基本数据结构和算法回顾
来源:互联网 发布:网络摄像头ip地址扫描 编辑:程序博客网 时间:2024/06/03 06:43
转载于 http://www.cnblogs.com/lvyahui/p/4693373.html
链表
链表是一种非常基本的数据结构,被广泛的用在各种语言的集合框架中。
首先链表是一张表,只不过链表中的元素在内存中不一定相邻,并且每个元素都可带有指向另一个元素的指针。
链表有,单项链表,双向链表,循环链表等。
单项链表的数据结构
typedef struct NODE{ struct NODE * link; int value; } Node;对链表的操作
主要有增删查
Node * create(){ Node * head,* p,* tail; // 这里创建不带头节点的链表 head=NULL; do { p=(Node*)malloc(LEN); scanf("%ld",&p->value); if(p->value ==0) break; // 第一次插入 if(head==NULL) head=p; else tail->link=p; tail=p; } while(1); tail->link=NULL; return head;}int delet(Node **linkp,int del_value){ register Node * current; Node * m_del; //寻找正确的删除位置,方法是按顺序访问链表,直到到达等于的节点 while((current = *linkp)!=NULL && current->value != del_value) { linkp = ¤t->link; } if(NULL==current) return FALSE; else { //把该节点删除,返回TRUE m_del=current->link; free(current); *linkp=m_del; } return TRUE;}//需要形参为链表头指针的地址和要插入的值int insert(Node **linkp,int new_value){ register Node * current; Node * m_new; //寻找真确的插入位置,方法是按顺序访问链表,直到到达其值大于或等于新插入值的节点 while((current = *linkp)!=NULL && current->value < new_value) { linkp = ¤t->link; } //为新节点分配内存,并把新值存到新节点中,如果分配失败,返回FALSE m_new =(Node*)malloc(LEN); if(NULL==m_new) return FALSE; m_new->value = new_value; //把新节点放入链表,返回TRUE m_new->link = current; *linkp=m_new; return TRUE;}仅仅只需要将尾指针指向头节点,就可以构成单项循环链表,即tail->link=head;,有的时候,可能需要将链表逆置,当然,如果需要逆置,最好一开始就做双向链表。
Node * reverse(Node * head){ Node * p,*q; q= head; p = head->link; head = NULL; while(p) { // 接到新链表里面去 q->link = head; head = q; // 继续遍历原来的链表 q = p; p = p->link; } q->link = head; head = q; return head;}删除链表中所有值为x的节点,以及清除链表中重复的节点
// 功能: 删除链表中所有值为x的节点// 形参: 1、若不带头结点,便是链表头指针的地址,即&head// 2、若带头结点,便是链表头节点的next域的地址,即&head->next// 形参: 为链表头指针的地址和要删除的值void del_link(Node ** plink,int x){ register Node * current; while((current = *plink)!=NULL) { // 处理连续出现x的情况 while(current && current->data == x){ // 保留指向下一个节点的指针 Node * temp = current; * plink = current = current->next; // 删除当前节点 free(temp); } //向下遍历链表 if (current) { plink = ¤t->next; } }}// 功能: 删除链表中重复多余的节点// 形参: 1、若不带头结点,便是链表头指针的地址,即&head// 2、若带头结点,便是链表头节点的next域的地址,即&head->nextvoid del_linkAll(Node ** plink){ register Node * current; while((current = *plink) != NULL){ //注意,这里取指向下一个元素的指针的地址,这样删除是会保留这一个节点 del_link(¤t->next,current->data); plink = ¤t->next; }}对于双向链表,也就是在节点中再添加一个节点,让它与另一个指针指向的方向相反。当然,当节点有了两个节点之后,就可以构成更复杂的比如树图等复杂结构了,双向链表可像如下定义
#ifndef __LINKLISTEX_H__#define __LINKLISTEX_H__#include <string>using std::string;//================双向链表的定义===============template<class T>class DulLinkList{private: typedef struct DulNode{ struct DulNode * prior; T data; struct DulNode * next; }DulNode; DulNode * frist; void Init(); void Del(DulNode * delNode);public: DulLinkList(); ~DulLinkList(); void AddElem(const T & data); void DelElem(const T & data); string ToString()const;protected:};#endif//__LINKLISTEX_H__对双向链表的操作也无外乎增删改
