HTML基础介绍二(图像和超级链接)
- ReactiveCocoa - iOS开发的新框架
- 台大机器学习基石笔记(二)——VC 维1
- ipv6 记录1
- poi导入导出excel文件,兼容.xls和.xlsx两种格式
- STL - priority_queue(优先队列)
- 分布式音视频服务器之登陆
- unity3d相机跟随物体平滑移动(C#代码)
- 242 计算球体积
- 《权威指南》笔记 - 9.1-9.2 类和原型、构造函数
- AndroidManifest.xml——path-permission


