Codeforces Round #315 (Div. 1)
来源:互联网 发布:塔里木农垦大学知乎 编辑:程序博客网 时间:2024/05/18 01:52
Rikhail Mubinchik believes that the current definition of prime numbers is obsolete as they are too complex and unpredictable. A palindromic number is another matter. It is aesthetically pleasing, and it has a number of remarkable properties. Help Rikhail to convince the scientific community in this!
Let us remind you that a number is called prime if it is integer larger than one, and is not divisible by any positive integer other than itself and one.
Rikhail calls a number a palindromic if it is integer, positive, and its decimal representation without leading zeros is a palindrome, i.e. reads the same from left to right and right to left.
One problem with prime numbers is that there are too many of them. Let's introduce the following notation:π(n) — the number of primes no larger thann,rub(n) — the number of palindromic numbers no larger thann. Rikhail wants to prove that there are a lot more primes than palindromic ones.
He asked you to solve the following problem: for a given value of the coefficientA find the maximumn, such thatπ(n) ≤ A·rub(n).
The input consists of two positive integers p,q, the numerator and denominator of the fraction that is the value ofA (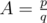 ,
, 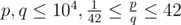 ).
).
If such maximum number exists, then print it. Otherwise, print "Palindromic tree is better than splay tree" (without the quotes).
1 1
40
1 42
1
6 4
172题意:定义π(N)=∑(i为素数?1:0),i<=N, rub(N)=∑(i为回文数?1:0),i<=N。A=p/q,求最大的N,使得π(n) ≤ A·rub(n)。分析:预处理两者的值会发现:随着N的增大,两者之比是有单调性的,根据A的范围估计一下N的上界,也不大,So.../****************************** contest: Codeforces Round #315 (Div. 1), problem: (A) Primes or Palindromes? 2015-08-11 03:41:28 *****************************/#include <bits/stdc++.h>using namespace std;#define LL long longconst int N = 2000001;int vis[N];LL a[N], b[N];bool judge(int x){ char s[13]; sprintf(s,"%d",x); int len = strlen(s); for(int i=0; i<len>>1; i++) if(s[i] != s[len-1-i]) return false; return true;}void Init(){ for(int i=2; i*i<N; i++) if(!vis[i]) { for(int j=i*i; j<N; j+=i) vis[j] = 1; } a[0] = a[1] = 0; for(int i=2; i<N; i++) a[i] = !vis[i] ? a[i-1]+1 : a[i-1]; b[0] = 0; for(int i=1; i<N; i++) if(judge(i)) b[i] = b[i-1]+1; else b[i] = b[i-1];}int main(){ int i,j,k,m,n; LL p,q; Init(); while(scanf("%I64d %I64d",&p,&q) == 2) { int ans = -1; for(i=2000000; i>=1 ;i--) if(q*a[i] <= p*b[i]) { ans = i; break; } if(ans == -1) puts("Palindromic tree is better than splay tree"); else printf("%d\n",ans); } return 0;}B. Symmetric and Transitivetime limit per test1.5 secondsmemory limit per test256 megabytesinputstandard inputoutputstandard outputLittle Johnny has recently learned about set theory. Now he is studying binary relations. You've probably heard the term "equivalence relation". These relations are very important in many areas of mathematics. For example, the equality of the two numbers is an equivalence relation.
A set ρ of pairs (a, b) of elements of some set A is called a binary relation on set A. For two elements a and b of the set A we say that they are in relation ρ, if pair
, in this case we use a notation
.
Binary relation is equivalence relation, if:
- It is reflexive (for any a it is true that
);
- It is symmetric (for any a, b it is true that if
);
- It is transitive (if
, than
).
Little Johnny is not completely a fool and he noticed that the first condition is not necessary! Here is his "proof":
Take any two elements, a and b. If
It's very simple, isn't it? However, you noticed that Johnny's "proof" is wrong, and decided to show him a lot of examples that prove him wrong.