#include "LinkListEx.h"#include <iostream>using namespace std;template<class T>DulLinkList<T>::DulLinkList(){ Init();}template<class T>void DulLinkList<T>::Init(){ // 初始化第一个结点 this->frist = new DulNode; this->frist->prior = NULL; this->frist->next = NULL;}template<class T>void DulLinkList<T>::AddElem(const T & data){ // 直接头部插入节点 DulNode * newNode = new DulNode; newNode->data = data; newNode->next = this->frist; newNode->prior = NULL; this->frist->prior = newNode; this->frist = newNode;}template<class T>void DulLinkList<T>::DelElem(const T & data){ DulNode * current = this->frist->next; while (current != NULL && current->data != data) { current = current->next; } if (!current) { return; } Del(current);}template<class T>void DulLinkList<T>::Del(DulNode * delNode){ // 调整当前节点两端的节点的指针 delNode->prior->next = delNode->next; delNode->next->prior = delNode->prior; delete delNode;}template<class T>DulLinkList<T>::~DulLinkList(){ DulNode * current = this->frist; while (current) { DulNode * old = current; current = current->next; delete old; }}template<class T>string DulLinkList<T>::ToString()const{ string res; DulNode * current = this->frist->next; while (current) { res.append(1,current->data); current = current->next; } return res;}链表是个很基础的东西,后面一些复杂的算法或数据结构的本质也是一个链表。链表和顺序表(也就是数组)都可以再进一步抽象成更复杂的数据结构。
比如队列和栈,不过是在链表或顺序表的基础上限制单端操作而已。再比如,由链表和顺序表还可以构成二叉树堆,它们还可以组合使用构成邻接表,十字链表,邻接多重表等结构用来描述图,等等。
字符串相关算法
首先最基本的是对字符串的求长,连接,比较,复制等
// 统计字符串长度int str_len(char *str){ return *str ? str_len(str+1)+1 : 0 ;}// 字符串复制void str_cpy(char *str1,char *str2){ while(*str1++ = *str2++); //当str2指向'\0'时,赋值给*str1 表达式的值为0 即为假。退出循环 //if(*str1 == '\0') // 考虑到 串2的长度大于串1的长度,防止指针越界 //break;}// 字符串比较int str_cmp(char *str1,char *str2){ int i;// i指向字符不同时数组下标 for(i=0;str1[i]==str2[i] && str1[i]!='\0' && str2[i]!='\0';i++); return str1[i]-str2[i];}// 字符串连接void str_cat(char *str1,char *str2){ while(*str1 != '\0') str1++; while(*str1++ = *str2++);}字符串比较复杂一点的就是模式匹配和子序列(编辑距离)的问题。
首先是较为简单的BF算法,这种算法原理非常简单,比如连个串a(主串)和b(模式串),首先将a1和b1进行比较,如果相同,则将b2与a2进行比较,如果还相同,继续拿a3与b3比,直到b串匹配完,怎匹配完成,如果出现不同的,怎回到最初的状态,将b1与a2进行比较,将b2与a3比较,等等,如此反复直到失败或成功。
typedef struct{ char * str; int length;}String;int Index_BF(String mainStr,String modeStr,int pos){ int i = pos-1; int j = 0; while (i<mainStr.length && j<modeStr.length) { if (mainStr.str[i] == modeStr.str[j]) { i++,j++; } else{ // 出现不同的,回退到模式第一个字符的状态,将模式右移进行匹配 i = i - j + 2; j = 0; } } if (j==modeStr.length) { return i - modeStr.length; } else{ return 0; }}较为复杂的算法是KMP算法,KMP算法的关键是避免BF算法中的回朔。并且当匹配失败后向右滑动到一个能自左最大对齐的位置继续匹配。
**若在ai,bj的位置匹配失败,所以已经匹配的串便是
B1 B2 … Bj-1 == Ai-j+1 Ai-j+2 … Ai-1;
假设滑动完后要让Bk与Ai对齐,则应该有
B1 B2 B3 … Bk-1 == Ai-k+1 A-k+2 … Ai-1;
因为是向右滑动,想一想i的位置不变,B向右滑动,很显然,k要小于j。
所以进一步可以得到k到j之间B的子串(Bj前面的k-1个字符)与Ai前的k-1个字符是相同的,即
Bj-k+1 Bj-k+2 … Bj-1 == Ai-k+1 Ai-k+2 … Ai-1;
所以有
B1 B2 B3 … Bk-1 == Bj-k+1 Bj-k+2 … Bj-1
可以看出来,这个有个特点,字符串 B1 B2 ….. Bj-1关于Bk有种对称的感觉,不过这个不是镜像对称,不过我还是喜欢这么记对称,这也是求next值的依据,这个next就是k,就是偏移值**
next(j) = 0 (j==1) || max{k|1<=k
void GetNext(const char * mode,int * next){ //求模式mode的next值并存入数组next中 int i=1,j=0; next[1] = 0; while(i < mode[0]){ if(0 == j || mode[i] == mode[j]){ i++;j++; next[i] = j; } else j = next[j]; }}int Index_KMP(const char * str,const char * mode,int pos){ int i=pos,j=1; int * next = (int *)malloc(sizeof(int)*(mode[0]+1)); next[0]=mode[0]; GetNext(str,next); while (i<=str[0] && j<= mode[0]) { if (0==j || str[i] == mode[j]) { i++;j++; } else{ // 滑动模式串,注意next[j]是小于j的,这才是向右滑动 j = next[j]; } } return j>mode[0] ? i - mode[0] : 0;}void main(){ char string[16] = "\016abcabcabaabcac"; char mode[10] = "\010abaabcac"; printf("模式串在主串中的位置:%d\n",Index_KMP(string,mode,1));}二叉树
