Codeforces Round #315 (Div. 1) C. New Language(2-sat+贪心)(好题)
来源:互联网 发布:淘宝网服饰女毛衣 编辑:程序博客网 时间:2024/05/19 14:18
大致题意:
a~z每个字符分辅音和元音C和V,给出构词的法则,(pos1,kind1,pos2,kind2)如果位置1是kind1类型的字符,那么位置2必须是kind2类型的字符,求字典序不小于某个给定字符的合法构词(长度和给定的字符相等)若不存在输出-1
长度n<200,构词法则最多4*n*(n-1)条
思路:
可以贪心枚举每一位,假设前pos位答案和给定字符相等,那么pos+1位的字符必须比给定的字符pos+1位的字符大,然后pos+1位以后填充满足类型的最小字符
这样可以用2-sat dfs来输出解,2-sat dfs判解就有这个好处,可以按某种贪心(比如字典序)选解,然后构造出可行解
所以复杂度是 O(枚举*dfs) = O(n*m) = 1e6
//#pragma comment(linker, "/STACK:1024000000,1024000000")#include <iostream>#include <cstring>#include <cmath>#include <queue>#include <stack>#include <map>#include <set>#include <string>#include <vector>#include <cstdio>#include <ctime>#include <bitset>#include <algorithm>#define SZ(x) ((int)(x).size())#define ALL(v) (v).begin(), (v).end()#define foreach(i, v) for (__typeof((v).begin()) i = (v).begin(); i != (v).end(); ++ i)#define reveach(i, v) for (__typeof((v).rbegin()) i = (v).rbegin(); i != (v).rend(); ++ i)#define REP(i,n) for ( int i=1; i<=int(n); i++ )#define rep(i,n) for ( int i=0; i< int(n); i++ )using namespace std;typedef long long ll;#define X first#define Y secondtypedef pair<int,int> pii;template <class T>inline bool RD(T &ret) { char c; int sgn; if (c = getchar(), c == EOF) return 0; while (c != '-' && (c<'0' || c>'9')) c = getchar(); sgn = (c == '-') ? -1 : 1; ret = (c == '-') ? 0 : (c - '0'); while (c = getchar(), c >= '0'&&c <= '9') ret = ret * 10 + (c - '0'); ret *= sgn; return 1;}template <class T>inline void PT(T x) { if (x < 0) { putchar('-'); x = -x; } if (x > 9) PT(x / 10); putchar(x % 10 + '0');}const int N = 433;bool val[26];int n,m;vector<int>G[N];void add_edge(int u,char ch1,int v,char ch2){ u = (u-1)*2+(ch1 == 'C'); v = (v-1)*2+(ch2 == 'C'); G[u].push_back(v); G[v^1].push_back(u^1);}int all;char s[N];int lim;bool mark[N];int sta[N],top;char ch0,ch1,ch2,ch3;char tmp[N];bool dfs(int u) { if(mark[u^1]) return false; if(mark[u]) return true; if( u < 2*lim ){ int id = u/2; if ( val[s[id]-'a'] != (u&1) ) return false; } else if( u/2 == lim ){ if( (u&1) && ch1 == -1) return false; if( (u&1) == 0 && ch0 == -1) return false; }else if( u/2 > lim ){ if( (u&1) && ch3 == -1) return false; if( (u&1) == 0 && ch2 == -1) return false; } mark[u] = 1; sta[++top] = u; int sz=G[u].size(); for(int i = 0; i < sz;i++) { int v=G[u][i]; if( dfs(v) == false) return false; } return true;}bool judge() { memset(mark,0,sizeof(mark)); for(int i = 0;i < 2*n;i++) { if(!mark[i]&&!mark[i^1]) { top = 0; if( i < 2*lim ){ int id = i/2; if( val[s[id]-'a'] != (i&1) ) continue; if( dfs(i) == false ) return false; }else{ int u = i/2; if( u == lim){ if( val[s[lim]-'a'+1] != (i&1) ) continue; else{ if(dfs(i) == false) { for(int j = 1;j <= top; j++) mark[sta[j]] = 0; top = 0; if(dfs(i^1) == false) return false; } } }else{ if( val[0] != (i&1) ) continue; else{ if(dfs(i) == false) { for(int j = 1;j <= top; j++) mark[sta[j]] = 0; top = 0; if(dfs(i^1) == false) return false; } } } } } } return true;}int main(){ scanf("%s",tmp); cin>>n>>m; for(int i = 0; tmp[i]; i++){ if( tmp[i] == 'V') val[i] = 0; else val[i] = 1; } all = strlen(tmp); REP(i,m){ char ch1,ch2; int u,v; scanf("%d %c %d %c",&u,&ch1,&v,&ch2); add_edge(u,ch1,v,ch2); } scanf("%s",s); for(lim = n; lim >= 0; lim--){ if( s[lim] == 'a'+all-1 ) continue; ch0 = -1,ch1 = -1; for(int i = all-1; i > s[lim]-'a'; i--){ if( val[i] == 0) ch0 = 'a'+i; else ch1 = 'a'+i; } if( ch0 == -1 && ch1 == -1 ) continue; ch2 = -1,ch3 = -1; for(int i = all-1; i >= 0; i--){ if( val[i] == 0) ch2 = 'a'+i; else ch3 = 'a'+i; } if( judge() ){ rep(i,n) { if( i < lim ) putchar(s[i]); else{ int u = 2*i; if( i == lim){ if( mark[u] ) putchar(ch0); else putchar(ch1); }else{ if( mark[u] ) putchar(ch2); else putchar(ch3); } } } puts(""); return 0; } } puts("-1"); return 0;}Living in Byteland was good enough to begin with, but the good king decided to please his subjects and to introduce a national language. He gathered the best of wise men, and sent an expedition to faraway countries, so that they would find out all about how a language should be designed.