Here's your task: count the number of binary relations over a set of size n such that they are symmetric, transitive, but not an equivalence relations (i.e. they are not reflexive).
Since their number may be very large (not 0, according to Little Johnny), print the remainder of integer division of this number by 109 + 7.
InputA single line contains a single integer n (1 ≤ n ≤ 4000).
OutputIn a single line print the answer to the problem modulo 109 + 7.
Sample test(s)Input1Output1Input2Output3Input3Output10NoteIf n = 1 there is only one such relation — an empty one, i.e.
. In other words, for a single element x of set A the following is hold:
.
If n = 2 there are three such relations. Let's assume that set A consists of two elements, x and y. Then the valid relations are
题意:
含有N种元素的二元组集合,有多少个子集,满足对称性、传递性且不满足自反性?
分析:
ans=Bell(n+1)-Bell(n)。
B(n):基数为n的集合划分数目。例如B(3)=5, 因为3个元素的集合{1,b,c}有5种不同的划分方法:
- {{a}, {b}, {c}}
- {{a}, {b, c}}
- {{b}, {a, c}}
- {{c}, {a, b}}
- {{a, b, c}}
因为N的范围较小,故可以利用Bell三角形求B(n);
1
1 2
2 3 5
5 7 10 15
15 20 27 37 52
... ...
/**************************** contest: Codeforces Round #315 (Div. 1), problem: (B) Symmetric and Transitive 2015-08-16 06:01:06 *****************************/#include <bits/stdc++.h>using namespace std;const int mod = 1000000007;const int N = 4002;int dp[N][N];int main(){ int i,j,k,m,n; while(scanf("%d",&n) == 1) { dp[1][1] = 1; for(i=2; i<=n+1; i++) { dp[i][1] = dp[i-1][i-1]; for(j=2; j<=i; j++) dp[i][j] = (dp[i-1][j-1] + dp[i][j-1]) % mod; } printf("%d\n",(dp[n+1][n+1]-dp[n][n]+mod)%mod); } return 0;}Living in Byteland was good enough to begin with, but the good king decided to please his subjects and to introduce a national language. He gathered the best of wise men, and sent an expedition to faraway countries, so that they would find out all about how a language should be designed.
After some time, the wise men returned from the trip even wiser. They locked up for six months in the dining room, after which they said to the king: "there are a lot of different languages, but almost all of them have letters that are divided into vowels and consonants; in a word, vowels and consonants must be combined correctly."
There are very many rules, all of them have exceptions, but our language will be deprived of such defects! We propose to introduce a set of formal rules of combining vowels and consonants, and include in the language all the words that satisfy them.
The rules of composing words are:
- The letters are divided into vowels and consonants in some certain way;
- All words have a length of exactly n;
- There are m rules of the form (pos1, t1, pos2, t2). Each rule is: if the position pos1 has a letter of type t1, then the position pos2 has a letter of type t2.
You are given some string s of length n, it is not necessarily a correct word of the new language. Among all the words of the language that lexicographically not smaller than the string s, find the minimal one in lexicographic order.
The first line contains a single line consisting of letters 'V' (Vowel) and 'C' (Consonant), determining which letters are vowels and which letters are consonants. The length of this string l is the size of the alphabet of the new language (1 ≤ l ≤ 26). The first l letters of the English alphabet are used as the letters of the alphabet of the new language. If the i-th character of the string equals to 'V', then the corresponding letter is a vowel, otherwise it is a consonant.
The second line contains two integers n, m (1 ≤ n ≤ 200, 0 ≤ m ≤ 4n(n - 1)) — the number of letters in a single word and the number of rules, correspondingly.
Next m lines describe m rules of the language in the following format: pos1, t1, pos2, t2 (1 ≤ pos1, pos2 ≤ n, pos1 ≠ pos2, 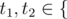 'V', 'C' }).
'V', 'C' }).
The last line contains string s of length n, consisting of the first l small letters of the English alphabet.
It is guaranteed that no two rules are the same.