树这里主要以二叉树为例,二叉树算是一种特殊的树,一种特殊的图。
二叉树具备如下特征
- 第i层最多有2^(i-1)次方个节点
- 深度为k的树最多有2^i-1个节点,也就是满二叉树等比求和
n0=n2+1,即叶子节点的数量恰好是度为2的节点数加1,主要原因是节点数总比度数多1,因为根节点没有入度,所以有 n0 + n1 + n2 -1 = n1 + 2*n2。 - 对于满二叉树,如果以有序表存储,根节点放在0的位置上,左右孩子放在1,2上,相当于从上到下,从左到右,从0开始对节点进行编号,则对于节点i,它的左孩子应该位于2*i+1上,右孩子位于2*i+2上
用数组和链表都可以存储二叉树,但我见过的算法大都用数组存储二叉树,想必链表虽然易于理解,但相比写起算法来未必好写。
对二叉树的操作
有增删查遍历等操作
typedef struct bitnode{ int m_iDate; struct bitnode * m_lChild/*左孩子指针*/,* m_rChild/*右孩子指针*/; } CBiTNode;//建立一个带头结点的空的二叉树CBiTNode * Initiate(){ CBiTNode * bt; bt = (CBiTNode*)malloc(sizeof CBiTNode); bt->m_iDate = 0; bt->m_lChild = NULL; bt->m_rChild = NULL; return bt;}/*//建立一个不带头结点的空的二叉树CBiTNode * Initiate(){ CBiTNode * bt; bt = NULL; return bt;}*///生成一棵以x为根节点数据域信息,以lbt和rbt为左右子树的二叉树CBiTNode * Create(int x,CBiTNode * lbt,CBiTNode * rbt){ CBiTNode * p; if((p=(CBiTNode*)malloc(sizeof CBiTNode)) ==NULL) return NULL; p->m_iDate = x; p->m_lChild = lbt; p->m_rChild = rbt; return p;}//在二叉树bt中的parent所指节点和其左子树之间插入数据元素为x的节点bool InsertL(int x,CBiTNode * parent){ CBiTNode * p; if(NULL == parent){ printf("L插入有误"); return 0; } if((p=(CBiTNode*)malloc(sizeof CBiTNode)) ==NULL) return 0; p->m_iDate = x; p->m_lChild = NULL; p->m_rChild = NULL; if(NULL == parent->m_lChild) parent->m_lChild = p; else{ p->m_lChild = parent->m_lChild; parent->m_lChild = p; } return 1;}//在二叉树bt中的parent所指节点和其右子树之间插入数据元素为x的节点bool InsertR(int x,CBiTNode * parent){ CBiTNode * p; if(NULL == parent){ printf("R插入有误"); return 0; } if((p=(CBiTNode*)malloc(sizeof CBiTNode)) ==NULL) return 0; p->m_iDate = x; p->m_lChild = NULL; p->m_rChild = NULL; if(NULL == parent->m_rChild) parent->m_rChild = p; else{ p->m_rChild = parent->m_rChild; parent->m_rChild = p; } return 1;}//在二叉树bt中删除parent的左子树bool DeleteL(CBiTNode *parent){ CBiTNode * p; if(NULL == parent){ printf("L删除出错"); return 0; } p = parent->m_lChild; parent->m_lChild = NULL; free(p);//当*p为分支节点时,这样删除只是删除了子树的根节点。子树的子孙并没有被删除 return 1;}//在二叉树bt中删除parent的右子树bool DeleteR(CBiTNode *parent){ CBiTNode * p; if(NULL == parent){ printf("R删除出错"); return 0; } p = parent->m_rChild; parent->m_rChild = NULL; free(p);//当*p为分支节点时,这样删除只是删除了子树的根节点。子树的子孙并没有被删除 return 1;}//二叉树的遍历//先序遍历二叉树bool PreOrder(CBiTNode * bt){ if(NULL == bt) return 0; else{ printf("bt->m_iDate == %d\n",bt->m_iDate); PreOrder(bt->m_lChild); PreOrder(bt->m_rChild); return 1; }}对二叉树可以有先序遍历,中序遍历,后序遍历得到的序列中每个元素互第一个和最后一个节点外都会有一个前驱和后驱节点。如果把前驱节点和后驱节点的信息保存在节点中就构成了线索二叉树,显然只要免礼一遍就能得到线索二叉树。
二叉树比较经典的有哈夫曼编码问题,二叉堆等问题,二叉堆放到堆排序一起讲。
哈夫曼问题就是要让频率高的节点编码最短,也就是要节点在哈夫曼树中的深度最小。
