Hadoop系列之五:MapReduce进阶(2)
来源:互联网 发布:异次元通讯需要网络吗 编辑:程序博客网 时间:2024/06/04 06:18
版权声明:原创作品,如需转载,请与作者联系。否则将追究法律责任。
1、MapReduce作业、集群及其逻辑架构
前文已经描述,MapReduce是一个编程框架,它为程序员提供了一种快速开发海量数据处理程序的编程环境,并能够让基于这种机制开发出的处理程序以稳定、容错的方式并行运行于由大量商用硬件组成的集群上。同时,MapReduce又是一个运行框架,它需要为基于MapReduce机制开发出的程序提供一个运行环境,并透明管理运行中的各个细节。每一个需要由MapReduce运行框架运行的MapReduce程序也称为一个MapReduce作业(mapreduce job),它需要由客户端提交,由集群中的某专门节点负责接收此作业,并根据集群配置及待处理的作业属性等为其提供合适的运行环境。其运行过程分为两个阶段:map阶段和reduce阶段,每个阶段都根据作业本身的属性、集群中的资源可用性及用户的配置等启动一定数量的任务(也即进程)负责具体的数据处理操作。
在MapReduce集群中,负责接收客户端提交的作业的主机称作master节点,此节点上具体负责接收作业的进程称作JobTracker。负责运行map任务或reduce任务的节点称作slave节点,其运行的作业处理进程为TaskTracker。默认情况下,一个slave节点可同时运行两个map任务和两个reduce任务。
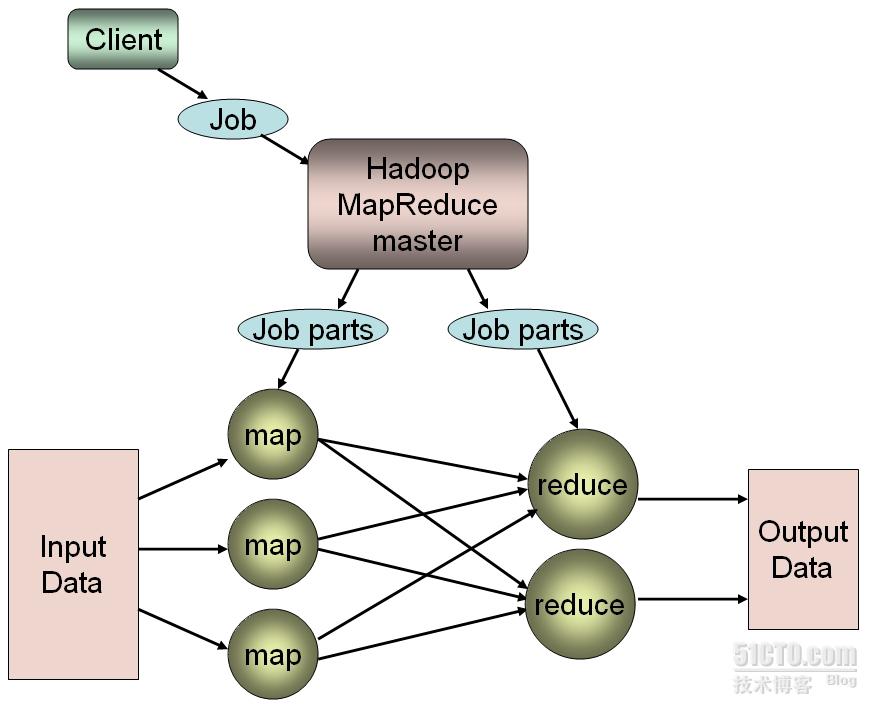
MapReduce客户端提交一个作业

2、Hadoop运行框架
MapReduce程序也称作为MapReduce作业,一般由mapper代码、reducer代码以及其配置参数(如从哪儿读入数据,以及输出数据的保存位置)组成。准备好的作业可通过JobTracker(作业提交节点)进行提交,然后由运行框架负责完成后续的其它任务。这些后续任务主要包括如下几个方面。
(1) 调度
每个MapReduce作业都会划分为多个称作任务(task)的较小单元,而较大的作业划分的任务数量也可能会超出整个集群可运行的任务数,此时就需要调度器程序维护一个任务队列并能够追踪正在运行态任务的相关进程,以便让队列中处于等待状态的任务派送至某转为可用状态的节点运行。此外,调度器还要负责分属于不同作业的任务协调工作。
对于一个运行中的作业来说,只有所用的map任务都完成以后才能将中间数据分组、排序后发往reduce作业,因此,map阶段的完成时间取决于其最慢的一个作业的完成时间。类似的,reduce阶段的最后一个任务执行结束,其最终结果才为可用。因此,MapReduce作业完成速度则由两个阶段各自任务中的掉队者决定,最坏的情况下,这可能会导致作业长时间得不到完成。出于优化执行的角度,Hadoop和Google MapReduce实现了推测执行(Speculative execution)机制,即同一个任务会在不同的主机上启动多个执行副本,运行框架从其最快执行的任务中取得返回结果。不过,推测执行并不能消除其它的滞后场景,比如中间键值对数据的分发速度等。