Print a smallest word of a language that is lexicographically not smaller than s. If such words does not exist (for example, if the language has no words at all), print "-1" (without the quotes).
VC2 11 V 2 Caa
ab
VC2 11 C 2 Vbb
-1
VCC4 31 C 2 V2 C 3 V3 V 4 Vabac
acaa
In the first test word "aa" is not a word of the language, but word "ab" is.
In the second test out of all four possibilities only word "bb" is not a word of a language, but all other words are
lexicographically less, so there is no answer.
In the third test, due to the last rule, "abac" doesn't belong to the language ("a" is a vowel, "c" is a consonant).
The only word with prefix "ab" that meets the given rules is "abaa". But it is less than "abac", so the answer will be "acaa"
题意:
输入:
长度不大于26的'V''C'串,依次对应小写字母a、b、c......字符C对应于'V'则说明此字符是'V'类型,反之亦然。
待输入和求解的字符串长n,和规则数目m。
m个规则,形如pos1, t1, pos2, t2 (1 ≤ pos1, pos2 ≤ n, pos1 ≠ pos2,t1,t2∈{'V', 'C' }).表示:如果pos1位置是t1类型的字符,
pos2位置必须是t2类型的字符。
一个长度为n的字符串。
输出:
一个长度为n的满足m条规则的且字典序不小于串s的字符串。若不存在输出-1,否则输出满足要求的字典序最小的。
分析:
首先可以想到利用2-SAT判定规则是否自相矛盾,若矛盾直接输出-1;
若有可能存在解,因为字典序要不小于s,我们可以从后往前枚举答案中第一个大于s[i]的位置i(i=n+1表示和原串相同),直到有解。
这样就好办了,那么对于小于i的位置j,ans[j]=s[j]。i位置最多有两种取法,分别为类型为'V'和'C'第一个大于s[i]的字符。
对于大于i的位置,全部贪心为字符'a',因为这样就满足了字典序不小于s且字典序最小。
如果没有m条规则,那么以上得到的串就是满足题意且字典序最小的了。
然后问题来了,不是还要满足m条规则吗?我们可以以贪心的方式修改得到的串,使之满足所有规则。重点是下面的:
因为要字典序最小,我们从左往右贪心使得规则对他的影响尽可能的小,也就是说,其他位的取法使得他的增值最小,任何位置是不会变小的,因为每次
枚举得到串的每个位置都已经最小了,那么对于位置i来说,我们不希望大于i的位置的取法对他产生影响,i位置只能受小于i的位置的影响,因为我们要
尽可能的使左边的位置不要增大。
可是,可能存在某规则如:4 'V' 2 'C'如果此时位置4取'V'类型,2位置不是'C'类型,那么就要影响2位置了怎么办?
我们想一种办法每确定一个位置i,就确定它右边所有对他产生影响的位置。
对于每个规则 例如 X 'V' Y 'C' 我们还要加入一条隐含的规则: Y 'V' X 'C'
其实,在2-SAT判定时,我们就加进去了。
那么,每个位置都不会对它左边的位置产生影响了。
不成立的情况就是:某个位置即被改为’V'类型也被改为'C'类型,或者某个位置要求的类型在首行给出的串中不存在。
/************************************** contest: Codeforces Round #315 (Div. 1), problem: (C) New Language, 2015-08-16 07:38:45 *************************************/#include <bits/stdc++.h>using namespace std;const int mod = 1000000007;const int N = 210;vector<int>G[N<<1];/******2-SAT判定*************************/int tim,num;int low[N<<1], dfn[N<<1], bel[N<<1];bool inst[N<<1], vis[N<<1];stack<int>st;void tarjan(int u){ vis[u] = 1; low[u] = dfn[u] = ++tim; st.push(u), inst[u] = 1; for(int i=0; i<G[u].size(); i++) { int v = G[u][i]; if(!vis[v]) { tarjan(v); low[u] = min(low[u], low[v]); } else if(inst[v]) low[u] = min(low[u], dfn[v]); } if(low[u] == dfn[u]){ num++; int j; do { j = st.top(), st.pop(); bel[j] = num; inst[j] = 0; } while(j!