// Huffman.h#ifndef __HUFFMAN_H__#define __HUFFMAN_H__typedef struct { unsigned int weight; unsigned int parent,lchild,rchild;}HTNode,* HuffmanTree; // 动态分配数组储存哈夫曼树typedef char * *HuffmanCode; // 动态分配数组储存哈夫曼编码表#endif//__HUFFMAN_H__// HuffmanTest.cpp#include "Huffman.h"#include <string.h>#include <malloc.h>// 函数功能:在哈夫曼编码表HT[1...range]中选择 parent 为0且weight最小的两个结点,将序号分别存到s1和s2里void Select(const HuffmanTree &HT,int range,int &s1,int &s2){ int i; int * pFlags; pFlags = (int *)malloc((range+1)*sizeof(int)); int iFlags=0; for(i=1;i<=range;i++){ if(0 == HT[i].parent){ pFlags[++iFlags] = i; } } int Min=1000; int pMin=pFlags[1]; for(i=1;i<=iFlags;i++){ if(HT[pFlags[i]].weight < Min){ pMin = i; Min=HT[pFlags[i]].weight; } } s1=pFlags[pMin]; Min=1000; for(i=1;i<=iFlags;i++){ if(pFlags[i]!=s1) if(HT[pFlags[i]].weight < Min){ pMin = i; Min=HT[pFlags[i]].weight; } } s2=pFlags[pMin];}void HuffmanCoding(HuffmanTree &HT,HuffmanCode &HC,int * w, int n){ // w存放n个字符的权值(均>0),构造哈夫曼树HT,并求出n个字符的哈夫曼编码HC if(n <= 1) return; int m = 2*n-1; HT = (HuffmanTree)malloc((m+1)*sizeof(HTNode)); // 0 单元不使用 int i; HuffmanTree p=NULL; // 初始化哈夫曼编码表 for(p=HT+1,i=1;i<=n;i++,p++,w++){ p->weight = *w,p->parent = p->lchild = p->rchild = 0; } for( ;i<=m;i++,p++){ p->weight = p->parent = p->lchild = p->rchild = 0; } // 建立哈夫曼树 int s1,s2; for(i=n+1;i<=m;i++){ Select(HT,i-1,s1,s2); HT[s1].parent = HT[s2].parent = i; HT[i].lchild = s1,HT[i].rchild = s2; HT[i].weight = HT[s1].weight+HT[s2].weight; } // 从叶子节点到根逆向求每个字符的哈夫曼编码 HC = (HuffmanCode)malloc((n+1)*sizeof(char *)); // 分配n个字符编码的头指针向量 char * cd = (char*)malloc(n*sizeof(char)); // 分配求编码的工作空间 int start; // 编码起始位置 cd[n-1] = '\0'; // 编码结束符 for(i=1;i<=n;i++){ // 逐个字符求哈夫曼编码 start = n-1; // 将编码起始位置和末位重合 for(int c=i,f=HT[i].parent;f != 0; c=f,f=HT[f].parent){ if(c == HT[f].lchild) cd[--start] = '0'; else cd[--start] = '1'; } HC[i] = (char*)malloc((n-start)*sizeof(char)); // 为第i个字符编码分配空间 strcpy(HC[i],&cd[start]); // 从 cd 复制字符串到 HC } free(cd);}哈夫曼树的测试数据
#include "Huffman.h"#include <stdio.h>#include <stdlib.h>void HuffmanCoding(HuffmanTree &HT,HuffmanCode &HC,int * w, int n);void main(){ system("color F0"); HuffmanTree HT = NULL; HuffmanCode HC = NULL; char chArr[8]={'A','B','C','D','E','F','G','H'}; int w[8]={7,19,2,6,32,3,21,10}; HuffmanCoding(HT,HC,w,8); int i,j; printf( "HT weight parent lchild rchild\n"); for(i=1;i<=15;i++){ printf("%02d\t%2u\t%2u\t%2u\t%2u\n",i,HT[i].weight,HT[i].parent,HT[i].lchild,HT[i].rchild); } printf("\n\n字符 权值 编码\n"); for(i=0;i<8;i++){ printf("%c\t%2d\t%-8s\n",chArr[i],w[i],HC[i+1]); }}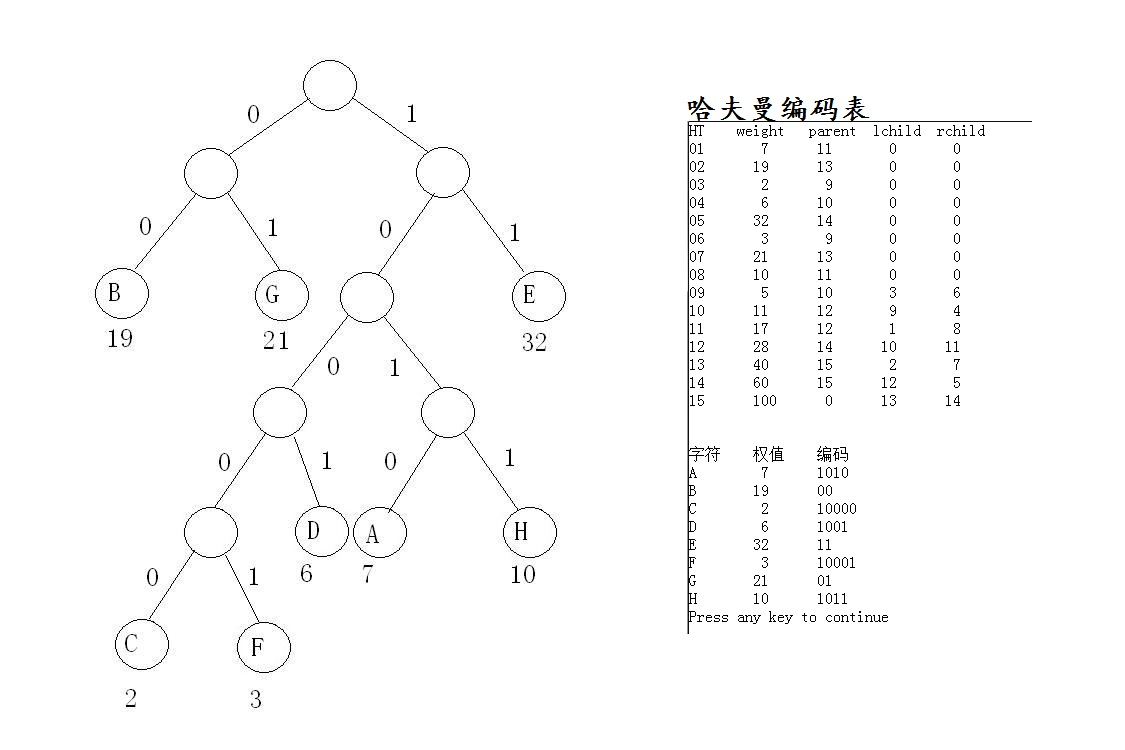
图相关算法
图的一些表示方法(存储结构)
- 邻接矩阵
- 对于一个又n个节点的图,邻接矩阵以一个n*n的二维数组a来描述图,对于不同的图,比如,有向图和无向图,带权图和无权图,a[i,j]表示的含义有所不同,但都是描述边的。
- 邻接表
- 邻接表组合使用数组和链表描述图,其中数组的每一个元素代表一个节点i,i由两部分组成,一部分代表节点的数据,另一部分为一个指向一链表,这个链表里存放着能从节点i出发能走到的所有节点。对于有向图和无向图会有不同的表示。邻接表一般要比领接矩阵更省空间,但它带来了求入度不便等问题。
- 十字链表
- 结合使用邻接表与逆邻接表,这种方式只能描述有向图。首先它也有一个数组,每个数据元素代表一个节点i,i由三部分组成,i在邻接表的基础上增加了一个指针,这个指针指向第一个以i为弧尾的及节点。这就很好的解决了求入度的问题。
- 邻接多重表
- 邻接多重表主要,它主要用来表描述无向图,在邻接表或十字链表中,数组元素的指针域指向的链表元素其实代表了边,如果用邻接表来存无向图,会使得一条边对应的两个节点分别位于两条链中,当我需要删除一条边时,总是需要找到另一个表示这条边的边节点,再删除。所以有了邻接多重表,邻接多重表就是只用一个边界点表示边,但是将它链接到两链表中(对,没有错,一个节点,同时存在于两个链表中)
下面是上面四种描述的代码表示