After some time, the wise men returned from the trip even wiser. They locked up for six months in the dining room, after which they said to the king: "there are a lot of different languages, but almost all of them have letters that are divided into vowels and consonants; in a word, vowels and consonants must be combined correctly."
There are very many rules, all of them have exceptions, but our language will be deprived of such defects! We propose to introduce a set of formal rules of combining vowels and consonants, and include in the language all the words that satisfy them.
The rules of composing words are:
- The letters are divided into vowels and consonants in some certain way;
- All words have a length of exactly n;
- There are m rules of the form (pos1, t1, pos2, t2). Each rule is: if the position pos1 has a letter of type t1, then the position pos2 has a letter of type t2.
You are given some string s of length n, it is not necessarily a correct word of the new language. Among all the words of the language that lexicographically not smaller than the string s, find the minimal one in lexicographic order.
The first line contains a single line consisting of letters 'V' (Vowel) and 'C' (Consonant), determining which letters are vowels and which letters are consonants. The length of this string l is the size of the alphabet of the new language (1 ≤ l ≤ 26). The first l letters of the English alphabet are used as the letters of the alphabet of the new language. If the i-th character of the string equals to 'V', then the corresponding letter is a vowel, otherwise it is a consonant.
The second line contains two integers n, m (1 ≤ n ≤ 200, 0 ≤ m ≤ 4n(n - 1)) — the number of letters in a single word and the number of rules, correspondingly.
Next m lines describe m rules of the language in the following format: pos1, t1, pos2, t2 (1 ≤ pos1, pos2 ≤ n, pos1 ≠ pos2, 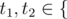 'V', 'C' }).
'V', 'C' }).
The last line contains string s of length n, consisting of the first l small letters of the English alphabet.
It is guaranteed that no two rules are the same.
Print a smallest word of a language that is lexicographically not smaller than s. If such words does not exist (for example, if the language has no words at all), print "-1" (without the quotes).
VC2 11 V 2 Caa
ab
VC2 11 C 2 Vbb
-1
VCC4 31 C 2 V2 C 3 V3 V 4 Vabac
acaa
In the first test word "aa" is not a word of the language, but word "ab" is.
In the second test out of all four possibilities only word "bb" is not a word of a language, but all other words are lexicographically less, so there is no answer.
In the third test, due to the last rule, "abac" doesn't belong to the language ("a" is a vowel, "c" is a consonant). The only word with prefix "ab" that meets the given rules is "abaa". But it is less than "abac", so the answer will be "acaa"
- Codeforces Round #315 (Div. 1) C. New Language(2-sat+贪心)(好题)
- Codeforces Round #315 (Div. 1) C. New Language 字典序 2-sat 求解
- Codeforces Round #256 (Div. 2) C. Painting Fence(分治+贪心)(好题)
- Codeforces Round #193 (Div. 2) C. Students' Revenge (两种优先级的贪心 好题)
- Codeforces Round #441 (Div. 1) C:National Property(2-SAT)
- Codeforces Round #276 (Div. 2)(C贪心,D)
- Codeforces Round #277 (Div. 2)---C. Palindrome Transformation (贪心)
- Codeforces Round #334 (Div. 2)C. Alternative Thinking(贪心)
- Codeforces Round #340 (Div. 2)(C)贪心,模拟
- Codeforces Round #294 (Div. 2)(C)贪心
- Codeforces Round #273 (Div. 2)(C)贪心,思维
- Codeforces Round #346 (Div. 2)(C)贪心
- Codeforces Round #346 (Div. 2) C (贪心)
- Codeforces Round #377 (Div. 2) C. Sanatorium(贪心,二分)
- Codeforces Round #377 (Div. 2)C. Sanatorium(贪心)
- Codeforces Round #402 (Div. 2) C. Dishonest Sellers(贪心)
- Codeforces Round #402 (Div. 2)C. Dishonest Sellers (贪心)
- Codeforces Round #433 (Div. 2) C. Planning(贪心)
- iOS APP转移开发者账号
- 学习笔记之SQl语句-插入对象的值
- Linux(CentOS) Wget安装配置用户Oracle JDK
- HDU 5412 CRB and Queries【整体二分+树状数组】
- Flume 收集Nginx日志到Hdfs Tail-to-hdfs sink
- Codeforces Round #315 (Div. 1) C. New Language(2-sat+贪心)(好题)
- android 如何设置图片颜色的透明度
- Cornerstone log 获取不到,超时,解决办法
- 机房收费系统优化之控件随窗体改变而相应比例改变
- php抓取远程数据排序
- android 优秀的几个框架
- cocos2d-js导弹跟踪算法(一边追着目标移动一边旋转角度)
- 算法、技术及其他
- Android中自定义checkbox样式


