random7->random10
来源:互联网 发布:历史书推荐 知乎 编辑:程序博客网 时间:2024/05/21 02:19
问题:rand7能生成1-7的整数随机数。要求利用rand7生成1-10的整数随机数。
总结探讨几种方法,并给出比较。我在最初写这篇文章的时候,出了一些错误,主要的原因是测试的方法不对,因此本文也强调一下对随机测试的问题。感慨一下知识的浩瀚和自己的渺小。感谢mingliang1212和hpsmouse的帮助。可以参看原帖。
总结探讨几种方法,并给出比较。我在最初写这篇文章的时候,出了一些错误,主要的原因是测试的方法不对,因此本文也强调一下对随机测试的问题。感慨一下知识的浩瀚和自己的渺小。感谢mingliang1212和hpsmouse的帮助。可以参看原帖。
1. 舍去法
一次rand7运算只能生成7个整数,没有办法均匀的映射到10个整数上。但是运行两次rand7可以生成49个数字,如果这49个数字是均匀分布的,舍去多余的9个,剩下的40个正好可以用模10运算映射到10个整数上。
代码1
int i;
do
{
i = 7 * (rand7() - 1) + rand7(); // it is now uniformly random between 1 and 49
} while(i > 40); // it is now uniformly random between 1 and 40
return i % 10 + 1; // result is now uniformly random between 1 and 10
do
{
i = 7 * (rand7() - 1) + rand7(); // it is now uniformly random between 1 and 49
} while(i > 40); // it is now uniformly random between 1 and 40
return i % 10 + 1; // result is now uniformly random between 1 and 10
这个算法做到了从40个数字均匀映射到1到10,这样说有些抽象,进一步形象的来说明,考虑如下的种子矩阵:
int seed7[7][7] = {
{1 , 2 , 3 , 4 , 5 , 6 , 7},
{8 , 9 , 10, 1 , 2 , 3 , 4},
{5 , 6 , 7 , 8 , 9 , 10, 1},
{2 , 3 , 4 , 5 , 6 , 7 , 8},
{9 , 10, 1 , 2 , 3 , 4 , 5},
{6 , 7 , 8 , 9 , 10, 0 , 0},
{0 , 0 , 0 , 0 , 0 , 0 , 0}
};
{1 , 2 , 3 , 4 , 5 , 6 , 7},
{8 , 9 , 10, 1 , 2 , 3 , 4},
{5 , 6 , 7 , 8 , 9 , 10, 1},
{2 , 3 , 4 , 5 , 6 , 7 , 8},
{9 , 10, 1 , 2 , 3 , 4 , 5},
{6 , 7 , 8 , 9 , 10, 0 , 0},
{0 , 0 , 0 , 0 , 0 , 0 , 0}
};
如果用x=0...6,y=1...7,则变换i=7x+y与矩阵中每个元素位置与(x,y)唯一对应,也就是x选择行,y选择列,
如果x和y都是均匀分布,那么这49个位置有相同的被选中的概率=1/49。下面这行代码实现了这个变换:
i = 7 * (rand7() - 1) + rand7();
其中7*(rand7()-1)相当于选择种子矩阵中的行,第二个rand7相当于选择列,而最后的模10+1运算,就恰好生成了矩阵中每个元素的值,但是(i>40)这个循环条件把最后的9个值变为了0。因此代码1等价于在种子矩阵中做选择。再来看,在这个矩阵中1-10数字一共出现了40次,每个数字出现4次,0出现了9次。我们在这个表里筛选,如果选中了0则重新选一次,如果非0则返回结果,那么1-10恰好可以得到平均机会。(更理论也更准确地说,这是一个条件概率。我们看一下在不选0的前提下选择到1的概率,令B=不选择零,A=选择到1,那么 P(A)=4/49,P(B)=40/49. 因为只要选择到1,B就必然成立,所以P(B|A)=1,令P(A|B)=在不选择零的前提下选择到1的概率,则根据Bayes公式 P(A|B)=P(B|A)*P(A)/P(B)=4/40=1/10. 其他的数字也都可以得出这个结论,因此,在不选择0的前提下,1-10的概率都=1/10。)
