机器学习性能评估指标
来源:互联网 发布:大嘴猴淘宝旗舰店 编辑:程序博客网 时间:2024/06/05 19:27

分类
混淆矩阵1
- True Positive(真正, TP):将正类预测为正类数.
- True Negative(真负 , TN):将负类预测为负类数.
- False Positive(假正, FP):将负类预测为正类数
→ →误报 (Type I error). - False Negative(假负 , FN):将正类预测为负类数
→ →漏报 (Type II error).
.png)
精确率(precision)定义为:
需要注意的是精确率(precision)和准确率(accuracy)是不一样的,
在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc 也有 99% 以上,没有意义。
召回率(recall,sensitivity,true positive rate)定义为:
此外,还有
精确率和准确率都高的情况下,
F 1 F1 值也会高。
通俗版本
刚开始接触这两个概念的时候总搞混,时间一长就记不清了。
实际上非常简单,精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),也就是
而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。

在信息检索领域,精确率和召回率又被称为查准率和查全率,
ROC 曲线
我们先来看下维基百科的定义,
In signal detection theory, a receiver operating characteristic (ROC), or simply ROC curve, is a graphical plot which illustrates the performance of a binary classifier systemas its discrimination threshold is varied.
比如在逻辑回归里面,我们会设一个阈值,大于这个值的为正类,小于这个值为负类。如果我们减小这个阀值,那么更多的样本会被识别为正类。这会提高正类的识别率,但同时也会使得更多的负类被错误识别为正类。为了形象化这一变化,在此引入 ROC ,ROC 曲线可以用于评价一个分类器好坏。
ROC 关注两个指标,
直观上,TPR 代表能将正例分对的概率,FPR 代表将负例错分为正例的概率。在 ROC 空间中,每个点的横坐标是 FPR,纵坐标是 TPR,这也就描绘了分类器在 TP(真正率)和 FP(假正率)间的 trade-off2。

AUC
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。
The AUC value is equivalent to the probability that a randomly chosen positive example is ranked higher than a randomly chosen negative example.
翻译过来就是,随机挑选一个正样本以及一个负样本,分类器判定正样本的值高于负样本的概率就是 AUC 值。
简单说:AUC值越大的分类器,正确率越高3。
AUC=1 AUC=1,完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。0.5<AUC<1 0.5<AUC<1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。AUC=0.5 AUC=0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。AUC<0.5 AUC<0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测,因此不存在AUC<0.5 AUC<0.5 的情况。

回归4
平均绝对误差
平均绝对误差MAE(Mean Absolute Error)又被称为
平均平方误差
平均平方误差 MSE(Mean Squared Error)又被称为
线面在对ROC进行下具体的iiehhao
ROC曲线指受试者工作特征曲线 / 接收器操作特性曲线(receiver operating characteristic curve), 是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。在ROC曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
ROC曲线的例子
考虑一个二分问题,即将实例分成正类(positive)或负类(negative)。对一个二分问题来说,会出现四种情况。如果一个实例是正类并且也被 预测成正类,即为真正类(True positive),如果实例是负类被预测成正类,称之为假正类(False positive)。相应地,如果实例是负类被预测成负类,称之为真负类(True negative),正类被预测成负类则为假负类(false negative)。
TP:正确肯定的数目;
FN:漏报,没有正确找到的匹配的数目;
FP:误报,给出的匹配是不正确的;
TN:正确拒绝的非匹配对数;
列联表如下表所示,1代表正类,0代表负类。 预测 10合计实际1True Positive(TP)False Negative(FN)Actual Positive(TP+FN) 0False Positive(FP)True Negative(TN)Actual Negative(FP+TN)合计 Predicted Positive(TP+FP)Predicted Negative(FN+TN)TP+FP+FN+TN从列联表引入两个新名词。其一是真正类率(true positive rate ,TPR), 计算公式为TPR=TP/ (TP+ FN),刻画的是分类器所识别出的 正实例占所有正实例的比例。另外一个是负正类率(false positive rate, FPR),计算公式为FPR= FP / (FP + TN),计算的是分类器错认为正类的负实例占所有负实例的比例。还有一个真负类率(True Negative Rate,TNR),也称为specificity,计算公式为TNR=TN/ (FP+ TN) = 1-FPR。

