Codeforces Round #315 (Div. 1) C. New Language 字典序 2-sat 求解
来源:互联网 发布:尚硅谷linux视频教程 编辑:程序博客网 时间:2024/05/22 07:43
Living in Byteland was good enough to begin with, but the good king decided to please his subjects and to introduce a national language. He gathered the best of wise men, and sent an expedition to faraway countries, so that they would find out all about how a language should be designed.
After some time, the wise men returned from the trip even wiser. They locked up for six months in the dining room, after which they said to the king: "there are a lot of different languages, but almost all of them have letters that are divided into vowels and consonants; in a word, vowels and consonants must be combined correctly."
There are very many rules, all of them have exceptions, but our language will be deprived of such defects! We propose to introduce a set of formal rules of combining vowels and consonants, and include in the language all the words that satisfy them.
The rules of composing words are:
- The letters are divided into vowels and consonants in some certain way;
- All words have a length of exactly n;
- There are m rules of the form (pos1, t1, pos2, t2). Each rule is: if the position pos1 has a letter of type t1, then the position pos2 has a letter of type t2.
You are given some string s of length n, it is not necessarily a correct word of the new language. Among all the words of the language that lexicographically not smaller than the string s, find the minimal one in lexicographic order.
The first line contains a single line consisting of letters 'V' (Vowel) and 'C' (Consonant), determining which letters are vowels and which letters are consonants. The length of this string l is the size of the alphabet of the new language (1 ≤ l ≤ 26). The first l letters of the English alphabet are used as the letters of the alphabet of the new language. If the i-th character of the string equals to 'V', then the corresponding letter is a vowel, otherwise it is a consonant.
The second line contains two integers n, m (1 ≤ n ≤ 200, 0 ≤ m ≤ 4n(n - 1)) — the number of letters in a single word and the number of rules, correspondingly.
Next m lines describe m rules of the language in the following format: pos1, t1, pos2, t2 (1 ≤ pos1, pos2 ≤ n, pos1 ≠ pos2, 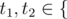 'V', 'C' }).
'V', 'C' }).
The last line contains string s of length n, consisting of the first l small letters of the English alphabet.
It is guaranteed that no two rules are the same.
Print a smallest word of a language that is lexicographically not smaller than s. If such words does not exist (for example, if the language has no words at all), print "-1" (without the quotes).
VC2 11 V 2 Caa
ab
VC2 11 C 2 Vbb
-1
VCC4 31 C 2 V2 C 3 V3 V 4 Vabac
acaa
In the first test word "aa" is not a word of the language, but word "ab" is.
In the second test out of all four possibilities only word "bb" is not a word of a language, but all other words are lexicographically less, so there is no answer.
In the third test, due to the last rule, "abac" doesn't belong to the language ("a" is a vowel, "c" is a consonant). The only word with prefix "ab" that meets the given rules is "abaa". But it is less than "abac", so the answer will be "acaa"
题意,首先义每个字母要么为元音要么辅音,给出一系列的规则,pos1, t1, pos2, t2表求第pos1处如果是t1,那么pos2处为t2(t1 t2为元音或辅音)。要求满足以上规则且字典序最小且字典序的大于等于给定字符串的目标串。
可以这样保证是字典序最小且且字典序的大于等于给定字符串,从大到小,枚举前i个字符相同,第i+1处字符大于给定的字符,这样就转化成了一个2-sat判定的问题。每个点分成两个点,表示为元音(i * 2表示),或者为辅音(i * 2 + 1),每个规则,可以对应成两条边,比如 p1 c p2 v,连成两条边,分别为,由p1为c可推出p2为v,由p2 为c 推出p1为v。这与普通2-sat问题又有区别,普通2-sat问题只用判定是否有解,而这题,由于是要求字典序最小的串,所以必须要先选序号小的串先搜才可以,用这个搜索策略就可以保证得到的解是最小的。2-sat问题可以用tarjan算法,求出强连通分量,再找出解。这里,直接由2-sat问题,图的高度对称性,可以用深搜找出解。用2-sat的方法判定了,每次复杂度为o(m)总的复杂度为o(n * m);