因此有代码2:
int result = 0;
while (!result)
result = seed7[rand7() - 1][rand() - 1];
return result;
while (!result)
result = seed7[rand7() - 1][rand() - 1];
return result;
显然,代码1与代码2是等价的。我个人更喜欢代码2,因为快。天下武功,唯坚不催,唯快不破。
舍去法效率的分析
现在看看rand7被调用的次数——这主要是由舍去率(或者反过来命中率决定的)。这两个代码每生成一个随机数调用rand7的次数不确定,那么平均调用了多少次呢?种子矩阵中选择一次,命中非0的概率有40/49,命中0的概率是9/49,这个过程是一个伯努利实验,进行n次选取平均(期望值)可以选出n*40/49个非0,因此生成100个非0就需要平均调用n*40/49>=100次,也就是n=100*49/40=122.5. 生成一个随机数需要进行两次选取,这意味着平均调用rand7的次数为2*1.225=2.45次。尽管生成一个随机数调用rand7的次数并不确定,但是平均调用不到2.5次,这个效率还是不错的。
代码2用7*7的内存替换了代码1的模10运算,牺牲了空间以换来更高的速度。
舍去法还有其他很多种构造方法。网友谈论的比较多的是构造rand2+rand5构造,以及rand2+rand14构造。方法如下:
rand2+rand5: 先构造rand2,然后构造rand5,利用如果rand2==1,则返回1-5,如果rand2==2,则返回rand5+5。
rand2+rand7: 先构造rand2,然后构造rand14,利用如果rand2==1,则返回1-7,如果rand2==2,则返回rand7+7。最后再舍去4个数字,最后得到rand10。
rand2的构造方法,目前我所知道最好的方法是1/7的舍去率:1-7中奇数多一个,舍去一个奇数,再让奇数对应1,偶数对应2,这样就得到了rand2。rand7->rand5的舍去率是2/7,rand14->rand10的舍去率是4/14,因此这两种方法的总舍去率都是1/7+2/7=3/7=0.429. 而代码1和代码2做两次rand7运算,每次的舍去率是9/49,因此总舍去率为18/49=0.367,略优于这两种算法。
2. 直接法——利用rand7做计算
由于舍去法每次调用rand7的次数未知,所以希望能够找到一种直接的方法。当然最直接的方法就是用线性同余这样的随机数生成法直接写一个,但是这就用不上rand7了,与题意不符合。有人希望用rand7的各种组合计算来完成,比如(rand7+rand7+rand7+...)%10+1或者(rand7*rand7*rand7*...)%10+1,有些计算确实能够达到很好的均匀度,但却是近似均匀。
从统计学的角度看, 一个rand7就相当于符合均匀分布的随机变量X1,当n个rand7做运算的时候,相当于X1...Xn是符合均匀分布的边缘随机变量,而F(X1, X2,...,Xn)是他们的联合分布,这个分布并非是均匀的,甚至很复杂,如果不用穷举法,几乎没有简便的方法计算每个数字出现的概率。现在要将多随机变量的F(X1,X2,...,Xn)映射到1到10的均匀分布,显然是有一定难度的, 而在本题来说,是不可能的,这是因为:
1) 对rand7的一元运算只能有7种结果,不可能产生10个随机数
2) 现在有二元运算(X)可以是加减乘除或者任何函数任何映射关系,rand7(X)rand7的可能运算方式是7*7种,,n次二元(X)运算后的可能是运算方式是7^(n+1)种,现在要用7^(n+1)种运算过程得到均匀的10种结果,这是不可能的,(因为7^(n+1)不能被10整除),所以只能是近似均匀。
下面来看怎样获得近似的均匀, ju136提醒我注意到,其中的一个比较好的方法是:
(rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7())%10+1
他获得的均匀度非常好,1出现的最多,5出现的最少,但是概率上仅仅相差0.00002,人类的感觉已经分辨不出来了。但是这个方法需要调用10次rand7,效率上差一些。
有人希望用这样的方法:调用两次rand7从而生成一个7进制的数,然后转换成0-49,刚好是50个数的均匀分布,再取模10。这个方法貌似可行,可是很遗憾的是,这样生成的7进制0-66对应到10进制是0-48,而不是49,少了一个数。