(2) 数据和代码的协同工作(data/code co-location)
术语“数据分布”可能会带来误导,因为MapReduce尽力保证的机制是将要执行的代码送至数据所在的节点执行,因为代码的数据量通常要远小于要处理的数据本身。当然,MapReduce并不能消除数据传送,比如在某任务要处理的数据所在的节点已经启动很多任务时,此任务将不得不在其它可用节点运行。此时,考虑到同一个机架内的服务器有着较充裕的网络带宽,一个较优选择是从数据节点同一个机架内挑选一个节点来执行此任务。
(3) 同步(Synchronization)
异步环境下的一组并发进程因直接制约而互相发送消息而进行互相合作、互相等待,使得各进程按一定的速度执行的过程称为进程间同步,其可分为进程同步(或者线程同步)和数据同步。就编程方法来说,保持进程间同步的主要方法有内存屏障(Memory barrier),互斥锁(Mutex),信号量(Semaphore)和锁(Lock),管程(Monitor),消息(Message),管道(Pipe)等。MapReduce是通过在map阶段的进程与reduce阶段的进程之间实施隔离来完成进程同步的,即map阶段的所有任务都完成后对其产生的中间键值对根据键完成分组、排序后通过网络发往各reducer方可开始reduce阶段的任务,因此这个过程也称为“shuffle and sort”。
(4) 错误和故障处理(Error and fault handling)
MapReduce运行框架本身就是设计用来容易发生故障的商用服务器上了,因此,其必须有着良好的容错能力。在任何类别的硬件故障发生时,MapReduce运行框架均可自行将运行在相关节点的任务在一个新挑选出的节点上重新启动。同样,在任何程序发生故障时,运行框架也要能够捕获异常、记录异常并自动完成从异常中恢复。另外,在一个较大规模的集群中,其它任何超出程序员理解能力的故障发生时,MapReduce运行框架也要能够安全挺过。
3、partitioner和combiner
除了前述的内容中的组成部分,MapReduce还有着另外两个组件:partiontioner和combiner。
Partitioner负责分割中间键值对数据的键空间(即前面所谓的“分组”),并将中间分割后的中间键值对发往对应的reducer,也即partitioner负责完成为一个中间键值对指派一个reducer。最简单的partitioner实现是将键的hash码对reducer进行取余计算,并将其发往余数对应编号的reducer,这可以尽力保证每个reducer得到的键值对数目大体上是相同的。不过,由于partitioner仅考虑键而不考虑“值”,因此,发往每个reducer的键值对在键数目上的近似未必意味着数据量的近似。
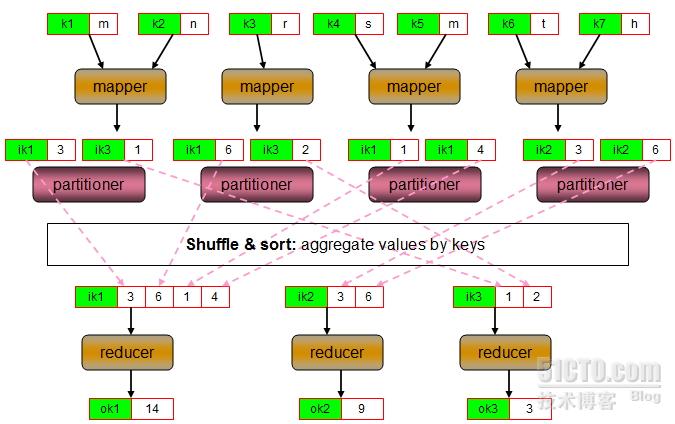
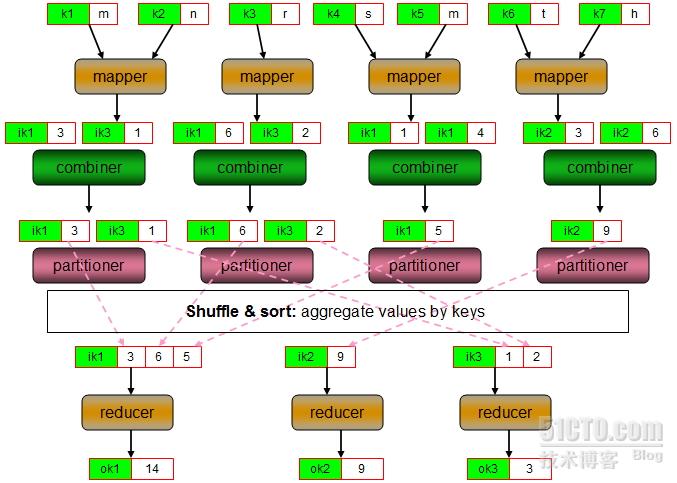