=u); }}bool judge(int n){ tim = num = 0; memset(vis,0,sizeof(vis)); memset(inst, 0, sizeof(inst)); for(int i=2; i<=(n<<1|1); i++) if(!vis[i]) tarjan(i); for(int i=2; i<=(n<<1); i+=2) if(bel[i] == bel[i+1]) return false; return true;}/*****--------------------------------------------------------*/char str[27];char s[N], ans[N], tmp[N];int w['z'+2];char get(int pos, char c){ for(int i=pos+1; str[i]!='\0'; i++) if(str[i] == c) return 'a'+i; return -1;}queue<int>q;int main(){ int i,j,k,m,n; while(scanf("%s",str) == 1) { int len = strlen(str); for(i=0; i<len; i++) w[i+'a'] = str[i]=='V' ? 0 : 1; scanf("%d %d",&n,&m); for(i=2; i<(N<<1); i++) G[i].clear(); char s1[2],s2[2]; int a, b; while(m--) { scanf("%d %s %d %s",&a, s1, &b, s2); a = a<<1|(s1[0]!='V'), b = b<<1|(s2[0]!='V'); G[a].push_back(b); G[b^1].push_back(a^1); } scanf("%s",s+1); if(!judge(n)) { puts("-1"); continue; } bool OK = false;; tmp[1] = -1; for(int pos=n+1; pos>=1; pos--)///枚举第一个比s串大的位置 { for(int a=pos<<1; a<=(pos<<1|1); a++)///枚举pos位是'V' or 'C' { bool ok = true; strcpy(ans+1, s+1); memset(vis,0,sizeof(vis)); if(pos <= n) { char tp = get(s[pos]-'a', (a&1)? 'C' : 'V'); if(tp == -1) continue; ans[pos] = tp; } for(i=pos+1; i<=n; i++) ans[i] = 'a';///贪心 for(i=1; i<=n&&ok; i++) ///利用规则进行变换 { int a = i<<1|w[ans[i]]; if(vis[a]) continue; vis[a] = 1; while(!q.empty()) q.pop(); q.push(a); while(!q.empty()) { a = q.front(); q.pop(); if(vis[a^1]) {ok = false; break;} ///pos以前的位置不能变 if(a/2 <= pos && w[ans[a/2]] != (a&1)) {ok = false; break;} if(a/2 > pos) { char tp = get(-1,a&1 ? 'C' : 'V'); if(tp == -1) {ok = false; break;} ans[a/2] = tp; } for(j=0; j<G[a].size(); j++) { if(!vis[G[a][j]]) vis[G[a][j]] = 1, q.push(G[a][j]); } } } if(!ok) continue; OK = true; ans[n+1] = 0; if(tmp[1] == -1) strcpy(tmp+1,ans+1); else if(strcmp(ans+1, tmp+1) < 0) strcpy(tmp+1, ans+1); } if(OK) break; } OK ? puts(tmp+1):puts("-1"); } return 0;}One Khanate had a lot of roads and very little wood. Riding along the roads was inconvenient, because the roads did not have road signs indicating the direction to important cities.
The Han decided that it's time to fix the issue, and ordered to put signs on every road. The Minister of Transport has to do that, but he has only k signs. Help the minister to solve his problem, otherwise the poor guy can lose not only his position, but also his head.
More formally, every road in the Khanate is a line on the Oxy plane, given by an equation of the form Ax + By + C = 0 (A and B are not equal to 0 at the same time). You are required to determine whether you can put signs in at most k points so that each road had at least one sign installed.
The input starts with two positive integers n, k (1 ≤ n ≤ 105, 1 ≤ k ≤ 5)
Next n lines contain three integers each, Ai, Bi, Ci, the coefficients of the equation that determines the road (|Ai|, |Bi|, |Ci| ≤ 105, Ai2 + Bi2 ≠ 0).