下面这个方法也比较好,(rand7+(rand7+7) +(rand7+14)+...+(rand7+42))%10,这个表达式生成7个随机数,分别均匀分布在1-7,8-14,...7个区间,相加之后再做模10运算,映射到0-9这10个数字。这7^7种运算,统计每个数字可以得到次数,其中5最高,0最低,但是他们几率的差仅为0.00041,人的感觉几乎分辨不出来了。这个方法需要调用7次rand7,效率比上面的代码高一些,因此有:
代码3
int rand10_7plus()
{
return (rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+147)%10+1;
}
{
return (rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+rand7()+147)%10+1;
}
这种直接方法,无论怎样在理论上都做不到均匀分布,所以,我们要想一些办法来提高。
3. 直接法——利用组合方法进一步提高
考虑数组
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
{6, 5, 4, 3, 2, 1, 10, 9, 8, 7 }
用rand7_plus在第一行中选择的时候6的机会最大,1的机会最小,但是在第二行选择的时候1的机会最大,6的机会最小,这两行有一定的互补性,所以如果轮流选择这两行,会得到更均匀的分布,根据上面的计数结果,可以得知,最小几率与最大几率的差仅为万分之一。推广一下,如果在数组
int seed10[10][10] = {
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10},
{10, 1, 2, 3, 4, 5, 6, 7, 8, 9},
{9, 10, 1, 2, 3, 4, 5, 6, 7, 8 },
{8, 9, 10, 1, 2, 3, 4, 5, 6, 7 },
{7, 8, 9, 10, 1, 2, 3, 4, 5, 6 },
{6, 7, 8, 9, 10, 1, 2, 3, 4, 5 },
{5, 6, 7, 8, 9, 10, 1, 2, 3, 4 },
{4, 5, 6, 7, 8, 9, 10, 1, 2, 3 },
{3, 4, 5, 6, 7, 8, 9, 10, 1, 2 },
{2, 3, 4, 5, 6, 7, 8, 9, 10, 1 },
};
{1, 2, 3, 4, 5, 6, 7, 8, 9, 10},
{10, 1, 2, 3, 4, 5, 6, 7, 8, 9},
{9, 10, 1, 2, 3, 4, 5, 6, 7, 8 },
{8, 9, 10, 1, 2, 3, 4, 5, 6, 7 },
{7, 8, 9, 10, 1, 2, 3, 4, 5, 6 },
{6, 7, 8, 9, 10, 1, 2, 3, 4, 5 },
{5, 6, 7, 8, 9, 10, 1, 2, 3, 4 },
{4, 5, 6, 7, 8, 9, 10, 1, 2, 3 },
{3, 4, 5, 6, 7, 8, 9, 10, 1, 2 },
{2, 3, 4, 5, 6, 7, 8, 9, 10, 1 },
};
之中,依次在每一行用rand10_7plus选择,由于每个数字出现的几率均等,并且在每行和每列上出现的几率均等,在多次调用之后就可以得到均匀分布。
代码4
unsigned int gi = 0;
int rand10_matrix()
{
//用rand10_7plus生成一个数,选择列
int n = rand10_7plus() - 1;
//轮流选择seed10的行
return seed10[gi++ % 10][n];
}
int rand10_matrix()
{
//用rand10_7plus生成一个数,选择列
int n = rand10_7plus() - 1;
//轮流选择seed10的行
return seed10[gi++ % 10][n];
}
如果利用模运算的循环性质,就不需要seed10这个矩阵,可以验证下面的代码与rand10_matrix是等效的:
代码5
unsigned int gi = 0;
int rand10_mod()
{
return ((rand10_7plus() - 1) + gi++) % 10 + 1;