#ifndef __GRAPH_DEFINE_H__#define __GRAPH_DEFINE_H__#define INT_MAX 9999#define INFINITY INT_MAX // 最大值#define MAX_VERTEX_NUM 20 // 最大顶点个数#define VEX_FORM "%c" // 顶点输入格式#define INFO_FORM "%d" // 边信息输入格式typedef int InfoType; // 弧相关信息类型typedef char VextexType; // 顶点数据类型typedef int VRType; // 顶点关系类型,对无权图,用0或者1表示是否相邻。对带权图,则是权值类型。typedef enum { DG,DN,UDG,UDN} GraphKind;// 图类型 {有向图,有向网,无向图,无向网}//////////////////////////////////////////////////////////////////////////// 邻接矩阵存储结构: 可存储任意类型图//////////////////////////////////////////////////////////////////////////typedef struct{ VRType Adj; InfoType Info; // 该弧相关信息}ArcCell,AdjMatrix[MAX_VERTEX_NUM][MAX_VERTEX_NUM];typedef struct{ char cVexs[MAX_VERTEX_NUM]; // 顶点向量 AdjMatrix arcs; // 邻接矩阵 int iVexNum,iArcNum; // 图中当前顶点数和弧数 GraphKind kind; // 图的种类标志}MGraph;//////////////////////////////////////////////////////////////////////////// 邻接表存储结构: 可存储任意类型的图//////////////////////////////////////////////////////////////////////////typedef struct ArcNode{ int iAdjvex; // 该弧所指向的顶点位置 struct ArcNode *nextarc; // 指向下一条弧的指针 InfoType Info; // 该弧相关信息}ArcNode;typedef struct VNode{ VextexType cData; // 顶点信息 ArcNode *firstarc; // 指向第一条依附该顶点的弧的指针}VNode,AdjList[MAX_VERTEX_NUM];typedef struct { AdjList vertices; int iVexnum,iArcnum; // 图的当前顶点个数和弧数 GraphKind Kind; // 图的种类标志}ALGraph;//////////////////////////////////////////////////////////////////////////// 十字链表存储结构: 只存储有向图//////////////////////////////////////////////////////////////////////////typedef struct ArcBox{ int iTailVex,iHeadVex; // 该弧的尾和头顶点的位置 struct ArcBox *hLink,*tLink; // 分别为弧头相同和弧尾相同的链域 InfoType Info; // 该弧相关信息}ArcBox;typedef struct VexNode{ VextexType data; ArcBox *firstIn,*firstOut; // 分别指向了该顶点的第一条入弧和出弧}VexNode;typedef struct OLGraph{ VexNode xlist[MAX_VERTEX_NUM]; // 表头向量 int iVexNum,iArcNum; // 有向图当前顶点数和弧数}OLGraph;//////////////////////////////////////////////////////////////////////////// 邻接多重表: 存储无向图//////////////////////////////////////////////////////////////////////////typedef enum {unvisited,visited}VisitIf;typedef struct EBox{ VisitIf mark; // 访问标记 int iIVex,iJVex; // 边依附的两个顶点的位置 struct EBox *iLink,*jLink; // 分别指向依附这两个顶点的下一条边 InfoType Info; // 该边信息指针}EBox;typedef struct VexBox{ VextexType data; EBox *firstEdge; // 指向第一条依附该顶点的边}VexBox;typedef struct { VexBox adjmulist[MAX_VERTEX_NUM]; int iVexNum,iEdgeNum; // 无向图当前顶点数和边数}#endif//__GRAPH_DEFINE_H__图相关操作
对图的操作有创建,增删查等等,其中查就是遍历,遍历分为深度优先搜索和广度优先搜索。
深度优先搜索类似于树的钟旭遍历,即遇到未范围的节点,马上访问,修改标记数组,然后沿着这个节点继续访问,直到访问完,然后在回朔,转向未访问的分支。直到节点被访问完,如果是连通图,只要访问进行一次深度搜索,如果是非连通的,就要搜索多次。
广度优先搜索就像金字塔从上向下的一层一层的搜索,广度优先搜索除了需要用标记数组记录状态以外,还需要用队列来将发现而未访问的节点记录下来。用队列是为了保证遍历顺序。
下面是一些图相关的操作算法
#include <stdio.h>#include "GraphDefine.h"#include "Define.h"#include <malloc.h>//////////////////////////////////////////////////////////////////////////// 邻接矩阵图的相关操作//////////////////////////////////////////////////////////////////////////Status CreateDG(MGraph &G); // 构造有向图Status CreateDN(MGraph &G); // 构造有向网Status CreateUDG(MGraph &G); // 构造无向图Status CreateUDN(MGraph &G); // 构造无向网int LocateVex(const MGraph &G,const VextexType &v); // 获得顶点v在图中的位置Status CreateGraph(MGraph &G,VextexType v){ // 采用数组(邻接矩阵)表示法,构造图G int iType; scanf("%d%*c",&iType); G.kind = (GraphKind)iType; switch(G.kind) { case DG: return CreateDG(G); // 构造有向图 case DN: return CreateDN(G); // 构造有向网 case UDG:return CreateUDG(G); // 构造无向图 case UDN:return CreateUDN(G); // 构造无向网 default: return ERROR; }}Status CreateUDN(MGraph &G){ // 采用数组(邻接矩阵)表示法,构造网G int i,j,k; int IncInfo; scanf("%d %d %d",&G.iVexNum,&G.iArcNum,&IncInfo); for(i=0;i<G.iVexNum;++i) // 构造顶点向量 