Combiner是MapReduce的一种优化机制,它的主要功能是在“shuffle and sort”之前先在本地将中间键值对进行聚合,以减少在网络上发送的中间键值对数据量。因此可以把combiner视作在“shuffle and sort”阶段之前对mapper的输出结果所进行聚合操作的“mini-reducer”。在实现中,各combiner之间的操作是隔离的,因此,它不会涉及到其它mapper的数据结果。需要注意的是,就算是某combiner可以有机会处理某键相关的所有中间数据,也不能将其视作reducer的替代品,因为combiner输出的键值对类型必须要与mapper输出的键值对类型相同。无论如何,combiner的恰当应用将有机会有效提高作业的性能。
思考:
1、对每一次的MapReduce作业来说,JobTracker可能会启动个数不同的mapper,且可能调度它们运行于不同的TaskTracker上,那么,这些个mapper如何获取要处理的数据(split),以及如何高效获取所需的数据?
2、如果存储了数据的设备发生了故障,MapReduce是否还能继续运行?如果能,如何进行?
参考文献:
Data-Intensive Text Processing with MapReduce
Hadoop in action
Hadoop in prictise
Hadoop Operations
Hadoop The Definitive Guide 3rd edtion
0 0
- Hadoop系列之五:MapReduce进阶(2)
- Hadoop系列之四:MapReduce进阶
- 【Hadoop入门学习系列之五】MapReduce 2.0编程实战
- Hadoop学习之MapReduce(五)
- Hadoop学习之MapReduce(五)
- hadoop-mapreduce进阶
- Hadoop系列之初识MapReduce(1)
- Hadoop系列五:Hadoop之Zookeeper篇
- Hadoop系列--Hadoop基本架构之MapReduce架构
- Hadoop系列--Hadoop核心之MapReduce的原理
- Hadoop MapReduce进阶 使用Chain
- Hadoop MapReduce进阶 使用Chain
- Hadoop MapReduce之ReduceTask任务执行(五)
- hadoop 自学指南五之MapReduce工作机制
- Hadoop之MapReduce输入与输出格式(五)
- hadoop学习系列1之第一个MAPREDUCE程序
- Hadoop之Mapreduce------>Mapreduce原理
- Hadoop连载系列之五:Hadoop命令行详解
- 《WebGL编程指南》学习——入门
- 关于node.js中的异步流程控制
- java企业考勤系统
- Sql Server 里的向上取整、向下取整、四舍五入取整的实例!
- 1.开发规范-- 常用的版本控制
- Hadoop系列之五:MapReduce进阶(2)
- MATLAB如何读取TXT中的数据?
- Android 打造任意层级树形控件 考验你的数据结构和设计
- 《WebGL编程指南》学习——绘制和变换三角形
- Linux下kill所有的Oracle远程连接
- android自定义倒计时控件示例
- poj Going from u to v or from v to u? 强联通缩点+拓扑排序(或搜索)
- android常见面试题与我自己的回答 (三)
- 游戏的字体制作