}
int rand10_mod()
{
return ((rand10_7plus() - 1) + gi++) % 10 + 1;
}
这个算法每次调用7次rand7,做一次模运算,不需要额外的内存以及循环,从统计意义上说,已经是个比较好的伪随机数生成器。
4. 随机数测试
最初我在些这个文章的时候,在测试方面出了问题,所以在这里强调两点:
1). 随机度测试,需要每隔10次调用计数一次,以验证每个数字在各个位置上出现的次数是均等的。
代码要与如下类似:
for (k = 0; k < 100000; k++) {
n = 0;
for (j = 0; j < 10; j++)
n = rand10_7plus10();
result[n - 1]++;
}
n = 0;
for (j = 0; j < 10; j++)
n = rand10_7plus10();
result[n - 1]++;
}
注意result[n - 1]++是在j=0~10这个循环之外的。
2). 概率计算
在编写代码之前,一定要先证明1-10的均匀分布。例如前面10个rand连加的算法,在人的感觉之中已经分辨不出来概率的差别了,因此需要仔细统计一下10个数字,写一个简单的10层循环计数就可以了。很多朋友忽视了这点,并且,我们上面在第2小节证明了这是不可能做到均匀的。如果想不清楚或者很难证明你的方法,于是这个最简单的代码就非常有用:
for (i1 = 1; i1 <= 7; i1++)
for (i2 = 1; i2 <= 7; i2++)

for (i10 = 1; i10 <= 7; i10++)
result[(i1 + i2 + + i10) % 10]++;
for (i2 = 1; i2 <= 7; i2++)
for (i10 = 1; i10 <= 7; i10++)
result[(i1 + i2 +
+ i10) % 10]++; 5. 直接法——分布变换与连续随机变量的分布——更实际的应用
除了这道题的一些技巧,题目本身在实战中没有任何应用,比较实际的问题是,假设一个班的学生成绩符合正态分布,如何模拟生成考试成绩。
我们先看如果rand7是1-7的连续均匀分布,如何获得1-10的均匀分布。答案很简单,从几何的角度上看,我们可以把[a,b]线段上的点按照一对一映射到另一个线段[c,d]上去,只需要做一个线性变换y=(x-a)/(b-a)*(d-c)+c. 那么,若x=rand()~U(a,b),则y=~U(c,d),也就是如果rand()是a到b上的均匀分布,则y=(d-c)(x-a)/(b-a)+c是c到d上的均匀分布。对于本例rand10=(rand()-1)/6*9+1. 下面是证明,更一般的情况同理可证:
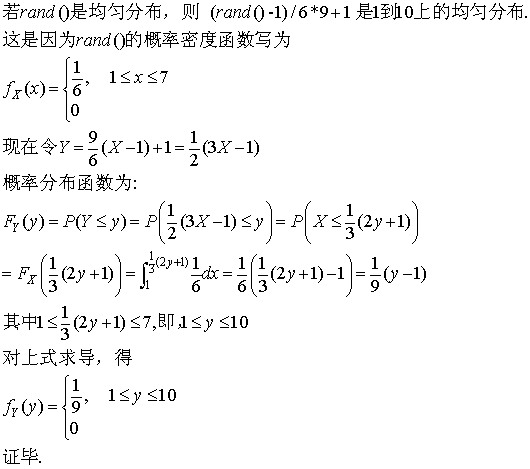
另外有一个重要的定理来表明变换之后的分布。这可以处理如Y=X^2, Y=e^X等多种变换。定理如下:

这个定理还可以更强一些,f(x)是分段还是也可以,甚至只是一个覆盖(包括)就可以了。从符合一种分布的随机数生成另外一种分布的随机数是统计模拟的课题,其中有非常有趣的变换方法,例如,如果X是(0,1)上的均匀分布,则Y=-a*log(X)是指数分布。
现在来回答如何按照正态分布模拟生成一个班的学生成绩。这个方法被称为Box-Muller算法,如果U1和U2服从 (0,1)区间的均匀分布,做变换R=sqrt(-2*logU1), alpha=2*pi*U2,则X=Rcos(alpha)和Y=Rsin(alpha)是一对独立的 标准正态分布n(0,1)。证明从略。按照这个方法,C语言的rand(),可以模拟生成近似的(0,1)均匀分布,只要rand()/MAX_RAND就可以了,做Box-Muller变换到n(0,1),就可以做出符合学生成绩分布了,概率统计课的基础内容就有。
6. 其他方法
舍去法也是非常重要的一类随机,用来生成各种分布的随机数,另外的方法:比如Metropolis算法,比较著名的还有Markov Chain Monte Carlo (MCMC)算法,这类方法可以看成是一个黑盒子,要求在算法内部通过几次运算很快收敛到一种概率分布,然后返回一个随机数。
7. 参考文献
[1] Casella & Berger 统计推断(Statistical Inference)
[2] Kunth第2卷Seminumerical Algorithms, Random Numbers.