scanf("%c%*c",&G.cVexs[i]); for(i=0;i<G.iVexNum;i++){ for(j=0;j<G.iVexNum;j++){ // 初始化邻接矩阵 G.arcs[i][j].Adj = INFINITY; G.arcs[i][j].Info =NULL; } } VextexType v1,v2; int w; for(k=0;k<G.iArcNum;k++){ // 构造邻接矩阵 scanf("%c %c %d%*c",&v1,&v2,&w); i = LocateVex(G,v1),j = LocateVex(G,v2); // 确定v1,v2在G中的位置 G.arcs[i][j].Adj = w; // 弧<v1,v2>的权值 if(IncInfo) scanf(INFO_FORM,G.arcs[i][j].Info); G.arcs[j][i] = G.arcs[i][j]; // 置<v1,v2>对称弧<v2,v1> } return OK;}//////////////////////////////////////////////////////////////////////////// 十字链表图的相关操作//////////////////////////////////////////////////////////////////////////int LocateVex(const OLGraph &G,const VextexType &v); // 获得顶点v在图中的位置Status CreateDG(OLGraph &G){ // 采用十字链表存储表示,构造有向图 G(G.kind = DG) InfoType IncInfo; scanf("%d %d %d",G.iVexNum,G.iArcNum,&IncInfo); int i; for(i=0;i<G.iVexNum;i++){ // 构造表头向量 scanf(VEX_FORM "%*c",G.xlist[i].data); // 输入顶点值 G.xlist[i].firstIn = G.xlist[i].firstOut = NULL;// 初始化指针 } int k,j; VextexType v1,v2; ArcBox * p; for(k=0;k<G.iArcNum;k++){ // 输入各弧并构造十字链表 scanf(VEX_FORM VEX_FORM,&v1,&v2); // 输入一条弧的始点和终点 i = LocateVex(G,v1),j = LocateVex(G,v2); // 确定V1和 V2在G中的位置 p = (ArcBox*)malloc(sizeof(ArcBox)); // 假设有足够的空间 // 对弧节点赋值 p->iTailVex = v1,p->iHeadVex = v2; p->hLink = G.xlist[j].firstIn,p->tLink = G.xlist[i].firstOut; p->Info = NULL; G.xlist[j].firstIn = G.xlist[i].firstOut = p; // 完成在入弧与出弧的链头的插入 if(IncInfo) scanf(INFO_FORM,&p->Info); //若含有相关信息,则输入 } return OK;}//////////////////////////////////////////////////////////////////////////// 深度优先搜索//////////////////////////////////////////////////////////////////////////bool visited[MAX_VERTEX_NUM];Status(*VisitFunc)(int v);int FirstAdjVex(MGraph,int);int NextAdjVex(MGraph,int);void DFSTeaverse(MGraph G,Status (*Visit)(int v)){ int v; VisitFunc = Visit; for(v=0;v<G.iVexNum;v++) visited[v] = false; for(v=0;v<G.iVexNum;v++) if(!visited[v]) DFS(G,v);}void DFS(MGraph G,int v){ visited[v] = true; VisitFunc(v); int w; for(w = FirstAdjVex(G,v); w>0 ; w = NextAdjVex(G,v)) if(!visited[w]) DFS(G,w);}//////////////////////////////////////////////////////////////////////////// 广度优先搜索//////////////////////////////////////////////////////////////////////////// 队列相关函数void InitQueue(int []);void EnQueue(int []);bool QueueEmpty(int []);void DFSTeaverse(MGraph G,Status (*Visit)(int v)){ int v; for (v=0;v<G.iVexNum;v++) { visited[v] = false; } int Q[MAX_VERTEX_NUM]; InitQueue(Q); for(v=0;v<G.iVexNum;v++){ if(!visited[v]){ visited[v] = true; Visit(v); EnQueue(Q); while(!QueueEmpty(Q)){ int u,w; DeQueue(Q,u); for( w = FirstAdjVex(G,u); w>=0 ; w = NextAdjVex(G,u)) if(!visited[w]){ visited[w] = true; Visit(w); EnQueue(Q,w); } } } }}与图相关的还有很多算法,比如求最小生成树的prim算法和kruskal算法
prim算法初始化一个s集合,始终挑选与s集合相连最小的边连接的节点加到集合中,然后更新剩余节点到s的距离,直到所有的点添加进了s集合,prim算法代码如下