It is guaranteed that no two roads coincide.
If there is no solution, print "NO" in the single line (without the quotes).
Otherwise, print in the first line "YES" (without the quotes).
In the second line print a single number m (m ≤ k) — the number of used signs. In the next m lines print the descriptions of their locations.
Description of a location of one sign is two integers v, u. If u and v are two distinct integers between 1 and n, we assume that sign is at the point of intersection of roads number v and u. If u = - 1, and v is an integer between 1 and n, then the sign is on the road number v in the point not lying on any other road. In any other case the description of a sign will be assumed invalid and your answer will be considered incorrect. In case if v = u, or if v and u are the numbers of two non-intersecting roads, your answer will also be considered incorrect.
The roads are numbered starting from 1 in the order in which they follow in the input.
3 11 0 00 -1 07 -93 0YES11 23 11 0 00 1 01 1 3NO2 33 4 55 6 7YES21 -12 -1Note that you do not have to minimize m, but it shouldn't be more than k.
In the first test all three roads intersect at point (0,0).
In the second test all three roads form a triangle and there is no way to place one sign so that it would stand on all three roads at once.
给N条直线,问能否用K个点覆盖所有的线,点覆盖了某条线表示该点在这条线上。
给出线的方式是告诉三个值A、B、C,表示这条线可以用Ax+By+C=0表示。
如果能覆盖,输出点的个数和这些点,点以形成该交点的两条线的的标号方式给出,如果不是交点,输出一个所在线的标号和-1。
分析:
这个题的特点是没有要求覆盖所有直线的点数最少,而且K≤5。而且根据测试,数据中没有两直线平行的情况。
假设此时状态为:L条直线,最多还可以用K个点
IF L不大于K,显然答案L对"i -1"就满足了题意,i是这些边的编号。
ELSE IF 找出一个交点,该交点覆盖了X条直线,只要X*K≥L,THEN 选取该点,删掉覆盖到的边,L-=X,K--;
(如果所有直线不存在平行,那么删掉该点不会影响可解性。)
ELSE 无法覆盖。
由于边的数量很大,交点的数量可能巨大,在找交点时,我们只能多次的随机的找出一些点来代表所有情况。
/********************** contest: Codeforces Round #315 (Div. 1), problem: (D) Sign Posts 2015-08-16 12:31:17 **********************/#include <bits/stdc++.h>using namespace std;typedef long long LL;const double eps = 1e-8;int dcmp(double x){ if(fabs(x) < eps) return 0; return x > 0 ? 1 : -1;}struct point{ double x, y; point(double x=0, double y=0):x(x),y(y){}};struct Line{ double a,b,c; int id; Line(double a=0, double b=0, double c=0, int id=0):a(a),b(b),c(c),id(id){}};vector<Line>L;pair<int, int> ans[6];bool inter(Line L1, Line L2, point &p){ double a1 = L1.a, b1 = L1.b, c1 = L1.c, a2 = L2.a, b2 = L2.b, c2 = L2.c; if(dcmp(a1*b2-a2*b1) == 0) return false; //这种情况不存在 p = point( (b1*c2-c1*b2)/(a1*b2-b1*a2), (a1*c2-c1*a2)/(b1*a2-a1*b2) ); return true;}int main(){ int i,j,k,m,n; while(scanf("%d %d",&n,&k) == 2) { double a, b, c; L.clear(); for(i=1; i<=n; i++) scanf("%lf %lf %lf",&a, &b, &c), L.push_back(Line(a,b,c,i)); int p = 0; bool ok = true; while(!L.empty()) { if(k >= L.size()) { ans[++p] = make_pair(L[L.size()-1].id, -1); L.pop_back(); continue; } point tp; for(i=1; i<=500; i++) { int a = rand()%L.size(), b = rand()%L.size(); if(!inter(L[a], L[b], tp)) continue; int ret = 0; for(j=0; j<L.size(); j++) { Line &u = L[j]; if(dcmp(tp.x*u.a+tp.y*u.b+u.c) == 0) ret++; } if(ret * k >= L.size()) {ans[++p] = make_pair(L[a].id, L[b].id); break;} } if(i > 500) {ok = false; break;} for(j=L.size()-1; j>=0; j--) { Line u = L[j]; if(dcmp(tp.x*u.a+tp.y*u.b+u.c) == 0) { swap(L[j],L[L.size()-1]); L.pop_back(); } } k--; } if(!ok) puts("NO"); else { puts("YES"); printf("%d\n",p); for(i=1; i<=p; i++) printf("%d %d\n",ans[i].first, ans[i].second); } } return 0;}Note that the memory limit in this problem is less than usual.