#define N 2100#define M 100005#define maxn 205#define MOD 1000000000000000007int n,m,p1,p2,n2,xi,st[N],sn,sp[30],len;char str[N],s1[10],s2[10],strc,strv,ans[N];vector<int> p[N];bool vis[N];void GetScSv(char & sc,char & sv,int tc){ sc = sv = '\0'; for(;tc < len;tc++){ if( sp[tc] && sc == '\0') sc = 'a' + tc; if(!sp[tc] && sv == '\0') sv = 'a' + tc; }}bool DFS(int x){ if(vis[x^1]) return false; if(vis[x]) return true; int tx = x/2; if(tx < xi){ if((x & 1) != sp[str[tx] - 'a']) return false; } else if(tx == xi){ int tc = str[tx] - 'a' + 1; char sc[2]; GetScSv(sc[1],sc[0],tc); if(sc[x & 1] != '\0'){ ans[tx] = sc[x & 1]; } else return false; } else { if((x & 1) && strc == '\0') return false; if(!(x & 1) && strv == '\0') return false; } vis[x] = true; st[sn++] = x; FI(p[x].size()){ if(!DFS(p[x][i])) return false; } return true;}bool twoDfs(int ti,int xi1,int xi2,char sv,char sc){ ans[ti] = sv; sn = 0; if(!DFS(xi1)){ FJ(sn) vis[st[j]] = false; sn = 0; ans[ti] = sc; if(!DFS(xi2)) return false; } return true;}bool ChoseDFS(char sv,char sc,int ti){ if(sv == '\0' && sc == '\0') return false; sn = 0; if(sv == '\0'){ ans[ti] = sc; if(!DFS(2 * ti + 1)) return false; } else if(sc == '\0'){ ans[ti] = sv; if(!DFS(2 * ti)) return false; } else { int xi1,xi2; if(sv < sc){ if(!twoDfs(ti,ti * 2, ti * 2 + 1,sv,sc)) return false; } else { if(!twoDfs(ti,ti * 2 + 1, ti * 2,sc,sv)) return false; } } return true;}bool sat_2(){ fill(vis,false); for(int i = 0;i<n2;i++){ if(!vis[i] && !vis[i^1]){ int ti = i / 2; if(ti < xi){ if(!DFS(2 * ti + sp[str[ti] - 'a'])) return false; } else if(ti == xi){ int tc = str[ti] - 'a' + 1; char sv = '\0',sc = '\0'; GetScSv(sc,sv,tc); if(!ChoseDFS(sv,sc,ti)) return false; } else { if(!ChoseDFS(strv,strc,ti)) return false; } } } return true;}void add_edge(int a,int b){ p[a].push_back(b); p[b^1].push_back(a^1);}int main(){ while(SS(str)!=EOF) { len = strlen(str); for(int i = 0;i < len;i++){ sp[i] = str[i] == 'C' ? 1:0; } GetScSv(strc,strv,0); S2(n,m); n2 = n + n; FI(n2) p[i].clear(); FI(m){ S(p1);SS(s1); S(p2);SS(s2); p1--;p2--; p1 *= 2;p2 *= 2; p1 = s1[0] == 'C'? p1^1:p1; p2 = s2[0] == 'C'? p2^1:p2; add_edge(p1,p2); } SS(str); bool flag = true; for(int i = n;i>=0 && flag;i--){ xi = i; if(sat_2()){ flag = false; for(int j = 0;j < i + i;j++){ ans[j/2] = str[j/2]; } for(int j = i + i + 2;j<n2;j++){ if(vis[j]){ ans[j/2] = (j&1)? strc:strv; } } ans[n] = '\0'; printf("%s\n",ans); } } if(flag) printf("-1\n"); } return 0;}- Codeforces Round #315 (Div. 1) C. New Language 字典序 2-sat 求解
- Codeforces Round #315 (Div. 1) C. New Language(2-sat+贪心)(好题)
- Codeforces Round #441 (Div. 1) C:National Property(2-SAT)
- Codeforces Round #150 (Div. 2) C. The Brand New Function
- Codeforces Round #402 (Div. 1) C. Peterson Polyglot(字典树合并/可持久化字典树)
- Codeforces Round #230 (Div. 2) C / (Div. 1) A
- Codeforces Round #230 (Div. 2) C (Div. 1)
- Codeforces Round #413 Div. 1 + Div. 2 C. Fountains
- codeforces Round #413 Div. 1 + Div. 2 C Fountains
- Codeforces Round #400 (Div. 1 + Div. 2, combined) C
- [2-SAT] Codeforces 668E #348 (VK Cup 2016 Round 2, Div. 1 Edition) E. Little Artem and 2-SAT
- 【codeforces】Codeforces Round #370 (Div. 2) C
- C. Watto and Mechanism 字典树 Codeforces Round #291 (Div. 2)
- Codeforces Round #291 (Div. 2)C.Watto and Mechanism——字典树+dfs
- Codeforces Round #291 (Div. 2) C. Watto and Mechanism Trie字典树+dfs
- Codeforces Round #367 (Div. 2) A(暴力) B(二分查找) C(DP) D(01字典树)
- Codeforces Round #371 (Div. 2)C. Sonya and Queries【字典树】
- Codeforces Round #400 (Div. 1 + Div. 2, combined)D. The Door Problem【2-sat Tarjan+思维建图】
- 实例详解机器学习如何解决问题
- windows 下一个进程能开多少个线程
- 【华为OJ平台练习题】统计一段字符串中含有空格、英文、数字的个数
- Easyui - datagrid 列编辑
- 程序猿必须掌握的git命令
- Codeforces Round #315 (Div. 1) C. New Language 字典序 2-sat 求解
- TI IIC extend GPIO, extend GPIO
- block传值
- 如何设置打印机?
- 利用3156硬核实现yuv直方图数据提取
- Qt中QString转int,float
- Java — 类与对象(Core Java I)
- hdoj Constructing Roads(最小生成树)
- Java正则表达式替换所有特殊字符