#include <stdio.h>#include <string.h>#define MAXN 1024#define INF 0xeFFFFFFFint e[MAXN][MAXN];int low[MAXN];bool inSet[MAXN];int n;int prim(){ int res=0,i,j,k; inSet[0] = true; memset(inSet,0,sizeof(inSet)); for(i=0;i<n;i++){ //现在所有点到S的距离就是到0的距离 low[i] = e[0][i]; } for(i=1;i<n;i++){ int minv = INF; int p = 0; //找出与集合s相连的最小的边 for(j=0;j<n;j++){ if(!inSet[j] && low[j] < minv){ minv = low[j],p = j; } } if(minv == INF) return -1;//非连通图 //将顶点j加到S里面 inSet[p] = true; //将最短路径加到结果里 res += low[p]; //更新low数组 for(k=0;k<n;k++){ if(!inSet && low[p] > e[p][k]){ low[p] = e[p][k]; } } } return res;}int main(void){ int i; scanf("%d",&n); for(i=0;i<n-1;i++){ int x,y,w; scanf("%d%d%d",&x,&y,&w); e[x][y] = e[y][x] = w; } int res = prim(); printf("%d\n",res); return 0;}Kruskal算法不断选取最小的边i,只要biani加进来不构成回路,则加入到边的集合e中来,直到加入的边能连接所有的顶点,则结束算法
#include <stdio.h>#include <string.h>#include <stdlib.h>#define MAXN 1024#define INF 0xeFFFFFFF//定义边的结构typedef struct Ele{ int x,y; //边的端点 int w; //边的权重 bool inSet;}Ele;Ele * eles[MAXN];//对于n个顶点,最多有n*(n-1)条边int m;//m条边int pa[MAXN];int r[MAXN];void make_set(){ int i; for(i=0;i<n;i++){ pa[i] = i; r[i] = 1; }}int find_set(int x){ if(x != pa[x]){ pa[x] = find_set(x); } return pa[x];}bool unin_set(int x,int y){ if(x==y) return; int xp = find_set(x); int yp = find_set(y); if(xp == yp) return false;//构成回路,不能合并 if(r[xp]>r[yp]){ pa[yp] = xp;//zhi小的放在zhi大的下面 } else{ pa[xp] = yp; if(r[xp] == r[yp]){ r[yp]++; } } return true;}void sort(){ int i,j; for(i=0;i<n-2;i++){ int p = i; for(j = i+1;j<n-1;j++){ if(eles[p].w > eles[j].w){ p = j; } } if(p!=i){ Ele * tmp = eles[i];eles[i] = eles[p];eles[p] = tmp; } }}/*int cmp(void * a,void * b){ return (Ele*)a->w - (Ele*)b->w;}*/int klske(){ //将边由小到大排序 //qsort(eles,sizeof(eles),sizeof(eles[0]),cmp) sort(); int res; for(int i=0;i<m;i++){ if(unin_set(find_set(eles[i].x),find_set(eles[i].y))){ printf("%d %d %d\n",else[i].x,eles[i].y,eles[i].w); } } return res;}int main(void){ int i; scanf("%d",&m); //eles = (Ele*)malloc(n*sizeof(Ele)); for(i=0;i<m-1;i++){ int x,y,w; scanf("%d%d%d",&x,&y,&w); eles[i] = (Ele*)malloc(sizeof(Ele)); eles[i]->x = x; eles[i]->y = y; eles[i]->w = w; eles[i]->inSet = false; } int res = klske(k); printf("%d\n",res); for(i=0;i<m-1;i++){ free(eles[i]); } return 0;}上面主要涉及的是一些数据结构,以及这些数据结构最基本的算法,下面进入算法部分
查找算法
树表查找
线索二叉树
线索二叉树要求任何几节点的左子树比该节点的值小,右子树的值比该节点大。二叉排序树,主要涉及的是插入和搜索
#include <stdio.h>#include <malloc.h>typedef struct bsTree{ int m_iDate; struct bsTree * m_lChild/*左孩子指针*/,* m_rChild/*右孩子指针*/;} * BsTree,BsNode ;BsTree insert(BsTree bs,int x){ BsNode * p = bs; BsNode * note = p; BsNode * ct = NULL; while(p){ if(x == p->m_iDate){ return p; } else{ // 记录上一个节点 note = p; if(x < p->m_iDate) p = p->m_lChild; else p = p->m_rChild; } } ct = (BsNode * )malloc(sizeof(BsNode)); ct->m_iDate = x; ct->m_rChild = NULL; ct->m_lChild = NULL; if(!bs){ bs = ct; }else if(x < note->m_iDate){ note->m_lChild = ct; }else note->m_rChild = ct; return bs;}BsNode * search(BsTree bs , int x){ if(!bs || bs->m_iDate == x){ return bs; }else if(x < bs->m_iDate){ return search(bs->m_lChild,x); }else{ return search(bs->m_rChild,x); }}有序表查找
二分查找
int binarySearch(int arr[],int l,int r,int key){ while(l<r){ int mid = (l+r) >> 1; if(arr[mid] > key){ r = mid -1; }else if(arr[mid] < key){ l = mid + 1; }else{ return mid; } } return -l-1; // 返回可插入位置}排序算法
冒泡排序
以升序为例,冒泡排序每次扫描数组,将逆序修正,每次恰好将最大的元素过五关斩六将推到最后,再在剩余的元素重复操作
void mpSort(int a[],int n){ int i,j,swaped=1; for(i=0;i<n-1 && swaped;i++){ swaped = 0; for(j=0;j<n-i;j++){ if(a[j] > a[j+1]){ swap(a[j],a[j+1]); swaped = 1; } } }}可见,冒泡排序的平均时间复杂度为O(n^2)
