机器学习笔记 线性判别分析(上)
来源:互联网 发布:淘宝美工面试常问问题 编辑:程序博客网 时间:2024/05/19 01:13
机器学习笔记 线性判别分析(上)
前面我们简要说明了贝叶斯学习的内容。由公式可以看出来,我们假定已经知道了似然概率的密度函数的信息,才能进行后验概率的预测。但有的时候,这些信息可能是不方便求出来的。因此,密度函数自身的估计问题成为了一个必须考虑的问题。
第一种思考的方法是跳出估计密度函数的问题,直接对样本集使用线性回归的方法。这样做虽然简单粗暴,但是仅仅适用于“连续型”分类的问题,或者说按照“自然顺序”分类。比如说小明今天晚上跪老婆的地方可能是{地毯,地板,搓衣板,钉板},可以看到不同的分类其实是对老婆怒气值这样一个连续函数的映射。但是大多数情况,分类的标签并不是按照自然顺序分类的,因此线性回归并不可行。当然,如果是二分类的问题情况会相对好一些,但是回归值并不是特别好解释,因此可以用一个sigmoid函数将R映射到(0,1)上,回归值自然地能够表示属于此分类的概率。这也就是logistic模型的主要内容。
第二种思考的方式是将高斯分布作为分类器概率密度函数的模型。
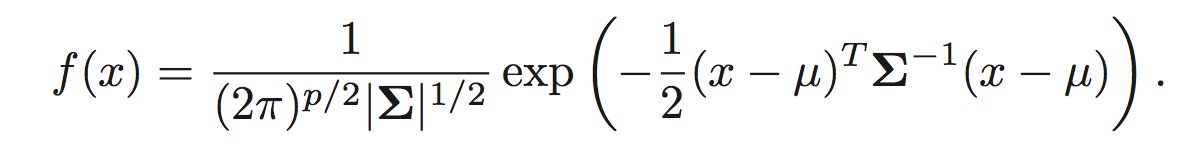
其中均值是μ,协方差矩阵是Σ 。
将密度函数带入贝叶斯分类器,取对数将相同的的值删去,便可得到判别函数的形式
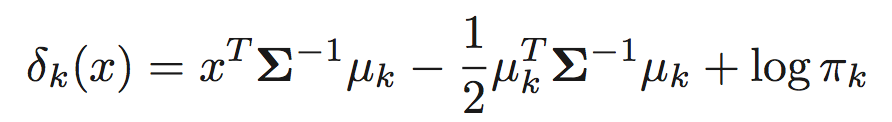
在这里,全部类的协方差矩阵的最大似然估计是类内样本的协方差矩阵汇集而成。
这样的方法叫做线性判别分析,也就是(LDA)。但实际上,我们可以不用估计全部类的协方差矩阵,直接将类内样本的协方差矩阵带入。那么判别函数即变为
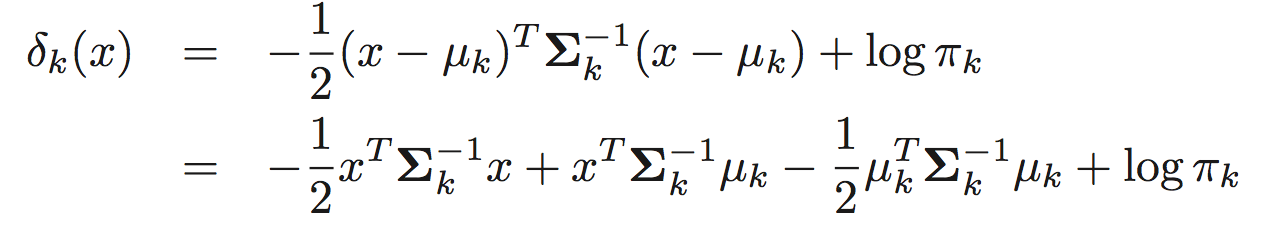
这是一个关于x的二次函数,因此也叫二次判别分析(QDA)。
QDA和LDA之间的关系是一个典型的bias-variance trade-off ,也就是方差和偏差的取舍。这是机器学习里面一个核心的问题。简单来说,机器学习模型的预测值和真实值之间的差异可以分解为方差和偏差这两个此消彼长的量的综合(再加上一个不可约的误差,在此不考虑)。通俗来说,高方差低误差的模型意味着过于灵敏,当需要预测的真实函数并没有变化,而只是使用了不同的样本,就能够使预测值产生较大的变化。反之,高误差低方差意味着过于迟钝,即使真实的函数发生变化,依然不会使预测值改变。因此在其中如何取舍,就成了一个很重要的问题。
很容易可以看出,LDA相对方差更低,而QDA相对误差更低。因此,在样本集比较少,对协方差矩阵很难估计准确时,采用LDA更加合适。而当样本集很大,或者类间协方差矩阵差异比较大的时候,采用QDA更加合适。
- 机器学习笔记 线性判别分析(上)
- 机器学习笔记 线性判别分析(中)
- 机器学习笔记 线性判别分析(中)
- 机器学习笔记(VIII)线性模型(IV)线性判别分析(LDA)
- 机器学习:线性判别分析LDA
- 线性判别分析(LDA)学习笔记
- 【机器学习-斯坦福】学习笔记18——线性判别分析(Linear Discriminant Analysis)(一)
- 【机器学习-斯坦福】学习笔记19——线性判别分析(Linear Discriminant Analysis)(二)
- 机器学习入门学习笔记:(2.4)线性判别分析理论推导
- 机器学习-线性判别分析(LDA), 主成分分析(PCA)
- 机器学习: Linear Discriminant Analysis 线性判别分析
- 机器学习算法03-线性判别分析LDA
- 【机器学习-西瓜书】三、逻辑回归(LR);线性判别分析(LDA)
- 机器学习中的数学——主成分分析(PCA)、线性判别分析(LDA)
- leftnoteasy:机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)
- 机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)
- 机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)
- 机器学习中的数学(4)-线性判别分析(LDA), 主成分分析(PCA)
- HDU 1213
- Android 学习笔记8——传感器使用
- 机器学习笔记 线性判别分析(中)
- LINGO中的集
- Leetcode Word Search
- 机器学习笔记 线性判别分析(上)
- 1042. 字符统计(20)
- java中用文件流分割文件,用于将大文件分割成多个小文件,合并文件待续
- 理解memcached的内存存储
- 矩形面积并、矩形面积交、矩形周长并(线段树、扫描线总结)
- 每个程序员都应该了解的 CPU 高速缓存(一)
- loadView ViewDidLoad ViewDidUnLoad 个方法的关系
- 1043. 输出PATest(20)
- python中的range()函数详解