其中,两列True matches和True non-match分别代表应该匹配上和不应该匹配上的
两行Pred matches和Pred non-match分别代表预测匹配上和预测不匹配上的
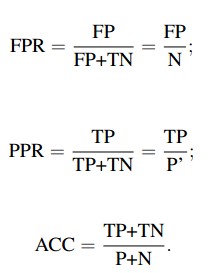
在一个二分类模型中,对于所得到的连续结果,假设已确定一个阀值,比如说 0.6,大于这个值的实例划归为正类,小于这个值则划到负类中。如果减小阀值,减到0.5,固然能识别出更多的正类,也就是提高了识别出的正例占所有正例 的比类,即TPR,但同时也将更多的负实例当作了正实例,即提高了FPR。为了形象化这一变化,在此引入ROC,ROC曲线可以用于评价一个分类器。
ROC曲线和它相关的比率
(a)理想情况下,TPR应该接近1,FPR应该接近0。
ROC曲线上的每一个点对应于一个threshold,对于一个分类器,每个threshold下会有一个TPR和FPR。
比如Threshold最大时,TP=FP=0,对应于原点;Threshold最小时,TN=FN=0,对应于右上角的点(1,1)
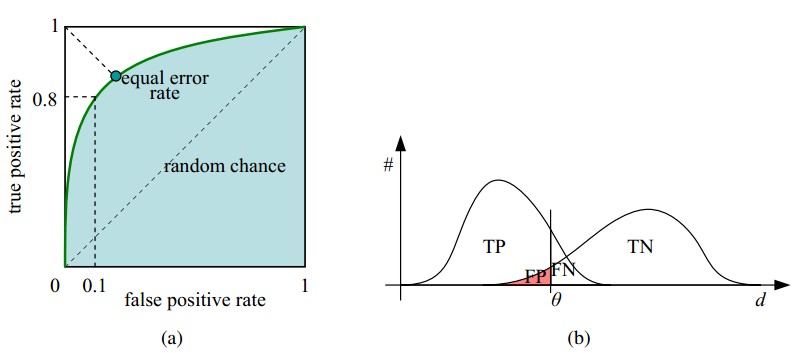
(b)P和N得分不作为特征间距离d的一个函数,随着阈值theta增加,TP和FP都增加
Receiver Operating Characteristic,翻译为"接受者操作特性曲线",够拗口的。曲线由两个变量1-specificity 和 Sensitivity绘制. 1-specificity=FPR,即负正类率。Sensitivity即是真正类率,TPR(True positive rate),反映了正类覆盖程度。这个组合以1-specificity对sensitivity,即是以代价(costs)对收益(benefits)。
此外,ROC曲线还可以用来计算“均值平均精度”(mean average precision),这是当你通过改变阈值来选择最好的结果时所得到的平均精度(PPV).
下表是一个逻辑回归得到的结果。将得到的实数值按大到小划分成10个个数 相同的部分。 Percentile实例数正例数1-特异度(%)敏感度(%)10618048792.7334.6420618028049.8054.55306180216518.2269.92406180150628.0180.6250618098738.9087.6260618052950.7491.3870618036562.9393.9780618029475.2696.0690618029787.5998.171006177258100.00100.00其正例数为此部分里实际的正类数。也就是说,将逻辑回归得到的结 果按从大到小排列,倘若以前10%的数值作为阀值,即将前10%的实例都划归为正类,6180个。其中,正确的个数为4879个,占所有正类的 4879/14084*100%=34.64%,即敏感度;另外,有6180-4879=1301个负实例被错划为正类,占所有负类的1301 /47713*100%=2.73%,即1-特异度。以这两组值分别作为x值和y值,在excel中作散点图。
- 机器学习性能评估指标
- 机器学习性能评估指标
- 机器学习性能评估指标
- 机器学习性能评估指标
- 机器学习性能评估指标
- 机器学习性能评估指标
- 机器学习性能评估指标
- 机器学习性能评估指标 ROC
- 机器学习性能评估指标资料汇总
- 机器学习性能评估指标(综合性总结)
- 机器学习之评估指标
- 机器学习十一 评估指标
- 机器学习评估指标总结
- 机器学习模型评估指标
- 机器学习中常用评估指标汇总
- spark机器学习库评估指标总结
- 优达机器学习:评估指标
- 机器学习性能评估指标(精确率、召回率、ROC、AUC)
- WebApi有多个POSt方法。
- 想法很重要
- STM32学习--USART
- Wing IDE配置空格代替tab缩进+护眼背景色
- 如何解决:Android中 Error generating final archive: Debug Certificate expired on 10/09/18 16:30 的错误
- 机器学习性能评估指标
- NSRunLoop 概述和原理
- 编写程序输出每种内置类型的长度
- openSUSE中启动eclipse,但是无法启动中文输入法……
- Entity Framework Code First属性映射约定(转)
- RTMP SRS源与边界的实现
- iOS中用正则表达式验证邮箱和手机号
- javaScript 删除确认实现方法总结分享
- 视频压缩中IPB帧概念