选择排序
以升序为例,每次扫描数组,找到最小的元素直接挪到第一个来,再在剩余的数组中重复这样的操作
void selectSort(int a[],int n){ int i,j; for(i=0;i<n-1;i++){ int p =i; for(j=i;j<n;j++){ if(a[p] > a[j]){ p = j; } } if(p != i){ swap(p,i); } }}选择排序的平均时间复杂度也是O(n^2)
直接插入排序
直接插入排序不断在前面已经有序的序列中插入元素,并将元素向后挪。再重取一个元素重复这个操作
#define MAXSIZE 20typedef int KeyType;typedef struct { KeyType key;}RedType;typedef struct{ RedType r[MAXSIZE+1]; int length;}SqList;//---------------------直接插入排序---------------------void InsertSort(SqList & L){ int i,j; for (i=2;i<=L.length;i++) { L.r[0] = L.r[i]; j = i -1; while (L.r[0].key < L.r[j].key) { L.r[j+1] = L.r[j]; j--; } L.r[j+1] = L.r[0]; }}插入排序的平均时间复杂度也是O(n^2)
堆排序
堆排序也是一种插入排序,不过是向二叉堆中插入元素,而且以堆排序中的方式存储二叉堆,则二叉堆必定是一棵完全二叉树,堆排序设计的主要操作就是插入和删除之后的堆调整,使得堆保持为大底堆或者小底堆的状态。也就是根节点始终保持为最小或最大,每次删除元素,就将根节点元素与最后元素交换,然后将堆的大小减1,然后进行堆调整,如此反复执行这样的删除操作。很显然,大底堆最后会得到递增序列,小底堆会得到递减序列。
/*** 堆调整* 在节点数为n的堆中从i节点开始进行堆调整*/void heapAjust(int arr[] ,int i,int n){ // 从i节点开始调整堆成为小底堆 int tmp = arr[i],min; // 左孩子,对于节点i,它的左孩子就是2i+1,右孩子就是2i+2; for(;(min = 2*i + 1)<n;i = min){ if(min+1 != n && arr[min] > arr[min+1]) min ++; if(arr[i] > arr[min]){ // 将小元素放置到堆顶 arr[i] = arr[min]; } else break; } arr[i] = tmp;}void heapSort(int arr[],int n){ // 建堆 int i; for(i=n>>1;i>=0;i--){ heapAjust(arr,i,n); } // 取堆顶,调整堆 for(i = n-1;i>0;i--){ // 每次取堆顶最小的元素与最后的元素交换,最后会得到递减序列 int tmp = arr[0];arr[0] = arr[i],arr[i] = tmp; // 删除一个元素后需要从根元素起重新调整堆 heapAjust(arr,0,i); }}快速排序
说到快排,就想起了大一上学期肖老师(教我C语言的老师)与我讨论的问题,当时懵懂无知,后才才知道那就是快排。
快排的思想也很简单,以升序为例,在序列中选一标杆,一般讲第一个元素作为标杆,然后将序列中比标杆小的元素放到标杆左边,将比标杆大的放到标杆右边。然后分别在左右两边重复这样的操作。
void ksort(int a[],int l,int r){ // 长度小于2有序 if(r - l < 2) return; int start = l,end = r; while(l < r){ // 向右去找到第一个比标杆大的数 while(++l < end && a[l] <= a[start]); // 向左去找第一个比标杆小的数 while(--r > start && a[r] >= a[start]); if(l < r) swap(a[l],a[r]); // 前面找到的两个数相对于标杆逆序 ,需交换过来 。l==r 不需要交换, } swap(a[start],a[r]);// 将标杆挪到正确的位置. // 对标杆左右两边重复算法,注意,这个l已经跑到r后面去了 ksort(a,start,r); ksort(a,l,end);}快速排序的平均时间复杂度为O(NLogN)
合并排序
合并排序采用分治法的思想对数组进行分治,对半分开,分别对左右两边进行排序,然后将排序后的结果进行合并。按照这样的思想,递归做是最方便的。
int a[N],c[N];void mergeSort(l,r){ int mid,i,j,tmp; if(r - 1 > l){ mid = (l+r) >> 1; // 分别最左右两天排序 mergeSort(l,mid); mergeSort(mid,r); // 合并排序后的数组 tmp = l; for(i=l,j=mid;i<mid && j<r;){ if(a[i] > a[j]) c[tmp++] = a[j++]; else c[tmp++] = a[i++]; } // 把剩余的接上 if(j < r) { for(;j<r;j++) c[tmp++] = a[j]; }else{ for(;i<mid;i++) c[tmp++] = a[i]; } // 将c数组覆盖到a里 for(i=l;i<r;i++){ a[i] = c[i]; } }}- 基本数据结构和算法回顾
- 基本算法和数据结构回顾(1)–排序
- 经典数据结构和算法回顾
- 经典数据结构和算法回顾
- 数据结构回顾版-java数据结构-有序数组和查找算法
- php 基本数据结构 和 算法
- 基本的数据结构和算法
- 图的基本数据结构和算法
- linux内核中的基本数据结构和算法
- 各种基本数据结构和算法总结清单
- linux内核中的基本数据结构和算法
- 数据结构和算法的基本介绍
- java数据结构和算法---基本查找排序
- 基本数据结构和算法的前端实现
- 下一篇:基本算法和java基本数据结构总结
- 数据结构回顾和总结(二叉搜索树(BST)的基本操作)
- 浅谈算法和数据结构(2):基本排序算法
- 浅谈算法和数据结构: 二 基本排序算法
- 【实例】使用jquery自带的slideToggle由上到下缓缓加载图片
- JDK,JRE,JVM
- 数组的顺序表示和实现
- dm8148 HDVPSS 知识简介
- cxf发布webservice
- 基本数据结构和算法回顾
- ubuntu之路——解决ubuntu+win8双系统循环进入启动界面导致无法启动win8的问题
- 流量水波浪效果,超级炫酷暖人
- iOS连载3
- 南邮 OJ 1135 Missile
- SSH 案例学习总结(二)
- HBase与MapReduce集成1-HBase2Hdfs
- java中Timer因修改系统时间致使任务被挂起的原因
- redis实现 spring-redis-data初学习