Let's consider an array consisting of positive integers, some positions of which contain gaps.
We have a collection of numbers that can be used to fill the gaps. Each number from the given collection can be used at most once.
Your task is to determine such way of filling gaps that the longest increasing subsequence in the formed array has a maximum size.
The first line contains a single integer n — the length of the array (1 ≤ n ≤ 105).
The second line contains n space-separated integers — the elements of the sequence. A gap is marked as "-1". The elements that are not gaps are positive integers not exceeding 109. It is guaranteed that the sequence contains 0 ≤ k ≤ 1000 gaps.
The third line contains a single positive integer m — the number of elements to fill the gaps (k ≤ m ≤ 105).
The fourth line contains m positive integers — the numbers to fill gaps. Each number is a positive integer not exceeding 109. Some numbers may be equal.
Print n space-separated numbers in a single line — the resulting sequence. If there are multiple possible answers, print any of them.
31 2 3110
1 2 3
31 -1 331 2 3
1 2 3
2-1 222 4
2 2
3-1 -1 -151 1 1 1 2
1 1 2
4-1 -1 -1 241 1 2 2
1 2 1 2
In the first sample there are no gaps, so the correct answer is the initial sequence.
In the second sample there is only one way to get an increasing subsequence of length 3.
In the third sample answer "4 2" would also be correct. Note that only strictly increasing subsequences are considered.
In the fifth sample the answer "1 1 1 2" is not considered correct, as number 1 can be used in replacing only two times.
- Codeforces Round #315 (Div. 1)
- Codeforces Round #315 (Div. 1) B
- Codeforces Round #315 (Div. 2)
- Codeforces Round #315 (Div. 2)
- Codeforces Round #315 (Div. 2)
- Codeforces Round #315 (Div. 2)
- Codeforces Round #315 (Div. 2)
- Codeforces Round #315 (Div. 2)
- Codeforces Round #315 (Div. 2)
- Codeforces Round #110 (Div. 1)
- Codeforces Round #138 (Div. 1)
- Codeforces Round #140 (Div. 1)
- Codeforces Round #153 (Div. 1)
- Codeforces Round #157 (Div. 1)
- Codeforces Round #160 (Div. 1)
- Codeforces Round #162 (Div. 1)
- Codeforces Round #165 (Div. 1)
- Codeforces Round #165 (Div. 1)
- 添加VLC录像API
- HDU 4883 TIANKENG’s restaurant(排序或优先队列模拟)——BestCoder Round #2
- ASP.NET第一章总结
- UIWebView与JS的深度交互
- java的多线程同步及锁的机制 http://f.dataguru.cn/thread-483280-1-1.html (出处: 炼数成金)
- Codeforces Round #315 (Div. 1)
- TextView加载Html内容(自定义TextView)
- 微信公众号开发系列-网页授权获取用户基本信息
- Linux 下 安装 PHP 的 PDO_MYSQL 扩展
- LOJ 1201 - A Perfect Murder(二分匹配 最大独立集)
- IOS项目上架时问题的解决方案(3)
- android-ndk 数据传递
- 解决点击状态栏时ScrollView自动滚动到初始位置失效办法
- 腾讯云使用教程 基本工具 开发工具软件 从入门到精通 图文教程