posted on 2011-10-09 00:22 毕达哥拉斯半圆 阅读(4192) 评论(9) 编辑 收藏 引用
0 0
- random7->random10
- 【腾讯2011.10.15校园招聘笔试题】分析1——random7生成random10
- [智力题] raondom5 -> random7
- 重造轮子-random5到random7
- The New Villa (Uva 321 bfs)
- 可变参数使用
- hdu 5391 Zball in Tina Town
- C语言内存分布图
- Android Studio系列教程三--快捷键
- random7->random10
- 2015年面试准备(1)-----c/c++的区别
- docker管理的命令(1)
- 浅谈聚类&层次聚类
- 使用exe4j将jar文件加壳包装为exe文件(自带jre)
- 《基于BootStrap3的JSP项目实例教程》第4讲
- 数组和线性表
- java中int类型转化为String类型的几种方法
- docker管理的命令(2)



评论
# re: 由rand7生成rand10以及随机数生成方法的讨论[未登录] 2011-10-08 22:22 leo
任何有ran()+ran()的方法都是不行的,
就像扔2枚骰子,和为2和6的概率是不相同的 回复 更多评论
# re: 由rand7生成rand10以及随机数生成方法的讨论 2011-10-09 08:40 hyp
上面1-10每个数字出现了10次,0出现了9次,我们在这个表里筛选,如果选中了0则重新选一次,如果非0则返回结果。
LZ,这里有笔误吧,seed7[7][7]的数组怎么可能1-10每个数字出现十次? 回复 更多评论
# re: 由rand7生成rand10以及随机数生成方法的讨论 2011-10-09 10:38 coolypf
@leo
多加几次,可以得到正态分布。 回复 更多评论
# re: 由rand7生成rand10以及随机数生成方法的讨论 2011-10-09 10:48 毕达哥拉斯半圆
@hyp
是哒,应是一共出现了40次,每个4次。多谢啦! 回复 更多评论
# re: 由rand7生成rand10以及随机数生成方法的讨论 2011-10-09 12:12 毕达哥拉斯半圆
@coolypf
离散均匀分布相加得到的是多项式分布,多元随机变量。 回复 更多评论
# re: 由rand7生成rand10以及随机数生成方法的讨论 2011-10-10 09:11 zzz9413
要站在模块和设计的思想上,才能得出。我不是唯一正确的,但可以保证正确易于大家理解。
说明:所有随机数从1开始,不是从0开始
1:从rand_7到rand_10
小随机直接产生大随机难
2:那么从rand_14到rand_10容易
只需要判断rand_14是否在10以内,不在则继续rand_14直到在10内,显然这个数在10以内是均匀的
3,现在构造rand_14
rand_7套rand_2循环即可,rand_2==1,则返回rand_7。rand_2==2则返回rand_7+7,rand_2由第2步分析非常易得。
4,rand_14到rand_10,由第2步分析即得。
回复 更多评论
# re: 由rand7生成rand10以及随机数生成方法的讨论 2011-10-10 09:13 zzz9413
其他的构造rand_2和rand_5
然后套循环变成rand_10,都是换汤不换药,不具有普遍性
回复 更多评论
# re: 由rand7生成rand10以及随机数生成方法的讨论 2011-10-10 09:56 毕达哥拉斯半圆
@zzz9413
这个方法也很好,不过效率可能稍微差一点。rand2最好的实现方法(就我目前所知)是1/7的舍去率,rand14->rand10的舍去率是4/14,这两步相加就是 6/14的舍去率,将近一半。所以调用的rand7的次数也会比较多。 不过这提醒我把这个分析加到正文里去,多谢! 回复 更多评论
# re: 由rand7生成rand10以及随机数生成方法的讨论 2011-10-10 10:18 毕达哥拉斯半圆
@zzz9413
我在正文里评估了rand2+rand5和rand2+rand14,请您指点,多谢! 回复 更多评论